
ローカルLLMとは?おすすめモデルや簡単な作り方を紹介

ローカルLLMって何?LLMとどう違うの?
自分のパソコンでも動かせるの?どのくらいのスペックが必要?
実際にどうやって始めればいいの?設定とか難しそう…
近年、ChatGPTやGeminiなどの生成AIが普及し、ビジネスでの需要も高まっています。
いっぽう、外部のAIサービスを利用するうえでは、セキュリティやコストの面で課題も少なくありません。その解決策として注目を集めているのが、手元のパソコンなどで動かせる「ローカルLLM」です。
ローカルLLMについて興味はあるものの、クラウド型の生成AIと何が違うのか、どのように構築すればいいのかなど疑問を抱える人も多いですよね。
そこで、この記事ではローカルLLMの基本から作り方、自分の環境に合ったおすすめモデルまで詳しく解説します。メリットや使い勝手を高める方法も紹介するので、ぜひ参考にしてください。
- ローカルLLMは手元のPCで動く言語モデル
- 高性能なPCスペック(特にVRAM)が必要
- 無料ツールを使えば専門知識なしで構築可能
『ClaudeCodeに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- ClaudeCodeに作業や仕事を任せる方法
- ClaudeCodeを使いこなすたった1つのコツ
- 業務効率化や収入獲得に活かすClaudeCodeの実演
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。この時間が、あなたを変える大きなきっかけになりますよ。
ローカルLLMとは?

ローカルLLMとは、個人のパソコンや企業のサーバーで直接動かせるLLM(Large Language Model:大規模言語モデル)のことです。インターネットを経由せず、手元の環境だけでAIとの対話を完結させられます。
まずは、前提知識として欠かせないLLMの基礎知識や、クラウド型LLMとの違いについて見ていきましょう。
それぞれ詳しく解説していきます。
LLMとは
LLM(大規模言語モデル)とは、膨大なテキストデータからの学習により、人間のように自然な文章の生成能力を身につけたAIモデル(AIの頭脳)です。
ChatGPTやGeminiなどのテキスト生成AIは、内部で必ず「LLM(大規模言語モデル)」が稼働しています。このLLMがユーザーのプロンプト(指示文)を瞬時に解釈し、意図に即したテキストを生成する仕組みです。
これまでは、大手IT企業が提供するサービスを介した「クラウド型LLM」を利用するのが主流でした。LLMの構築には膨大な計算リソースや環境の確保が不可欠であり、自社での独自開発はハードルが高かったためです。
そして、この常識を覆したのが、個人や企業の環境で動かせるローカルLLMです。なお、LLMの基本的な仕組みや種類について詳しく知りたい人は、次の記事を参考にしてください。

クラウド型LLMとの違い
ローカルLLMとクラウド型LLMの大きな違いは「AIモデル(AIの頭脳)がある場所」です。
ChatGPTなどのクラウド型LLMは、AIモデルが外部のサーバー内にあります。そのため、インターネット経由で外部のサーバーにリクエスト(要求)を送り、その結果を受け取る流れとなります。
一方、ローカルLLMは、自分のパソコンや自社のサーバー内にAIモデルがあります。すべての処理を同じ環境内で完結できるため、外部との通信が発生しません。
こうした仕組みの違いが、ローカルLLMに後述する多くのメリットをもたらすのです。
ローカルLLMを導入・構築する4つのメリット

ローカルLLMには、クラウド型LLMにはない独自の強みがあります。ここからは、ローカルLLM導入による主なメリットを4つに分けて見ていきましょう。
AI活用にともなうリスクを低減できる
クラウド型LLMからローカルLLMに移行することで、AI活用にともなうリスクを低減できます。
クラウド型LLMを使う場合、送信したプロンプトは外部のサーバーに格納されます。個人や企業のデータを外部に送る以上、一定のリスクは避けられません。
その点、ローカルLLMは外部サーバーとの通信が不要なため、個人情報や機密情報を外部へ送らずに済みます。社外秘のデータや公開前のアイデアを入力しても、外部で意図せず情報が流出する心配はありません。
もちろん個人・企業がデータを自己管理する必要はあるものの、格段に不安は減るでしょう。
独自用途のAIシステムを構築できる
ローカルLLMは、個人や企業が独自のAIシステムを構築するのにも適しています。LLMを含めたすべての構成要素が手元に存在するため、外部サービスのルール・制約に縛られない柔軟なカスタマイズが可能です。
たとえば、特定の専門用語を優先的に理解させたり、特定の業務フローに沿った回答を出力させたりできます。また、環境を整えればテキストだけでなく、画像生成AIの構築などにも応用が利きます。
独自用途のAIシステムを構築したい場合、クラウドサービスにはないローカルLLMの柔軟性は大きな魅力です。
オフラインで安定的にAI機能を使える
ローカルLLMを構築すれば、インターネット接続がないオフライン環境でもAI機能を安定して使えます。
外部にAIモデルがあるクラウド型LLMの利用は、インターネット接続が前提です。ネットワークの接続状況やサービス側の障害によっては、作業が中断される恐れがあります。
その点ローカルLLMなら、AIとのやり取りに外部との通信が必要ありません。そのため通信環境を気にせず、必要なときにAIのサポートを受けられます。
外出先や電波の届かない場所でも、普段と変わらずAI機能を使えるため安心です。
AI機能の内製化でAPIコストを抑えられる
ローカルLLMを導入すればAI機能を内製化でき、APIコストを大幅に抑えられます。
自社システムにAI機能を組み込む場合は、API(ソフトウェア同士をつなぐ窓口)を介してクラウド型LLMを利用するのが一般的です。利用量に応じて課金されるため、アクセス数や処理回数が増えるほどコストも膨らみます。
しかしローカルLLMでは、そもそも外部との通信が不要なため、こうしたAPIによる課金が発生しません。大量のデータを処理したり頻繁に利用したりする場合でも、料金がかさむのを気にせずに済みます。
環境構築の初期投資は必要ですが、長期的にAI機能を利用するほどコスト面での恩恵は大きくなるでしょう。
ローカルLLMを導入する際の注意点

メリットの多いローカルLLMですが、導入する前に知っておくべき注意点もあります。スムーズに環境を整えるためにも、あらかじめ3つの注意点をおさえておきましょう。
高性能なPCスペックが要求される
ローカルLLMを快適に動かすためには、使用するパソコンに一定以上のスペックが求められます。ローカルLLMは手軽に導入しやすくなっているものの、それなりのパソコンを用意する必要があることを知っておきましょう。
2026年3月時点の一般的な目安として、パソコンに搭載された要素の役割とスペックの目安を下表にまとめました。
| 要素 | 役割 | 最低限動作の目安 | 快適運用の目安 |
|---|---|---|---|
| CPU | システム全体の制御やAIモデルを動かすための 前準備・データ処理を担当する。 | Core i7 /Ryzen 7 | Core i9/Ryzen 9 (16コア以上) |
| メモリ | AIモデルのデータを一時的に展開しておく「作業机」。 容量が不足すると動作が重くなる。 | 16GB | 32GB必須、 64GB推奨 |
| GPU | 膨大なAIの計算処理を高速でこなす要。 搭載されたVRAM容量が動かせるAIの賢さに直結する。 | RTX 3060 (8GB VRAM) | RTX 4070/4080 (12GB VRAM以上) |
| ストレージ | 数GBから数十GBあるAIモデルのデータを保存する「本棚」。 高速な読み込みが求められる。 | SSD 500GB | 1TB NVMe SSD (モデル複数保管用) |
特に重要なのが、GPUに搭載された「VRAM(ビデオメモリ)」の容量です。VRAMはLLMにおいて、数GB以上あるAIモデルのデータを丸ごと読み込み、高速で計算するための専用スペースとしての役割を果たしてくれます。
VRAMの容量が足りないと、AIの動作が遅くなったり、途中で停止したりする恐れがあります。後述するモデル選びでも「どの程度のVRAMで動かせるか」は重要な判断基準になる点をおさえておきましょう。
技術的な知識が求められる場合がある
最近は便利な導入ツールが登場し、ローカルLLMを動かし始めること自体は簡単になりました。しかし、用途を広げたりトラブルに対処したりするためには、一定の技術的な知識が必要です。
たとえば、独自のデータを読み込ませる仕組み(後述のRAG)を構築したり、自社システムと連携させたりする場面では専門知識が問われます。
簡単なチャットのみなら、それほど知識は求められません。しかし、より高度な使い方を目指す場合は、完全初心者だと知識不足でつまずく場合がある点に注意しましょう。
自らで運用やアップデートを行う必要がある
ローカルLLMを導入する場合、自らで運用やアップデートを行う必要があります。外部の企業がAIモデルを管理してくれるクラウド型LLMとは違い、手元のAIモデルを自らで管理しなければなりません。
クラウド型LLMでは、サービス提供者が継続的に性能改善やバグ修正を行い、モデルを最新の状態に保ってくれます。トラブルが発生した際にも、公式のサポート窓口へ問い合わせて対応を任せられるでしょう。
しかしローカルLLMでは、利用者が自主的にアップデートを確認し、手動で適用しなければならない場合があります。トラブルが発生した際にも、原因を自らで調べて解決することが求められます。
そのため、クラウド型LLMのように、待っていれば勝手に最新の賢いAIへ進化するわけではないことを知っておきましょう。
PCスペックと用途で選ぶ!ローカルLLMのおすすめモデル

ローカルLLMを構築する場合、提供されているAIモデルを自前の環境にダウンロードして使うのが一般的です。ローカル環境で動かせるAIモデルには多くの種類があり、どれを選ぶかでAIの賢さや動作の軽さが変わります。
ここからは、PCスペック(特にVRAM容量)や用途ごとにローカルLLMのおすすめモデルを紹介します。
それぞれ詳しく解説していきます。
【軽量・VRAM 8GB目安】一般的な個人PCでもサクサク動くモデル
VRAMが8GB前後の一般的なゲーミングPCなら、軽量なモデルから試してみましょう。代表的なモデルとして、次のようなものが挙げられます。
こうしたモデルは要求スペックが低く、ノートパソコンでも比較的スムーズに動作します。ローカルLLMの使い勝手をとりあえず体験してみたい初心者におすすめです。
【中量・VRAM 12GB目安】実用レベルの精度を誇る高バランスモデル
VRAMが12GB以上ある環境なら、実用的な精度を持つ中量クラスのモデルが選択肢に入ります。代表的なモデルは、次のとおりです。
こうしたモデルは複雑な指示への対応力に優れており、プログラミングのコード生成や論理的なデータ処理で強みを発揮します。業務の効率化や本格的な個人開発など、実務レベルでしっかり使いたい人におすすめです。
【日本語特化・VRAM 8GB〜】自然な文章生成に優れた国産モデル
より自然な日本語の表現にこだわりたい人には、国内で開発された特化型モデルがおすすめです。代表的なモデルとして、次のようなものが挙げられます。
こうしたモデルは日本のデータに強く、海外製のAIに多い不自然な翻訳調の文章を避け、スムーズな文章を作ってくれます。VRAMが8~16GB程度あれば十分動かせるため、執筆を専門とする仕事で重宝するでしょう。
【専門知識不要】ローカルLLM環境の作り方・3ステップ

ここからは、実際にローカルLLMを導入する手順を解説します。現在は複雑な設定がいらない無料ツールとして「LM Studio」や「Ollama」を利用する方法が主流です。
直感的な画面操作を好むならLM Studio、軽快なコマンド操作を好むならOllamaを選びましょう。ここでは、誰でも簡単に構築できる共通の3ステップを、LM Studioを使う前提で紹介します。
- ステップ1:実行環境(ツール)をインストールする
- ステップ2:利用したいLLMモデルをダウンロードする
- ステップ3:プロンプトを入力してチャットを開始する
ステップ1:実行環境(ツール)をインストールする
まずは、パソコンの中でローカルLLMを動かすための土台となるツールをインストールしましょう。
LM Studioの公式サイトへアクセスし、お使いのOSに合ったインストーラーをダウンロードしてください。画像は、Windowsのx86でインストールする場合の例です。
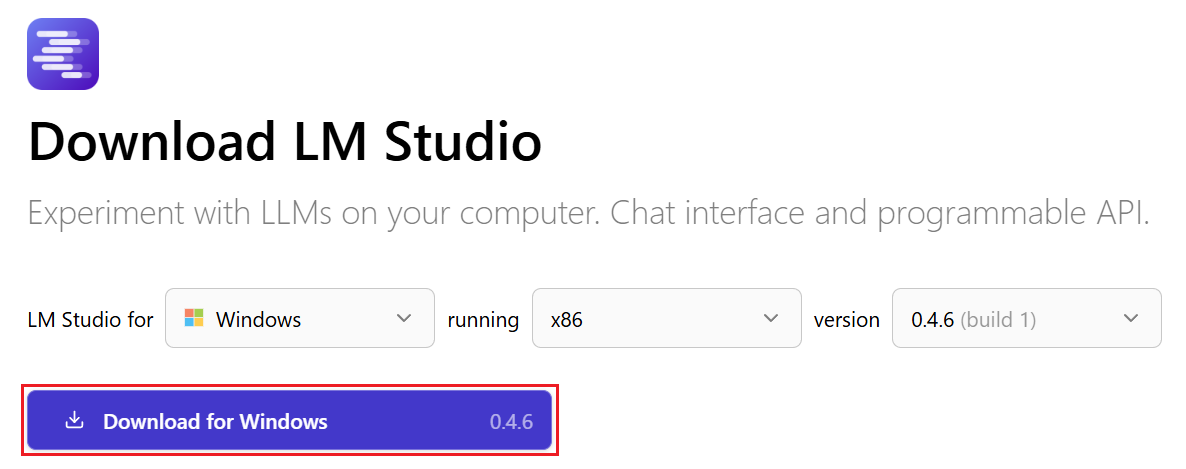
ダウンロードしたファイルを開き、画面の案内に沿ってインストールを進めるだけで準備は完了です。
ステップ2:利用したいLLMモデルをダウンロードする
ツールの準備ができたら、AIの頭脳となるLLMモデルをダウンロードしましょう。LM Studioを開き「Get Started」をクリックしてください。
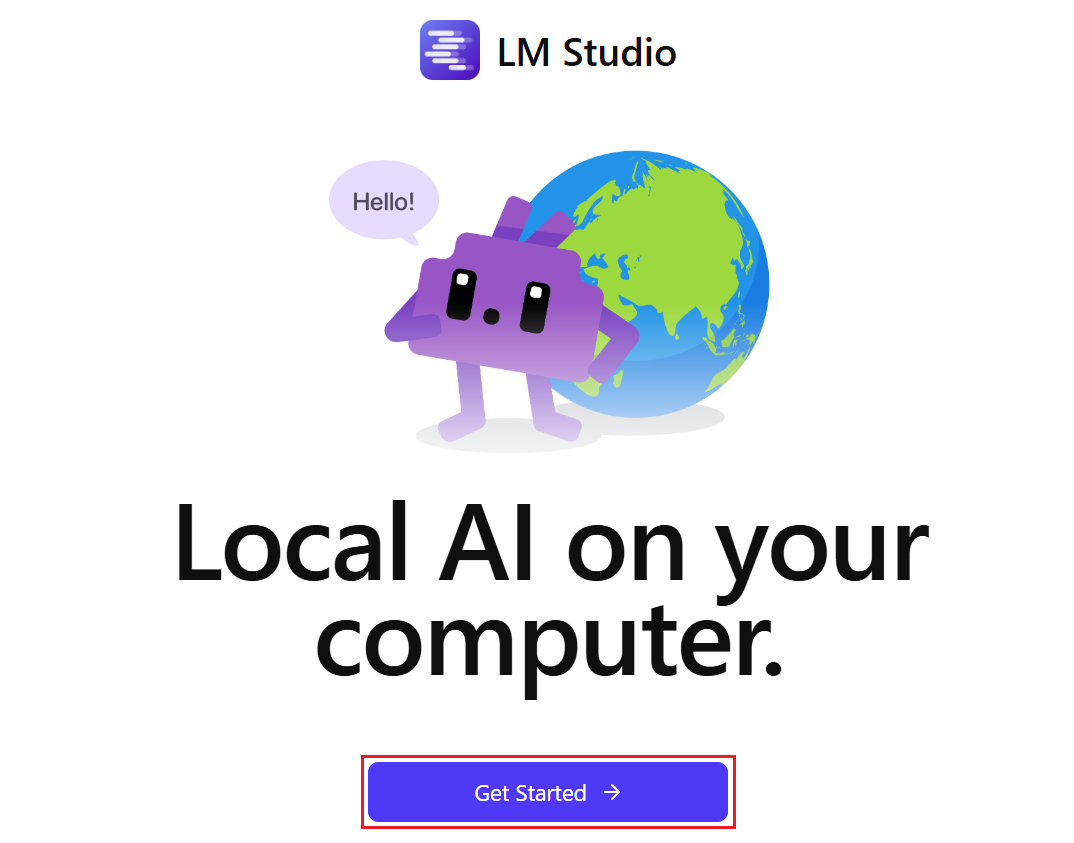
初回は、お試しのモデルとしてGemma 3 4Bのダウンロードを促されます。「Download gemma-3-4b」をクリックし、ダウンロード完了までしばらく待ちましょう。
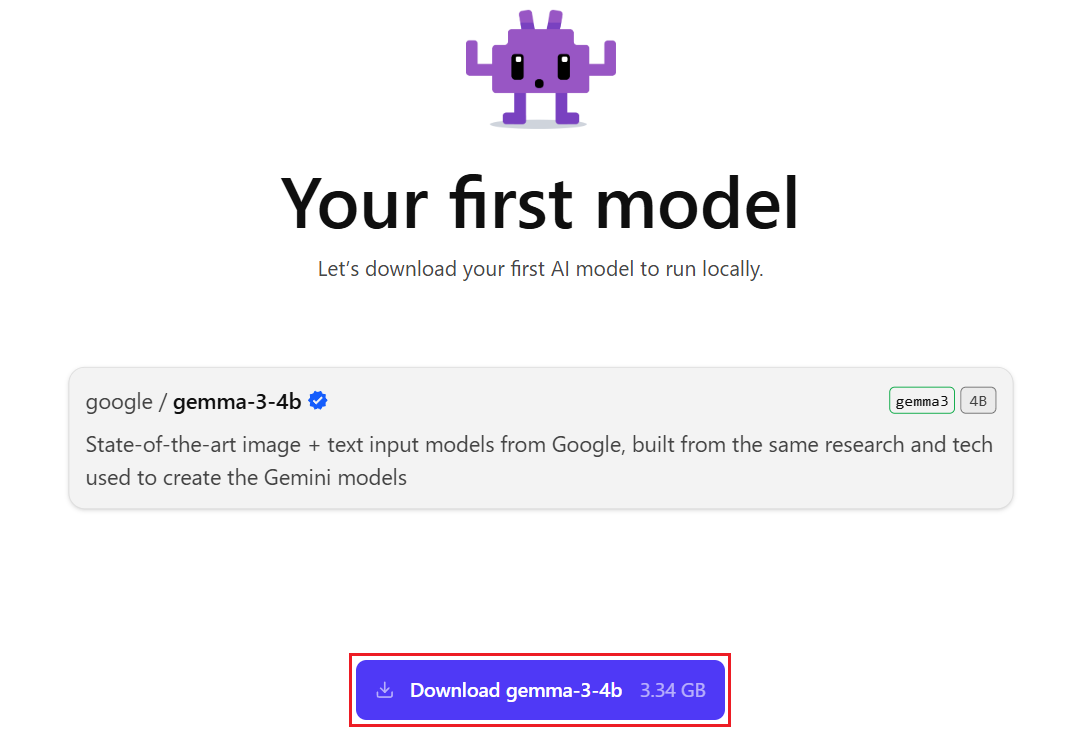
ダウンロード後は、動作に関する初期設定の確認画面が表示されます。最初は細かく調整しなくても問題ないため、そのまま「Continue」を押して進めて構いません。
その後、LM Studioのメイン画面が表示されれば、モデルの準備は完了です。ここまでできれば、ローカルLLMを実際に動かす準備が整っています。
なお特定のモデルを検索してダウンロードしたい場合は、画面左側のメニューにある虫眼鏡アイコンをクリックし、上部の検索窓からモデル名を入力して探してみてください。
ステップ3:プロンプトを入力してチャットを開始する
モデルの準備が終われば、あとはChatGPTなどの生成AIと同じ感覚でチャットを開始できます。まずは、画面中央にある「New chat」というボタンをクリックしてください。
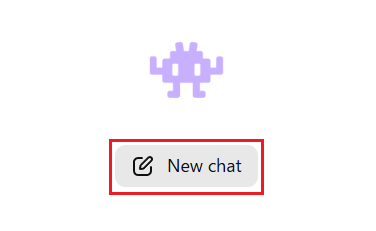
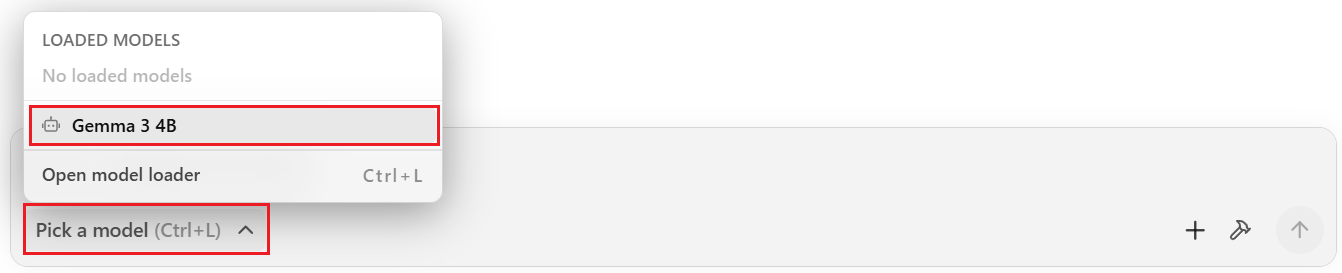
専用のチャット画面が開いたら、下部の入力欄にある「Pick a model」から、先ほどダウンロードした「Gemma 3 4B」を選択しましょう。モデルの設定画面が表示されますが「Load Model」でOKです。
そして、プロンプト(質問や指示)を入力して送信ボタンまたはEnterキーを押せば、AIと対話が行えます。画像は「What is AI?」というプロンプトを送っている例です。

なお、回答が生成されるスピードや文章の精度は、PCスペックやモデル性能に大きく依存します。
もし動作が極端に重かったり、意味不明な回答が返ってきたりする場合は、パソコンのスペックに対してモデルが重すぎるサインです。その際は、より軽量なモデルをダウンロードして再度試してみてください。
オフライン環境でも、AIからの回答が出力されることを確認しましょう。
構築したローカルLLMの使い勝手を高める方法

ローカル環境にLLMを用意できたら、単なるチャットツールを超えた活用にも挑戦してみましょう。ここでは、ローカルLLMの価値をさらに高める応用的な使い方を紹介します。
独自のデータを読み込ませる「RAG」の構築
ローカルLLMの強みを活かすなら、独自の知識を持たせる「RAG」の構築がおすすめです。パソコン内のPDF資料や過去のコードなどを読み込ませ、それにもとづいた回答を生成してくれます。
企業の機密データや個人的なメモを外部に出すことなく、自分専用のAIアシスタントに育てられます。社内ルールの確認や、大量の資料からの情報探しを大きく効率化できるでしょう。
プログラム連携による自作アプリへの組み込み
プログラミングの知識があれば、ローカルLLMを自作のアプリに組み込むことも可能です。OllamaなどのツールはAPIとして機能するため、PythonやPHPといった言語から直接AIを呼び出せます。
普段使っているツールと連携させたり、オリジナルの自動化プログラムを作ったりと、活用の幅が広がります。自分だけのAIアプリを開発してみたい技術者にとって、魅力的な選択肢です。
まとめ
今回は、オフライン環境で安全にAIを動かせるローカルLLMについて詳しく解説しました。
ローカルLLMは、情報漏えいのリスクを減らしつつ、好みに合わせたカスタマイズができる便利なAIです。導入には一定のPCスペックが必要ですが、無料ツールを使えば手順自体は決して難しくありません。
まずは自分のパソコン環境を確認し、VRAMの容量に合った手頃なモデルから試してみましょう。安全で自由度の高いAI環境を手に入れれば、作業の効率化や新しいアイデアの発見に大きく役立つはずです。


