
OpenAIo1(ChatGPT)とは?次世代AIモデルの使い方と活用法

AI技術は急速に進化しており、その中でもOpenAIの次世代モデル「o1(ChatGPT)」は特に注目を集めています。従来のChatGPTと比べて推論力や精度が大幅に向上しており、複雑な課題解決や高度な情報処理を可能にしています。
しかし、ChatGPTo1の活用に興味がある方の中には、以下のような疑問・懸念をお持ちの方も多いのではないでしょうか。
ChatGPTo1をについて知りたい
ChatGPTo1の料金体系は?
実際に活用できる具体的な事例について知りたい
そこでこの記事では、ChatGPTo1の導入や活用に興味がある方に向けて以下の内容を解説します。
この記事では、ChatGPTo1の基礎知識から実践的な活用法、さらに効率的に使いこなすための工夫までを詳しく解説します。
ぜひ参考にしてください。
ChatGPTの特徴をより詳しく知りたい人は、次の記事を参考にしてください。

『ClaudeCodeに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- ClaudeCodeに作業や仕事を任せる方法
- ClaudeCodeを使いこなすたった1つのコツ
- 業務効率化や収入獲得に活かすClaudeCodeの実演
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。この時間が、あなたを変える大きなきっかけになりますよ。
OpenAIo1とは?
OpenAIo1は、回答を出す前により長く「考える」よう設計された次世代のAIモデル群です。
大規模な強化学習によって“推論の連鎖”を身につけ、複雑な課題を段階的に解く推論特化型LLMとして、科学・数学・コーディングなどの難問で従来世代を上回る性能を示します。さらに、推論に使う時間を増やすほど精度が向上する特性が報告され、難問ほど思考を深められます。
学習スケーリングの制約も従来の事前学習とは異なるとされ、推論の質を高める方向で改良が進んでいます。
初期版のo1-preview/o1-miniに始まり改良が続いており、現在はChatGPTPlusやAPIから利用可能です。研究・製品更新や安全性評価(SystemCard)はo1ハブでまとめて公開されています。
OpenAIo1の主な特徴

OpenAIo1は、その名のとおり従来モデルとは一線を画す「考えてから答える」設計を特長とする新世代の大規模言語モデル(LLM)です。内部で「チェイン・オブ・ソート(思考の連鎖)」を生成し、複雑な問題を段階的に解き進めることが可能です。
科学・数学・コーディングなど推論が問われる領域で、人間の専門家や従来モデルを超える性能を発揮し、安全性にも配慮された設計となっています。
本セクションでは、そんなo1の主要な特性を、より深く掘り下げて解説します。
思考過程を重視した推論能力

o1の最も注目すべき点は、回答に先立って“内部で考える時間”を持たせる設計です。
ユーザーの問いに対して即答するのではなく、内部で長めの「思考の連鎖(chain of thought)」を構築し、段階的に問題を分解して検討することで、複雑な課題に高い精度で対応できます。
推論に使う計算量(テスト時の計算)を増やせば、その精度が安定して向上するというスケーリング特性も確認されており、これは従来の単に大きなモデルに学習量を積む設計とは異なるアプローチといえます。
o1はこうした思考重視の仕組みにより、「より考えることで、より正確な答えを導く」ニューラルモデルの新しい地平を切り拓いています。
高精度な専門的知識の対応
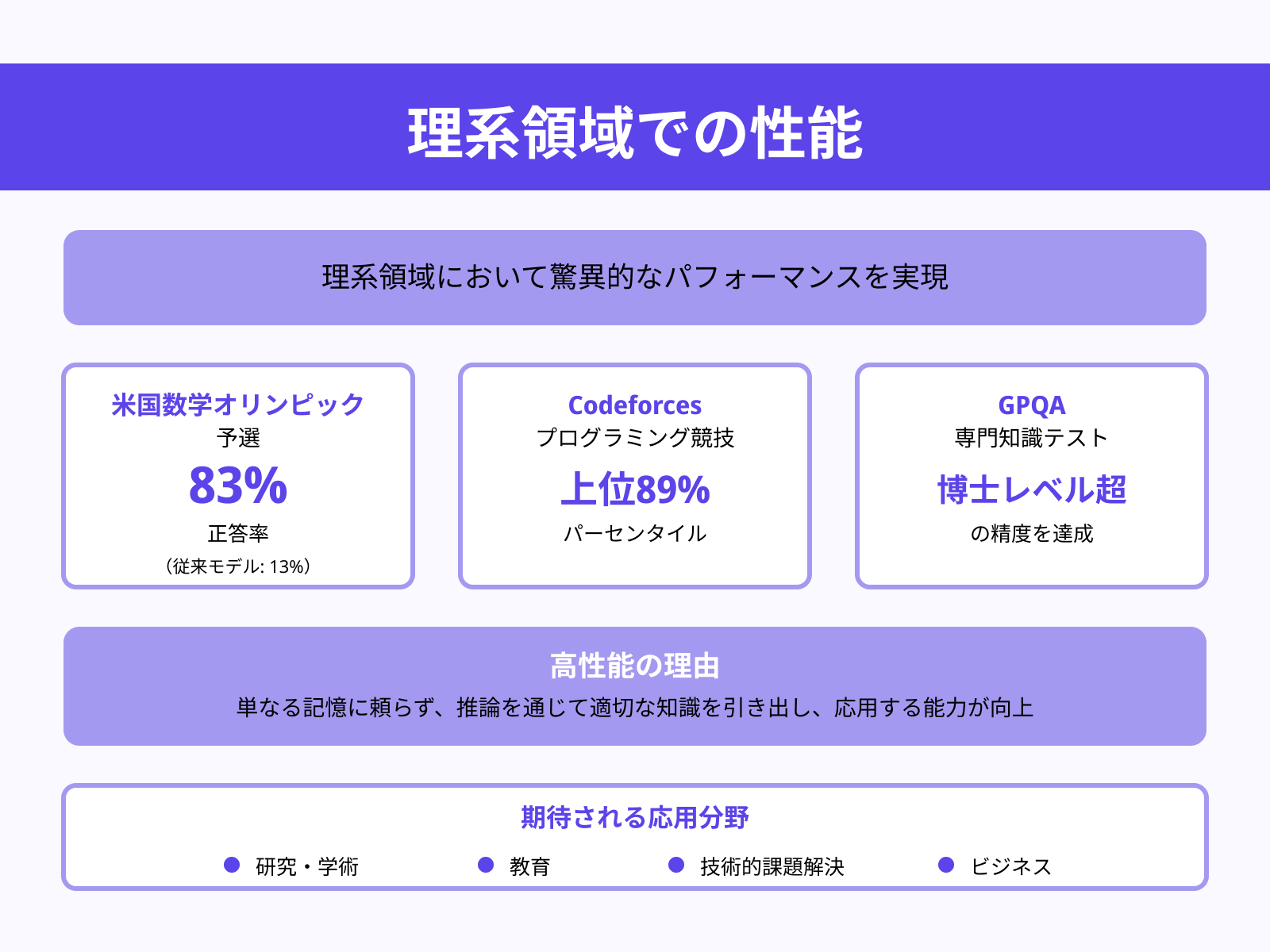
o1は特に理系領域において驚異的なパフォーマンスを示しています。
例えば、米国数学オリンピック予選で83%の正答率を達成(従来モデルの13%と比較して大幅な向上)、Codeforcesでは上位89パーセンタイル、さらにGPQAでは博士レベルの精度を越える結果を出しています。これらは単なる「記憶している」知識に頼るのではなく、推論を通じて適切な知識を引き出し、応用する能力が高められた成果とされています。
こうした高精度な専門知識の働きは、研究・学術・教育分野に加え、技術的・ビジネス的な課題解決にも大きな応用が期待されます。
強化学習による訓練

o1は単なる事前学習モデルにとどまらず、大規模な強化学習を活用して訓練されています。その目的は「どう考えるか」といった思考プロセス自体を洗練させ、高度な推論や柔軟な判断力の獲得にあります。
モデルは単に正解を出すのではなく、誤りを自己検出して自己修正したり、異なるアプローチを試したりする能力を習得しています。
さらにOpenAIは、安全性を高めるために、「熟慮的アラインメント(deliberativealignment)」という手法を導入しました。これは、モデルが回答前にまず安全に関する仕様やポリシーについて考慮し、それに基づいて応答を生成する訓練パラダイムで、高い安全性と堅牢性を実現しています。
実際、o1はポリシー順守の精度や未知の状況への一般化能力といった安全性ベンチマークで、従来を上回るパフォーマンスを示しています。
高度な自然言語理解

o1は単に質問応答能力に優れているだけではありません。
複数の条件や前提が絡んだ複雑な指示、微妙な語感や暗黙の意図を含む文章も正確に理解し、論理的に整合のとれた応答へと導く自然言語理解においても高い能力を発揮します。
この高い理解力を背景に、o1はGPT‑4oを上回る精度をベンチマークで示し、言語理解と推論の両立を実現しています。さらに、o3シリーズなどマルチモーダル対応への後継モデルへと引き継がれており、図表や画像といった視覚情報も理解し推論に統合する能力を備えています。
言葉だけでなく文脈・形式情報を通じて“意味を捉え、推理する”力を深化させたモデルです。
高速かつ効率的な推論処理

o1ファミリーには、応答速度とコスト効率をより重視したバリエーション「o1‑mini」が存在します。
このモデルはSTEM(数学・コーディングなど)領域でo1に匹敵する推論力を維持しつつ、最大約80%のコスト削減を実現します。特にAIMEやCodeforcesといった評価ベンチマークでは、o1‑miniは高得点を記録し、優れたコスト対効果を証明しています。
また、「じっくり考えるモード(高精度)」と「高速応答モード(スピード重視)」の使い分けが可能であり、タスクや状況に応じた柔軟な運用が可能です。さらに、推論時により多くの計算リソースを投入することで、精度だけでなくロバスト性(たとえば対抗的攻撃への耐性)も高められるという研究成果も報告されています。
OpenAIo1の活用シーン

OpenAIo1は「考えてから応答する」という設計により、高度な推論力が強化されたAIです。複雑な問題を段階的に処理する能力に優れ、科学研究やコーディング・ビジネス分析など、多様な現場で活用可能です。
以下では、典型的な応用領域を取り上げ、その具体的な活用価値をご紹介します。
科学研究と学術分野

o1は「答える前に考える」設計により、研究現場で頻出する多段の推論や前提整理に強みを発揮します。
評価では、米国の競技数学AIMEでGPT-4oが平均12%に留まる一方、o1は単一サンプルで74%、合議(多数決)で83%に達し、再ランキング込みでは13.9/15点(全国上位500人相当)という結果が報告されています。さらにPhDレベルの科学知識を問うGPQADiamondで人間専門家を上回り、Codeforcesでも人間上位帯の成績を示しました。
これらは、強化学習で鍛えられた段階的思考が、仮説生成→検証方針の比較→反証の試行といった研究プロセスを下支えすることを示唆します。文献レビューや実験計画の妥当性チェック、解析コード雛形の作成など、“知的ワークフローの骨組み化”に有効です。
プログラミングとソフトウェア開発

開発工程全体で、要件の言語化、設計案の比較、アルゴリズム選定、実装・デバッグ、テスト生成、レビュー補助まで、o1は推論を軸にした支援が可能です。
評価では、Codeforcesのシミュレーションでo1が高いElo(人間上位帯)を示し、コーディングの正確化や難所の切り分けに寄与しました。コストや待ち時間がシビアな現場では、小型で最大80%安価かつ低レイテンシのo1-miniを選ぶ運用も現実的です。
用途に応じて「長考で精度重視」か「高速応答で回転重視」を切り替えられます。実務では、既存CIや静的解析と組み合わせて、補助的に活用しつつ最終判断を人間が担う設計が望まれます。
教育と学習支援

o1は、学習者の誤解やつまずき箇所を推論で見立て、課題を段階化して解説する対話型チューターとして機能します。抽象概念の橋渡しに比喩や別解を提示し、誤答の原因を言語化して再挑戦へ導く、といった“足場かけ”がしやすいのが特長です。
AIME・MMLUなど推論系ベンチマークで示された強みは、条件の多い課題でも前提→方針→検証の順で筋道立てて学び直す設計に適合します。
導入にあたっては、学習目標に沿ったプロンプト設計、出典の併記、評価基準の明確化を行い、教員が最終的な正誤判定と倫理面の監督を担う体制が不可欠です。
ビジネス分析と戦略的意思決定

不確実性や制約の多い意思決定では、前提・仮説・KPI・リスクの“論点ツリー化”が鍵になります。o1は、シナリオ比較やトレードオフ整理、反証可能性の検討といった知的プロセスを段階的に支援し、戦略メモや意思決定資料の骨子化を加速します。
実例として、金融領域では投資家向け資料や8-K、表・グラフを含むモデルを読み込み、要点抽出や前提整合の確認を自動化して分析効率を高める活用が紹介されています。
運用上は、社内データの品質・出所を明記し、最終判断は人が行う、というガバナンス線引きを前提に段階思考の“補助輪”として組み込むのが最適です。
カスタマーサポート

CSでは、問い合わせの意図推定→関連ポリシー適用→解決手順の段階提示→ログ要約と、連続する判断が求められます。o1は安全ポリシーを文脈内で推論する設計(熟慮的アラインメント)により、規約や返金ルールなどルール依存の応対で一貫性を高めやすいのが利点です。
実務では、誤応答を防ぐためにガードレール(禁止アクションの明示、スーパーバイザへの自動エスカレーション、監査ログ)を併設し、難案件は人間が引き取る二段運用が現実的です。
意図の曖昧さや例外処理の多い現場ほど、段階思考の透明化とポリシー準拠のトレーサビリティが効果を発揮します。
法律と契約書の解析

契約・規約文書では、定義語の連関、準拠法や責任制限、損害賠償などの“落とし穴”を見落とさないための段階的読み解きが必要です。
o1は条項の構造化、改定差分の抽出、論点メモ化、代替条文案の比較といった分析を支援しうる一方で、法的助言の代替にはならない点が重要です。
OpenAIの利用ポリシーも、高リスク領域(法・医・金)では専門家レビューを前提とする旨を明記しています。導入時は、機密・秘匿情報の扱い、権限と監査の設計、最終判断の人間責任を制度として定義し、AIは「参照・下書き・比較」の補助に限定するのが安全です。
医療分野
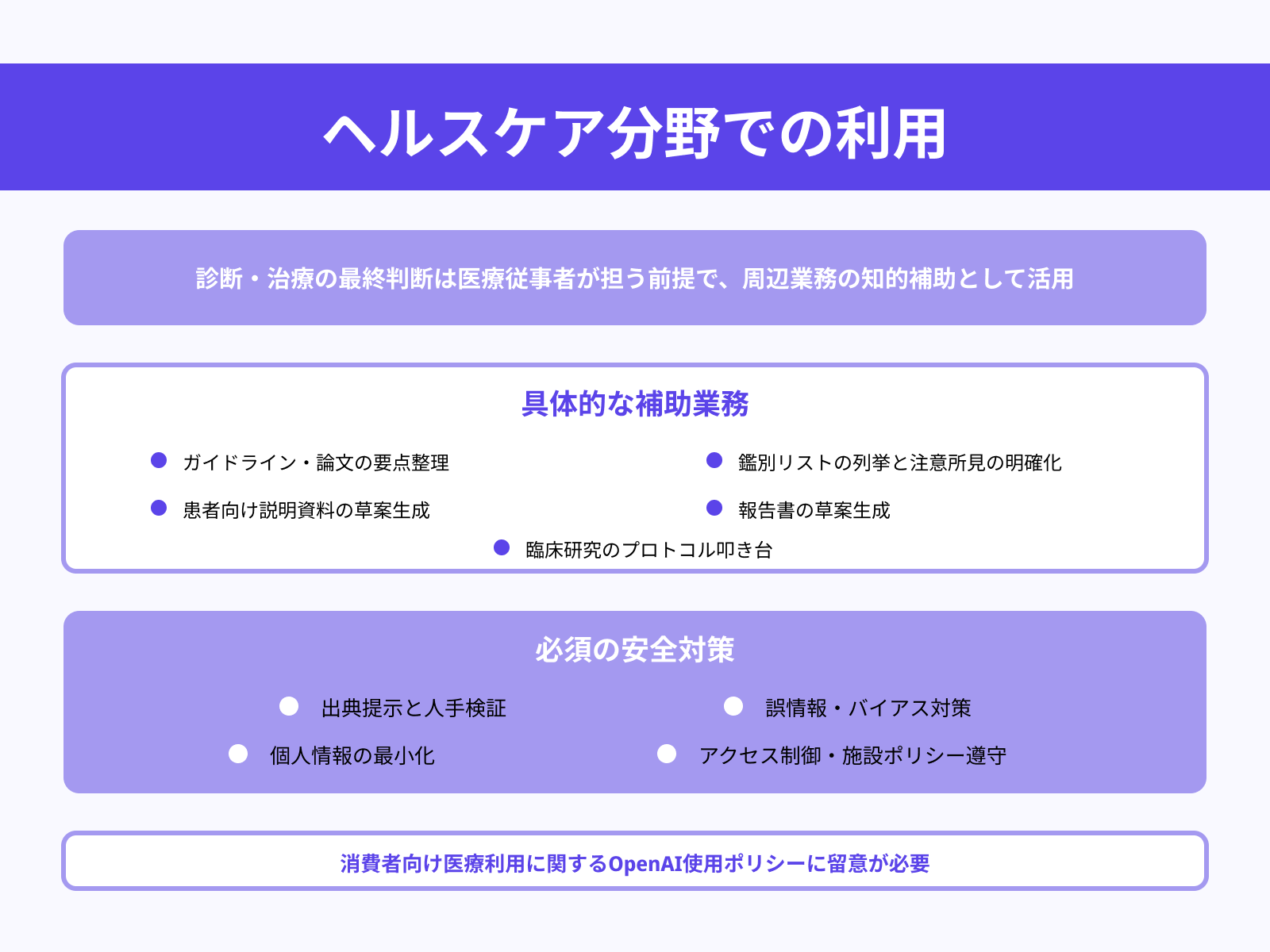
医療では、診断・治療の最終判断は医療従事者が担う前提で、o1は周辺業務の知的補助に向きます。
具体的には、ガイドライン・論文の要点整理、鑑別リストの列挙と注意所見の明確化、患者向け説明資料や報告書の草案生成、臨床研究のプロトコル叩き台などがあります。
熟慮的アラインメントに基づくポリシー推論は安全面の下支えになりますが、誤情報・バイアス対策として出典提示と人手検証、個人情報の最小化・アクセス制御、施設ポリシー遵守を徹底する必要があります。
消費者向け医療利用に関するOpenAIの使用ポリシーにも留意してください。
OpenAIo1の料金体系と利用制限

OpenAIo1の費用と制限は、大きく「ChatGPT(サブスク)」と「API(従量課金)」で考えるのが実務的です。o1はChatGPTとAPIの双方で提供されており、利用上限や機能対応は段階的に更新されます。
このセクションでは、OpenAIo1の料金体系と利用制限について、「ChatGPTPlusプランでの利用」「モデルの選択肢と制限」「API経由での利用」の3つの観点から解説します。
それぞれ、異なる用途や制約に応じた適切な使い方を理解するためのポイントです。
ChatGPTPlusプランでの利用

ChatGPTPlus(約20ドル/月)に加入すると、標準搭載されているGPT-4oに加え、次世代推論モデルであるo1系列のモデルを利用できるようになります。
具体的には、o1-previewやo1-miniといったモデルをモデル選択メニューから切り替えて使用可能です。
ただし、Plusプランでは無制限に利用できるわけではなく、使用回数や期間ごとに明確な制限が設定されています。たとえば、o1-previewは週50メッセージまで、o1-miniは1日50メッセージまでといった上限があり、一定以上利用すると再び制限解除されるまで待つ必要があります。
こうした制限が不便な場合は、上位プランであるChatGPTPro(月額200ドル)にアップグレードすることで、o1-proを含む全モデルを無制限で利用できるようになります。
ChatGPT Plusの特徴を詳しく知りたい人は、次の記事を参考にしてください。

モデルの選択肢と制限

o1シリーズには利用目的やリソースに応じた複数のバリエーションが用意されています。
軽量版のo1-miniは、応答速度が速く低コストでの利用が可能で、日常的な作業や短時間での検証に適しています。一方で、o1本体やo1-proは計算リソースを多く消費する代わりに、高度な推論や複雑な課題の解決に優れたパフォーマンスを発揮します。
そのため、利用者は用途に応じて「軽快さ重視」か「精度重視」かを選択できる柔軟性があります。
ただし、o1シリーズのモデルにはいくつかの制約も存在します。たとえば、コード実行ツールの非対応、system/developerメッセージの非対応といった点が公式に明示されており、従来のモデルで可能だった一部の拡張機能が使えない場合があります。
API経由での利用

ChatGPTのUIを介さずに利用したい開発者や企業向けには、OpenAIのAPI経由でo1シリーズを利用できる仕組みが提供されています。
API利用では従量課金制が採用されており、入出力トークン数に応じて料金が発生します。
たとえば、o1-previewは入力100万トークンあたり15ドル、出力100万トークンあたり60ドルと高めに設定されていますが、その分、高精度な推論力を活用できます。一方、軽量なo1-miniはコスト効率に優れており、入力100万トークンあたり0.15ドル、出力100万トークンあたり0.60ドルと約80%安価に利用可能です。
そのため、大量のリクエストやコスト制約があるプロジェクトではo1-miniが現実的な選択肢となります。
OpenAIo1利用上の注意点

OpenAI o1は高度な推論能力を備える一方で、安全かつ効果的な活用にはいくつか留意すべき点があります。
本セクションでは、「利用制限」「データプライバシーとセキュリティ」「モデルの限界」という視点から、o1利用時の注意点を整理します。
利用制限に注意する

OpenAIo1およびo1-miniは、その高い推論力を安定的に提供するため、利用回数に明確な制限が設けられています。
ChatGPTのPlusやTeamプランでは、o1は週50メッセージ、o1-miniは1日50メッセージという上限が設定されており、上限に達すると一時的にモデル選択メニューから利用できなくなります。そのため、限られた利用枠をどのタスクに充てるかを計画的に考えることが重要です。
重要な検証や本番環境での利用を優先させ、軽微な実験や試行は他のモデルや代替手段で補う工夫が求められます。また、利用頻度が高いユーザーは、無制限で利用できる上位プラン(ChatGPTProなど)への切り替えも選択肢に含めるとよいでしょう。
データプライバシーとセキュリティを理解する

o1を安全に利用する上で欠かせないのが、データプライバシーとセキュリティの理解です。
OpenAIは業界標準の暗号化技術を導入しており、保存データにはAES-256、通信にはTLS1.2以上を採用しています。さらにエンタープライズ契約では、入力データを保持しない「ゼロ保持」設定など、組織の要件に応じた柔軟なポリシー設計が可能です。
しかしながら、絶対的な安全は存在しません。
2025年8月には、公開機能の設計不備により一部のユーザー対話が誤ってGoogle検索に表示されるという事故が発生しました。機能は直ちに撤回されましたが、予期せぬ形でプライベートな情報が外部に露出するリスクを示した事例といえます。
これを踏まえると、医療や法律、機密性の高いビジネス情報などは入力を避けるか、匿名化・加工した形で活用することが推奨されます。
モデルの限界を理解する

o1はチェイン・オブ・ソート推論を通して高度な思考力を発揮する一方で、いくつかの限界も報告されています。
まず、計算リソース要求が高く、他モデルより応答に時間がかかることがあります。さらに、約0.38%の回答においては、精度や自身の思考過程と矛盾する回答を返す可能性があります。
思考連鎖が不透明でユーザーに公開されないことや、それを試みる行為がアクセス制限の対象になることも報告されています。加えて、Appleの研究ではトレーニング時の類似データに依存した「再現思考」の傾向が示され、わずかな入力変化でも性能が揺らぐことが確認されました。
このように、精度の限界や不可視の思考プロセスを理解した上で、モデルの判断に過度に依存しない運用が求められます。
まとめ
本記事では、OpenAIの次世代AIモデル「o1(ChatGPT)」について、その特徴や活用シーン、料金体系、さらに利用上の注意点まで幅広く解説しました。
o1は「考えてから答える」という設計により、科学研究やプログラミング、教育、ビジネスなど多様な分野で高い推論力を発揮します。
一方で、利用回数の制限やデータセキュリティの留意点、モデル固有の限界も存在するため、正しく理解し適切に使うことが重要です。活用の目的に応じてプランやモデルを選び、効率的かつ安全に導入してください。
今後さらに進化するoシリーズを見据えて、早めに活用方法を検討することが将来的な優位性につながります。


