
GPT‑4oとは?機能・性能・導入メリットをわかりやすく解説

生成AIは進化を続けており、その中でも「GPT-4o」は注目を集める最新モデルです。
高精度な文章生成に加えて、音声・画像など複数モードに対応する点や、応答速度の高速化など、多くの強みを備えています。
しかし、GPT-4oの導入を検討している方の中には、次のような疑問や関心を持つ方も多いのではないでしょうか。
GPT-4oの具体的な機能や性能について知りたい
既存モデル(GPT-4やGPT-3.5)との違いは?
GPT-4oの安全性やリスクは?
そこで本記事では、GPT-4oに興味がある方に向けて以下の内容を解説します。
この記事を読むことで、GPT-4oの基本から活用イメージまで理解でき、導入検討の参考にしていただけます。
ぜひ参考にしてください。
ChatGPTの特徴をより詳しく知りたい人は、次の記事を参考にしてください。

『生成AIに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- 生成AIに作業や仕事を任せる方法
- ChatGPTなどの生成AIを使いこなすたった1つのコツ
- 業務効率化や収入獲得に生成AIを活かす体験ワーク
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。
参加者には限定で「生成AI活用に役立つ7大特典」をプレゼント中🎁

この時間が、あなたを変える大きなきっかけになりますよ。
GPT-4oとは?

GPT-4oは、OpenAIが2024年5月13日に発表したマルチモーダルAIモデルです。
従来のGPT-4 Turboと同等の性能を備えながら、応答速度が大幅に改善され、コストも50%削減されている点が大きな特徴です。
特に注目すべきは、テキストだけでなく音声や画像、動画までを一つの統合モデルで処理できる点であり、平均応答速度はわずか320ミリ秒と、人間との会話に近い自然なインタラクションを実現します。
これにより、従来は別々のモデルやパイプラインで処理していた入力と出力がシームレスに統合され、より直感的でスムーズなやり取りが可能になりました。また、多言語対応も強化され、非英語環境での利用精度も大きく向上しているため、国際的な利用シーンでも高い価値を発揮します。
GPT-4oの“o” とは? “omni” の意味と特徴

GPT-4oの“o”は「omni(オムニ)」を意味しており、「すべて」「あらゆる」というニュアンスを持ちます。この名の通り、テキスト・画像・音声・動画といった多様なモードを統合的に理解・生成できることが最大の特徴です。
従来のシステムでは、音声をテキストに変換してから処理するなど、複数の段階を経る必要がありましたが、GPT-4oは単一のニューラルネットワークで全てを直接処理する「エンドツーエンド」設計を採用しています。
これにより、音声の抑揚や話者のニュアンス、環境音といった繊細な情報を保持したまま応答が可能となり、より人間らしい自然なやり取りを実現します。
また、単なるモード対応に留まらず、各モード間を横断する推論能力も強化されているため、例えば「画像を見て説明し、その内容を音声で返す」といった複雑な操作も一貫して行える点が画期的です。
リリース日とモデルの位置付

GPT-4oは2024年5月13日に正式発表され、ChatGPTのデフォルトモデルとして導入されました。
リリース当初から「より速く、より安く、より自然に」というコンセプトのもと、従来のGPT-4 Turboを置き換える形で提供が始まりました。性能面ではGPT-4に匹敵しつつ、応答速度やマルチモーダル対応力で大きく優れており、さらに50以上の言語をサポートすることでグローバル利用を強力に後押ししています。
その後2025年には後継モデルであるGPT-5が登場し、一時的に主役の座を譲りましたが、ユーザーからは「温かみのある自然な対話体験」が高く評価され続け、Plusプラン向けに再び提供されるなど根強い人気を維持しています。
こうした背景から、GPT-4oは単なる中継ぎモデルではなく、ChatGPTシリーズにおける大きな進化点を示す“転換期”の存在として位置付けられています。
GPT-4oの主な性能と強み

GPT-4oは、OpenAIが2024年5月13日に公開した最新の多モーダルAIモデルであり、テキスト、音声、画像、動画といった多様な情報形式を統合的に理解・生成できる点で従来のモデルを大きく進化させています。
以下では、GPT-4oの強みを支える三つの要素について詳しく解説します。
エンドツーエンド学習
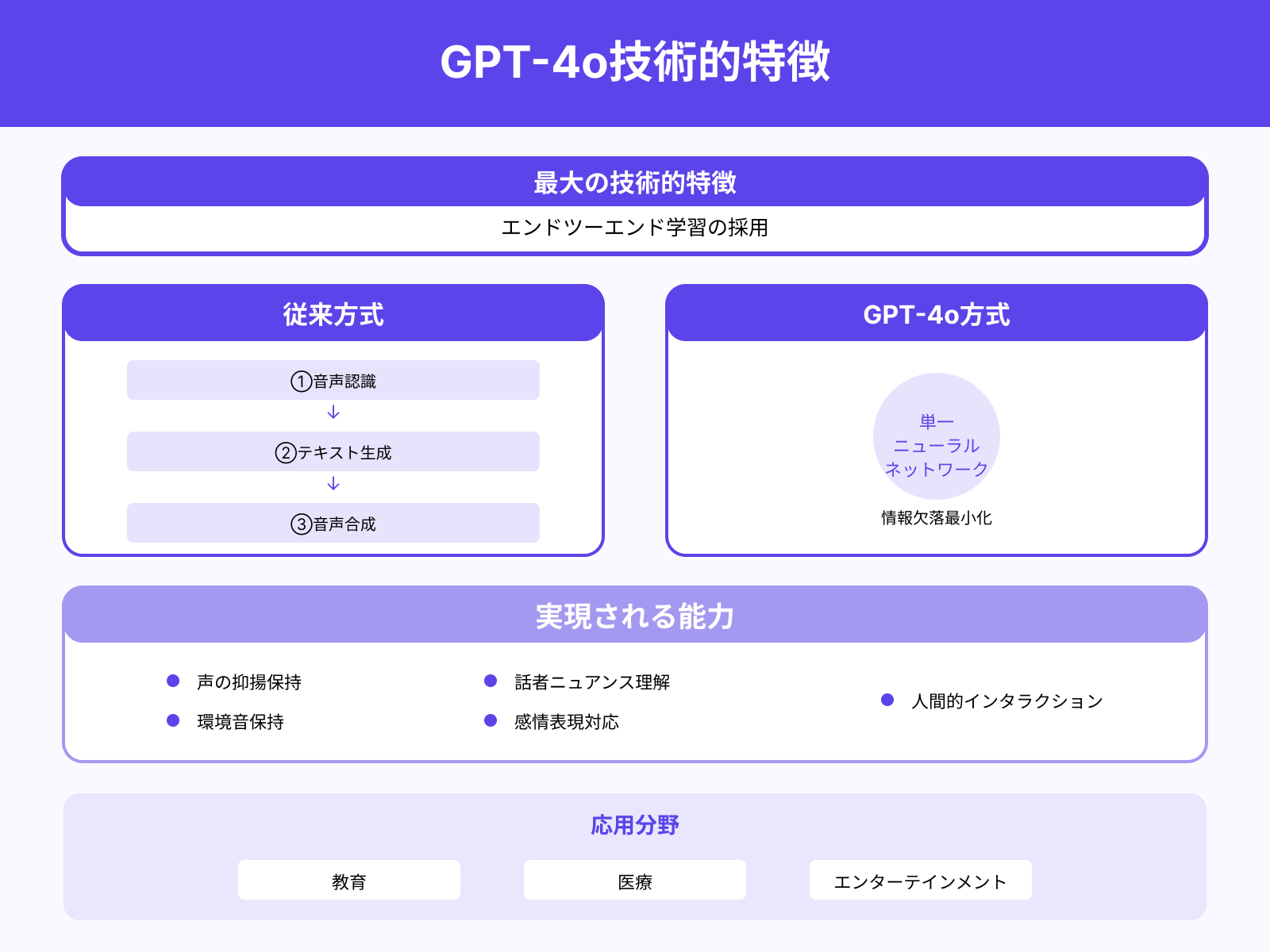
GPT-4oの最大の技術的特徴は「エンドツーエンド学習」の採用です。
従来の音声機能(Voice Mode)では、音声認識→テキスト生成→音声合成といった複数のモデルを組み合わせる必要があり、その過程で声の抑揚や環境音、話者のニュアンスが失われるという課題がありました。
GPT-4oではこれを一つのニューラルネットワークで処理することにより、情報の欠落を最小化し、声の感情表現や背景音も含めて自然に理解・生成できます。例えば、話し手の声色から意図を汲み取り、それに応じた表現で返答するといったことが可能になり、より人間的で親しみやすいインタラクションが実現します。
これは単なる利便性の向上にとどまらず、教育、医療、エンターテインメントなど、人間らしさが重要視される分野での応用に直結する大きな強みです。
高速な応答速度

GPT-4oは応答の高速化でも大きな進歩を遂げています。
音声入力に対して平均320ミリ秒、最短232ミリ秒という応答速度は、人間同士の自然な会話に極めて近いテンポです。比較として、従来のGPT-3.5のVoice Modeでは平均2.8秒、GPT-4では約5.4秒かかっていたため、大幅な短縮が実現されています。
これは、複数のモデルを連結する従来手法ではなく、統合モデルによる処理で遅延を排除したことによる成果です。結果として、ユーザーは「話す→返ってくる」という流れをほとんど違和感なく体験でき、リアルタイム性が重要なカスタマーサポートや通訳アプリ、インタラクティブな教育ツールなどで大きな価値を発揮します。
さらに、GPT-4 Turboに比べて2倍の速度、5倍のリクエスト制限を持つため、大規模利用や負荷の高いアプリケーションでも安定した応答が可能です。
多言語対応とコスト削減

GPT-4oは言語対応力と運用コストの両面で優れています。
50以上の言語をサポートし、全世界の人口の97%以上をカバーできるとされており、とりわけ非英語圏での精度向上が顕著です。これはトークナイザーの最適化によるもので、従来より少ないトークンで表現可能になり、翻訳や非ラテン文字圏での利用効率が飛躍的に改善しました。
その結果、文章生成のコストも削減され、より多くのユーザーが低負担で高度なAI機能を利用できます。さらに、APIにおいてはGPT-4 Turboと比較して約50%のコスト削減が可能で、速度は2倍、リクエスト上限は5倍と大幅に強化されています。
これにより、企業はコスト効率を高めつつグローバル市場でのサービス展開がしやすくなり、個人ユーザーにとっても手軽に利用できるAI環境が整備されました。GPT-4oは単なる性能向上だけでなく、利用の民主化を推進するモデルと言えるでしょう。
GPT-4oの活用例

GPT-4oは、従来のAIを大きく超えるマルチモーダル能力を備えた最新モデルであり、その活用範囲は日常生活からビジネス、教育、研究まで多岐にわたります。
以下では代表的な活用例として「リアルタイム音声会話」「画像認識と翻訳」「複合的な対話体験」の3つを詳しく見ていきます。
リアルタイム音声会話
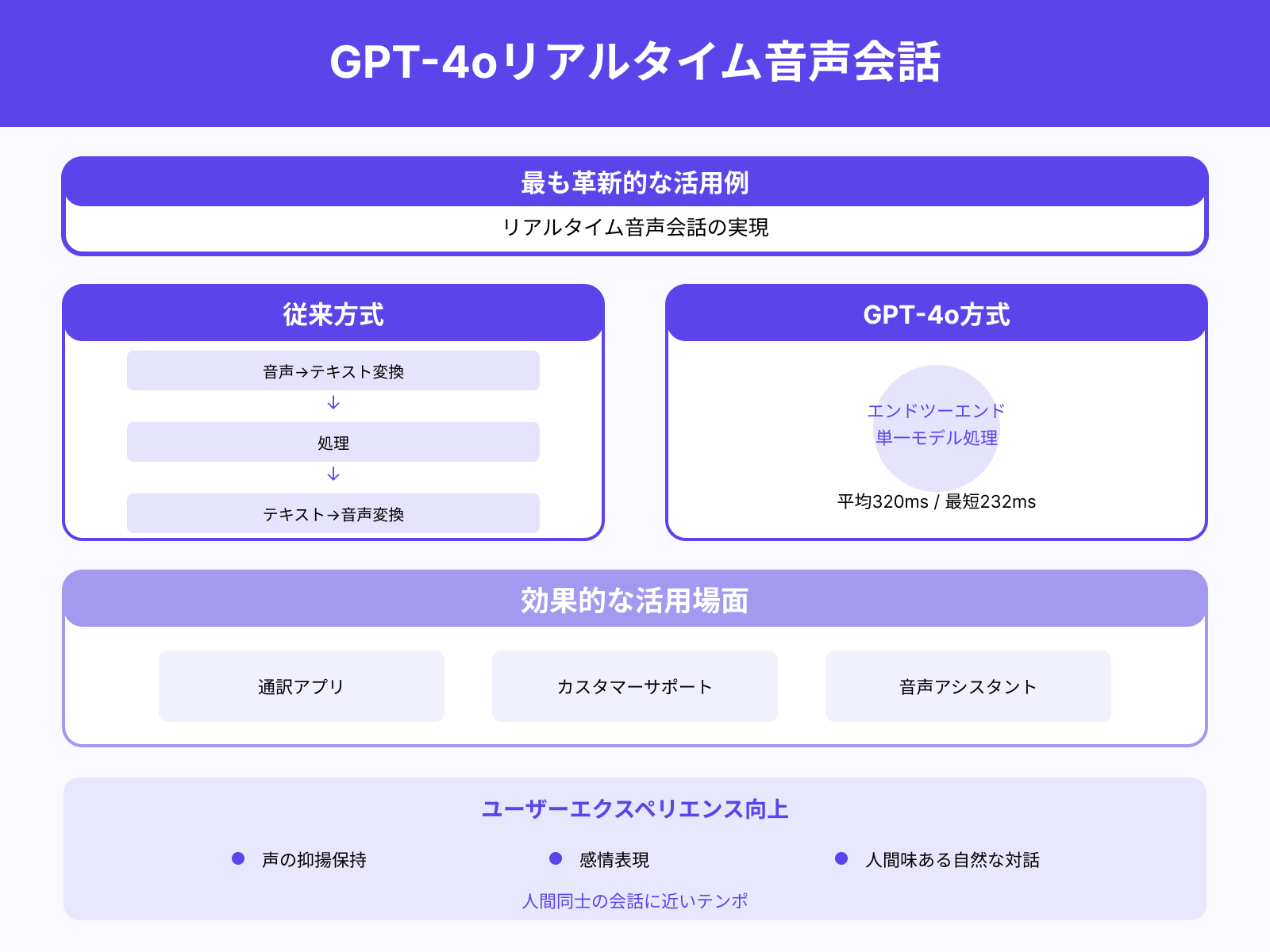
GPT-4oの最も革新的な活用例のひとつがリアルタイム音声会話です。
従来のGPT-3.5やGPT-4のVoice Modeでは、音声をテキストに変換してから処理し、再度音声に変換するという段階的処理が必要で、応答までに数秒の遅延が生じていました。
GPT-4oではこれを単一モデルでエンドツーエンド処理することで、平均320ミリ秒、最短232ミリ秒という応答速度を実現し、人間同士の会話に近いテンポでのやり取りが可能となりました。
これにより、通訳アプリやカスタマーサポート、音声アシスタントなど、即時性が重視される場面で非常に高い効果を発揮します。また、声の抑揚や感情を保持して返答できるため、単なる「答えを返す」だけでなく、人間味のある自然な対話が可能となり、ユーザーエクスペリエンスが飛躍的に向上しています。
画像認識と翻訳

GPT-4oは画像の認識と翻訳を組み合わせた活用にも強みを持っています。
ユーザーが写真やスクリーンショットを提示すると、モデルはその内容を理解し、自然な言語で説明や補足を行えます。例えば、旅行中に看板やメニューを撮影して即座に翻訳したり、学習の場で図表を見せながら解説を求めたりといったことが容易にできます。
従来の翻訳ツールはテキストベースが中心でしたが、GPT-4oでは画像と音声を組み合わせることで、より直感的で使いやすい体験が可能になります。さらに、リアルタイム音声翻訳機能を組み合わせれば、異なる言語を話す人同士がスムーズにコミュニケーションできる環境を提供でき、会議や観光、国際的な学術交流など、多言語環境での利用価値が格段に高まります。
このように「見せる・聞く・訳す」を同時に処理できる点は、従来のモデルにはない大きな進歩です。
複合的な対話体験
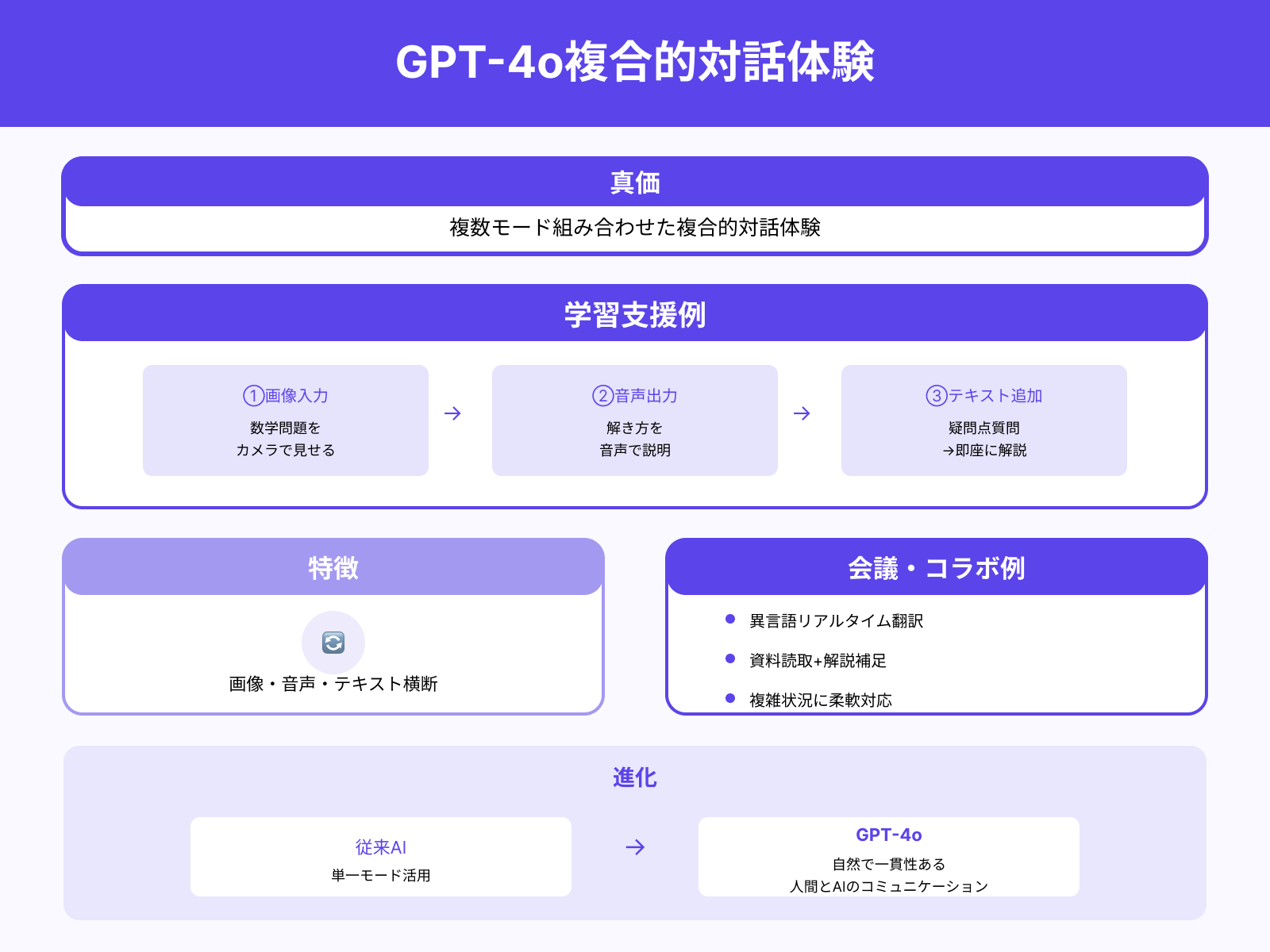
GPT-4oの真価は、複数のモードを組み合わせた「複合的な対話体験」にあります。
例えば、ユーザーが数学の問題を紙に書いてカメラで見せると、モデルが映像を認識して理解し、その解き方を音声で説明します。さらに疑問点をテキストで質問すると即座に追加解説が返ってくる、といったスムーズな学習支援が可能です。
これは単なるQ&Aにとどまらず、画像・音声・テキストを横断するダイナミックなやり取りが実現されている点に大きな特徴があります。また、会議やコラボレーションの場では、異言語の参加者同士の会話をリアルタイムに翻訳しつつ、発表資料を読み取って解説を補足する、といった複雑な状況にも柔軟に対応できます。
従来のAIは単一モードごとの活用が中心でしたが、GPT-4oはそれを超えて、人間とAIのコミュニケーションをより自然で一貫性のあるものへと進化させています。
GPT-4oの安全性とリスク管理

GPT-4oは、その高度な性能と多モーダル機能によって、教育、研究、ビジネスなど幅広い分野で活用が期待される一方、安全性やリスク管理に対する懸念も無視できません。
以下では、安全評価体制、音声モードのリスク、社会的影響の3点から掘り下げて解説します。
安全評価と準備体制

GPT-4oはリリース前に、多角的な安全評価を経ています。
リスクは「サイバーセキュリティ」「生物学的リスク」「説得力」「自律性」といった観点で検討され、その中で説得力のみが一部「中程度リスク」と判定されましたが、全体的には比較的低いリスクに収まっています。
さらに、外部の専門家を交えた大規模な検証が行われ、特にマルチモーダル入力に潜む脆弱性の洗い出しが進められました。加えて、音声出力に対するフィルタや、不適切な模倣・発話を防止するための仕組みも整えられています。
このような準備体制により、安全性は従来モデルに比べて強化されていますが、新しい攻撃手法や予期せぬ利用の可能性が残るため、運用後も継続的な改善が不可欠です。
音声モードの安全性
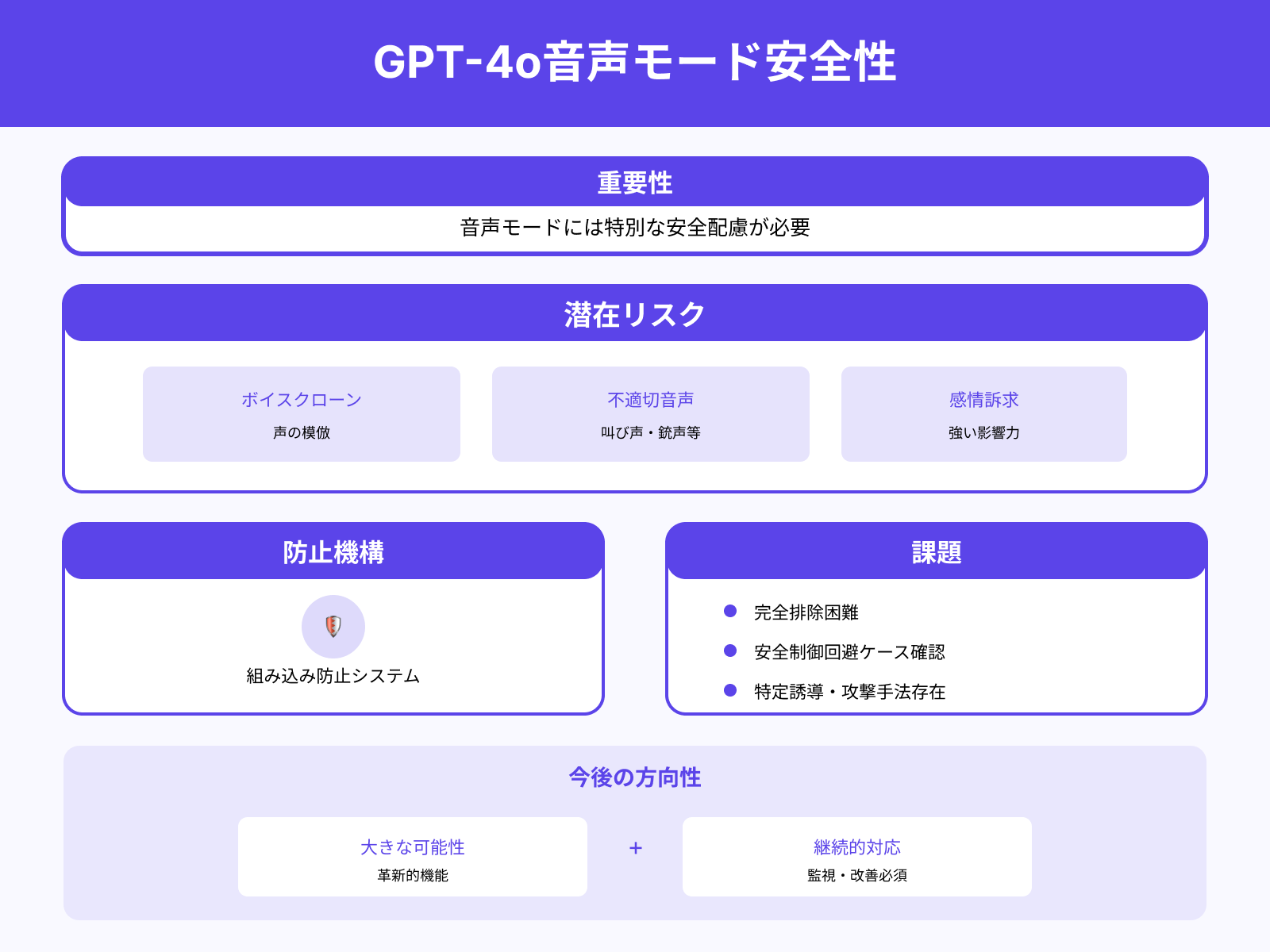
音声モードはGPT-4oの大きな特徴ですが、その安全性には特別な配慮が必要です。
声を模倣する「ボイスクローン」や、叫び声・銃声などの不適切な音声を生成するリスクが存在するため、モデルにはこれらを防止する仕組みが組み込まれています。
しかし、完全に排除することは難しく、特定の誘導や攻撃手法によって安全制御を回避されるケースも確認されています。また、音声はテキストよりも感情やニュアンスに訴えやすいため、ユーザーに強い影響を与える可能性がある点もリスクのひとつです。
このため、音声モードは大きな可能性を秘めている一方で、今後も継続的な監視と改善が求められる領域です。
社会的影響への配慮

GPT-4oの利用にあたっては、技術的なリスクだけでなく、社会的影響への配慮も欠かせません。
AIとの対話を通じて、ユーザーが感情的に依存したり、擬人化してしまう可能性が指摘されています。特に未成年や心理的に脆弱な人々にとっては、AIとのやり取りが強い影響を及ぼす場合があります。
実際に、利用者がAIとの会話をきっかけに深刻な心理的影響を受けた事例も報告されており、社会全体での安全対策が求められています。また、一部では陰謀論や非現実的な発想を強化するような応答が生成される場合もあり、誤情報や依存を助長するリスクも存在します。
こうした社会的影響に対しては、技術的制御に加えて、倫理的・制度的な枠組みを整備し、利用者教育を進めていくことが不可欠です。
GPT-4oと他のモデルとの比較

GPT-4oは、従来のGPT-4やGPT-4 Turboに比べて高速化・低コスト化を実現し、さらに音声や画像、動画まで処理可能な多モーダル能力を備えたモデルです。その一方で、より軽量な「GPT-4o mini」や、後継となる「GPT-5」との比較によって、その特徴と立ち位置がより明確になります。
以下では、GPT-4やGPT-4 Turboとの違い、軽量版GPT-4o miniの特徴、そして後継モデルGPT-5との関係について詳しく解説します。
GPT‑4 Turbo・GPT‑4との性能比較
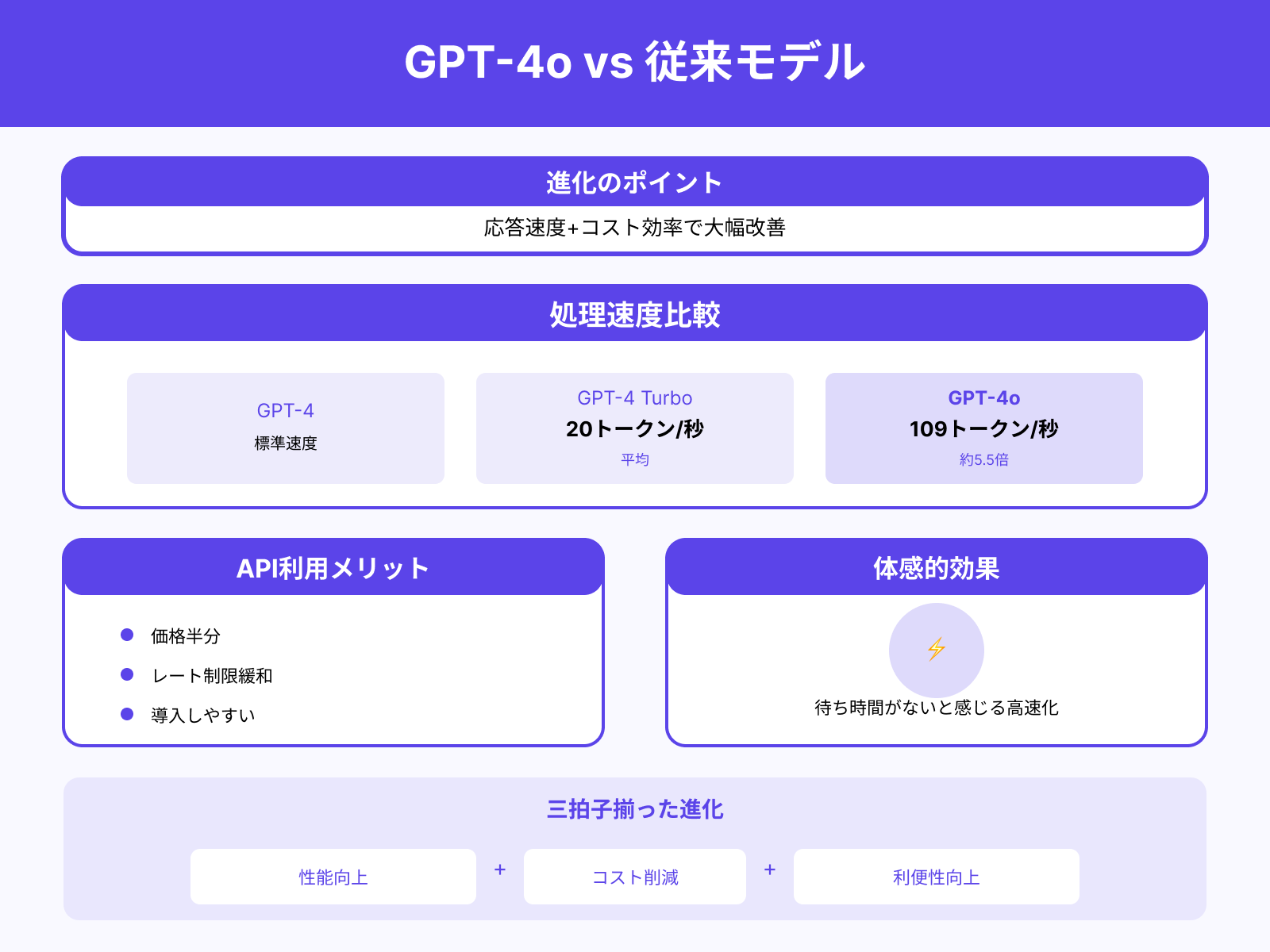
GPT-4oは、従来のGPT-4やGPT-4 Turboと比べ、応答速度とコスト効率において大きく優れています。
GPT-4 Turboが平均20トークン/秒の処理速度であるのに対し、GPT-4oは109トークン/秒を達成しており、テキスト生成や長文処理でも体感的に「待ち時間がない」と感じられるほどの高速化を実現しています。
さらにAPI利用では価格が半分になり、レート制限も緩和されているため、開発者や企業にとってより導入しやすい選択肢となっています。性能・コスト・利便性の三拍子が揃った点で、GPT-4oは従来モデルに対する明確な進化を遂げています。
ChatGPT4の特徴を詳しく知りたい人は、次の記事を参考にしてください。

GPT‑4o miniとの違い

GPT-4o miniは、GPT-4oの軽量版として登場したモデルで、性能よりも「手軽さ」と「低コスト」を重視しています。
GPT-4o miniはテキストと画像に対応し、応答速度や精度もGPT-4に匹敵する水準を確保しながら、利用料金は大幅に抑えられているのが特徴です。例えば、APIのトークン単価はGPT-4oよりさらに低価格に設定されており、コスト効率が最優先となる開発やアプリケーションに適しています。
その一方で、GPT-4oが対応している音声や動画といった高度なマルチモーダル機能はサポートしていないため、複雑なリアルタイム対話やクロスモード処理を必要とするケースには不向きです。
つまり、GPT-4o miniは「軽快で安価に利用できる実用モデル」、GPT-4oは「本格的なマルチモーダル体験を提供する上位モデル」と位置づけられ、それぞれのニーズに応じて選択が可能です。
GPT-4o miniの特徴をより詳しく知りたい人は、次の記事を参考にしてください。

GPT‑5や後続モデルとの違いとポジション

GPT-5は2025年8月に登場した後継モデルであり、推論能力や正確性、マルチモーダル対応力においてGPT-4oを凌駕しています。特に、事実誤認(ハルシネーション)の抑制や、ユーザー意図に応じた「思考モード」の切り替え機能などが導入され、専門分野での信頼性が高まりました。
ビジネスや医療、研究のように精度が最重要となる場面ではGPT-5が優位ですが、一方でユーザーからは「GPT-4oのほうが親しみやすく、対話が温かい」という評価も多く寄せられました。そのため、GPT-4oはGPT-5の登場後も完全に姿を消すことなく、ChatGPT Plusユーザー向けに再導入されるなど独自のポジションを保っています。
つまり、GPT-5は技術的な最先端を担う“精密モデル”、GPT-4oはユーザー体験を重視する“親しみやすいモデル”として、互いに異なる役割を果たし続けています。
ChatGPT5の特徴を詳しく知りたい人は、次の記事を参考にしてください。

GPT-4oの導入方法と注意点

GPT-4oは、テキスト・音声・画像・動画を統合的に扱える多モーダルAIモデルとして注目を集めています。導入することで、従来のモデル以上に自然で効率的な対話や情報処理が可能になりますが、利用にはいくつかの留意点があります。
以下では、プランの違い、モデル切り替えと画像生成、そして倫理面の注意点について詳しく解説します。
利用できるプラン

GPT-4oは、ChatGPTの無料プランでも一部利用できますが、使用回数や機能は制限されています。より本格的に活用する場合は、有料のChatGPT Plusプランが推奨されます。
Plusプランでは、GPT-4oを安定的に利用できるほか、画像生成や高度な対話機能など、制限なく利用できる場面が広がります。
開発者にとっては、OpenAI APIを通じてGPT-4oを利用でき、特に注目すべきは従来のGPT-4 Turboに比べて「価格は半分」「速度は2倍」「リクエスト制限は5倍」という効率性の高さです。企業が大規模に導入する場合、このコスト効率の向上は大きなメリットとなります。
用途や予算に応じて、無料で試すのか、安定した環境を求めて有料にするのかを見極めることが重要です。ChatGPTの無料版と有料プランの特徴をより詳しく知りたい人は、次の記事を参考にしてください。

モデル切り替えと画像生成

ChatGPTの利用環境では、ユーザーがメニューからモデルを選択してGPT-4oに切り替えることが可能です。
有料プランでは「旧モデルを表示」オプションを有効にするとGPT-4oを選択できるようになります。
また、画像生成はGPT-4oにネイティブ統合されており、外部ツールを使わなくてもチャット内で直接画像を生成できます。ユーザーはテキストで指示を与えるだけで画像が作られ、さらに「もう少し明るく」「別の角度で」といった追加の修正依頼も自然な対話の中で行えます。
これにより、従来のように個別の画像生成サービスを利用する必要がなくなり、シームレスに創作や資料作成に活用できます。
モデル切り替えや画像生成の操作方法を把握しておくことで、GPT-4oの可能性を最大限に引き出すことができます。
倫理的配慮とリスク

GPT-4oは強力な生成能力を持つ一方で、その利用には倫理的配慮とリスク管理が欠かせません。
例えば、画像生成において不適切なコンテンツが出力されたり、音声モードで感情を過度に刺激する表現が作られたりする可能性があります。また、誤情報や偏った表現を拡散するリスク、ユーザーがAIに心理的依存を深めてしまう懸念もあります。
導入にあたっては、フィルタリングや利用制限を適切に設定すること、さらに利用者に対して「AIの応答は常に正確とは限らない」という認識を持たせる教育も重要です。特に未成年や心理的に脆弱な層が利用する環境では、保護者や組織による管理体制が不可欠です。
GPT-4oの利便性を最大限活かすためには、倫理的な責任と安全な運用体制を両立させることが求められます。
まとめ
GPT-4oは高精度な文章生成に加え、音声や画像などを統合的に扱える次世代AIとして大きな可能性を秘めています。従来モデルに比べて高速かつ低コストで、多言語にも強い点は個人・企業を問わず魅力的です。
一方で、安全性や倫理的リスクにも目を向け、利用環境に応じたガイドラインや制御が欠かせません。
今後さらに進化する生成AIの動向を追いながら、最適な形で取り入れていくことが重要になるでしょう。本記事を通じてGPT-4oの特徴や導入方法を理解し、自身の目的に合った活用法を検討するきっかけにしていただければ幸いです。


