
Google AI Studioでアプリを開発する方法!開発フローを解説

Google AI Studioで何ができる?
本当にアプリ開発ができる?
料金や制限はどこまで気にすべき?
このような疑問を持つ方も多いと思います。
Google AI Studioは、Googleの生成AIモデル「Gemini」をブラウザ上で試しながら、実際のアプリにつなげるための設計や検証ができる開発者向けツールです。
この記事では、Google AI Studioでのアプリ開発について以下の内容を解説します。
ぜひ最後までご覧ください。
なお、生成AIを学び副業や業務効率化を実現したい人は「侍エンジニア」をお試しください。
侍エンジニアでは現役エンジニアと学習コーチが学習をサポート。AIプログラミングやPython・VBAの習得を通じて、手間のかかる作業を効率化する方法を学べます。
受講料が最大80%OFFになる「給付金コース」も提供中。未経験から挫折なくAIスキルを習得したい人は、ぜひ一度お試しください。
Google AI Studioとは?

Google AI Studioは、Googleの生成AIモデル「Gemini」ファミリーをブラウザ上で試しながら、アプリ開発の準備ができる開発者向けのツールです。
テキストや画像、音声、動画などマルチモーダルな入力に対応したモデルを1つの画面で検証できます。プロンプトや各種設定を変えながら出力を比較できるため、チャットボットや要約、画像生成などのアイデアを素早くプロトタイプが作成可能です。
気に入った設定は「Get code」からPythonやJavaScriptなどのコードとして取得でき、そのままGemini APIを使うアプリに組み込めます。
さらに、AI Studio上でGemini API用のAPIキーを発行し、利用状況やレート制限の確認も行えます。Google AI Studioの特徴をより詳しく知りたい人は、次の記事を参考にしてください。

Google AI Studioで始めるアプリ開発の全体フロー

この章では、Google AI Studioで始めるアプリ開発の全体フローを以下の順で紹介します。
1つずつ詳しく見ていきましょう。
テキスト入力だけで試せる「Build」機能の基本操作

Google AI Studioの「Build」モードでは、まず画面中央の入力欄にテキストで作りたいアプリのイメージを書き込むだけで概要を設計できます。
モデルやバージョンをプルダウンから選び、温度や最大トークン数などのパラメータを右側の設定パネルで調整しましょう。追加したい機能があれば、画像生成やマップ連携などの「AIチップ」を選択してプロンプトに組み込めます。
思いつかないときは「I’m Feeling Lucky」を押すと、Geminiがプロジェクト案付きのプロンプトを自動で提案してくれます。
テキストだけで構成を素早く試せるため、最初のラフなアイデア出しや要件整理に向いたモードです。Google AI Studio Buildの使い方をより詳しく知りたい人は、次の記事を参考にしてください。

プロンプト作成から動作確認までの基本ステップ
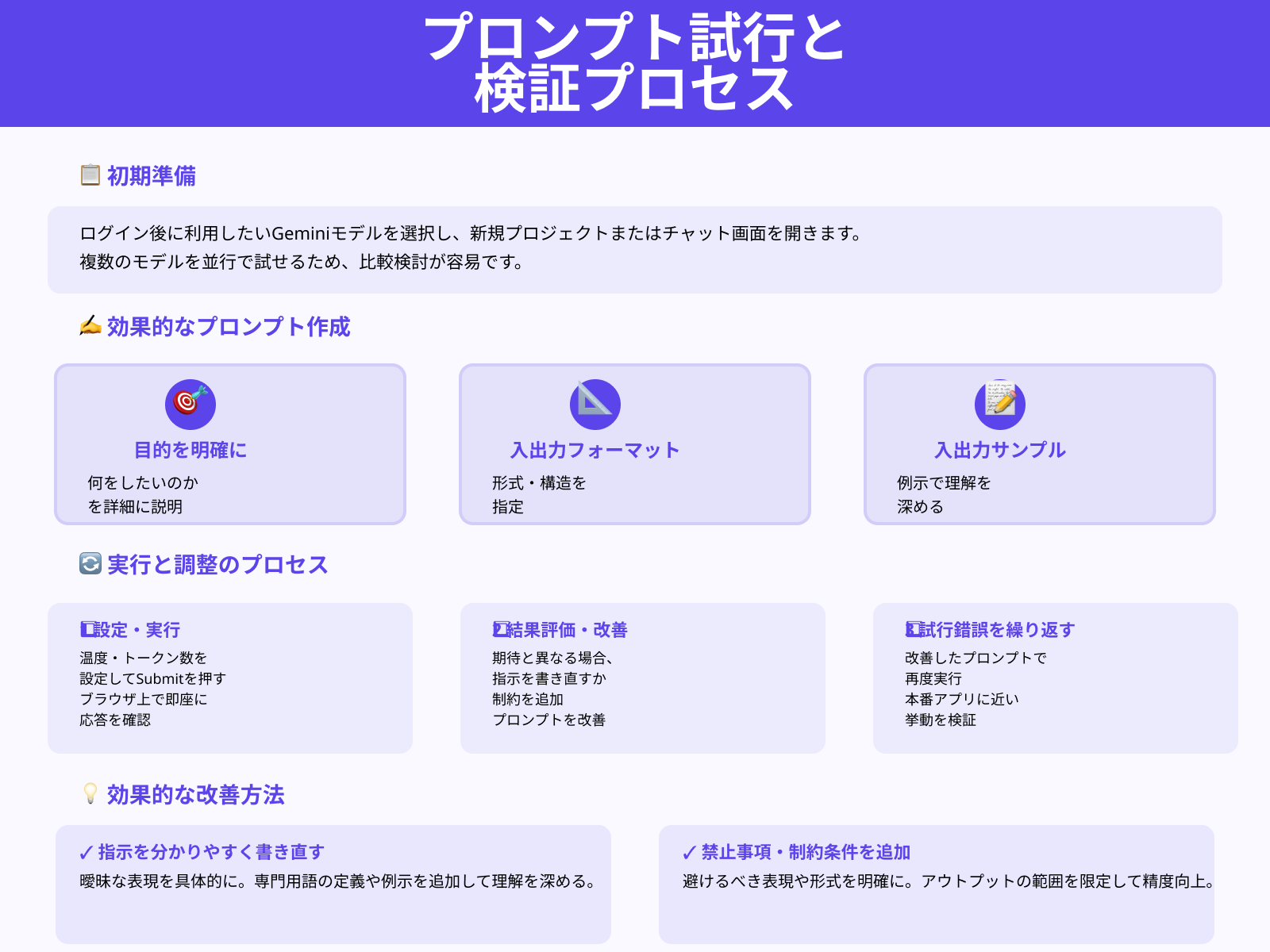
Google AI Studioでプロンプトを試す際は、まずログイン後に利用したいGeminiモデルを選択し、新規プロジェクトまたはチャット画面を開きます。
次に、目的や入力形式、出力フォーマットが伝わるようにプロンプト文を作成し、必要に応じて例示となる入出力サンプルも追記してください。設定パネルで温度や最大トークン数を調整し、「Submit」ボタンを押して応答を生成します。
返ってきた結果が期待と違う場合は、指示を分かりやすく書き直したり、禁止事項や制約条件を追加して再度実行しましょう。
この試行錯誤を繰り返すと、本番アプリに近い挙動をブラウザ上だけで検証できます。Geminiの使い方を詳しく知りたい人は、次の記事を参考にしてください。

「Get code」でプロトタイプを実装コードに変える手順

プロンプトと設定が固まったら、画面右上付近の「Get code」ボタンから実装用コードを生成可能です。
押すと、PythonやJavaScript、curlなど複数の言語タブが表示され、選んだ言語向けのGemini API呼び出しコードが自動で作られます。
コード内にはモデル名やエンドポイント、プロンプトを渡す処理、レスポンスを受け取る処理がひな形として含まれます。表示されたコードをIDEや自分のプロジェクトにコピーし、環境変数などでAPIキーを設定すれば、そのまま動く最小プロトタイプとして利用可能です。
まずAI Studioで挙動を確認し、「Get code」でコード化する流れを押さえることで、設計から実装までをスムーズに接続できます。
Google AI Studio×Gemini APIで作れるアプリ事例4選

この章では、Google AI Studio×Gemini APIで作れるアプリを以下の4つ紹介します。
1つずつ詳しく見ていきましょう。
社内FAQや顧客対応に使えるチャットボットアプリ

Google AI StudioとGemini APIを組み合わせると、自社のマニュアルやFAQを参照するチャットボットを構築できます。
まずAI Studio上で、質問と回答のパターンを想定したプロンプトを作成し、回答のトーンや禁止事項を細かく指定しましょう。次にGemini APIからそのプロンプトを呼び出し、社内ポータルや問い合わせフォームと連携させます。
社内向けであれば、問い合わせ履歴をもとに回答例を改善し、顧客向けであれば営業時間や料金などの最新情報を別システムから取得する設計も可能です。
これにより、よくある質問への対応を自動化しつつ、人手によるサポートは難しいケースに集中できる体制を作れます。
画像やPDFを解析して要約するドキュメントアシスタント

Geminiのマルチモーダル機能を使うと、画像やPDFをアップロードして中身を要約させるドキュメントアシスタントを作れます。
AI Studioでは、議事録やレポートなどの形式に合わせた要約スタイルをプロンプトで定義し、出力フォーマットも箇条書きや要点3つなどに指定が可能です。Gemini API側では、アップロードしたファイルをモデルに渡し、その結果をWebアプリや社内ツールで表示します。
長い資料の重要ポイント抽出や、会議前の事前インプットとしての要約配信などに応用でき、ドキュメントの読み込み時間を大きく削減可能です。
SNS用テキストや商品紹介文を一括で作れる文章生成アプリ
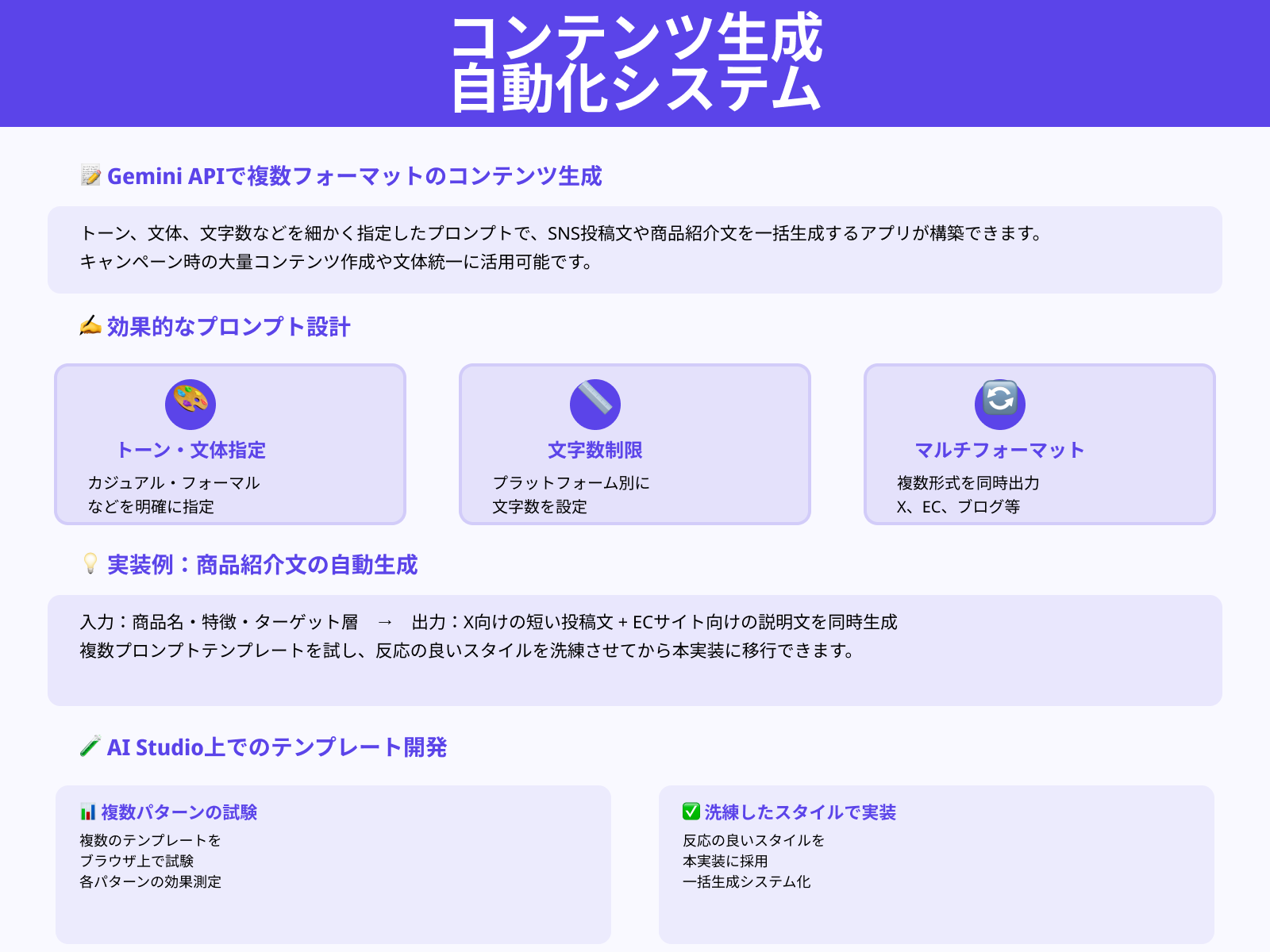
Google AI Studioでトーンや文体、文字数などを細かく指定したプロンプトを用意すると、Gemini API経由でSNS投稿文や商品紹介文を一括生成するアプリを構築できます。
例えば、商品名と特徴、ターゲット層を入力すると、X向けの短い投稿文とECサイト向けの説明文を同時に出力するプロンプト設計が可能です。
AI Studio上で複数パターンのテンプレートを試し、反応の良いスタイルを洗練させてから実装に移せます。これにより、キャンペーン時の大量コンテンツ作成や、担当者ごとの文体のばらつき削減に役立つでしょう。
検索と連携した「調査+要約」リサーチ支援アプリ

Gemini APIは検索系の機能とも組み合わせると、調査から要約までを一気通貫で支援するアプリに発展させられます。
外部の検索APIや社内検索と連携し、取得した複数の記事や資料をGeminiに渡して要点をまとめる設計が代表的なパターンです。
Google AI Studioでは、複数ソースを前提にした要約プロンプトや、比較表や箇条書きで整理する出力形式を先に検証できます。そのうえでGemini APIから同じプロンプトを呼び出せば、リサーチ担当者はリンクを開いて読む時間を減らし、重要な部分の精査や判断に集中できます。
Google AI Studioのコードをアプリに組み込む実装パターン3選

この章では、Google AI Studioのコードをアプリに組み込む実装パターンを3つ紹介します。
1つずつ詳しく見ていきましょう。
Node.jsやPythonからGemini APIを呼び出す

Gemini APIは公式のNode.jsとPython向けクライアントライブラリが提供されているため、サーバーサイドから安全に呼び出せます。
まずGoogle AI StudioでAPIキーを発行し、環境変数などでコードに渡しましょう。Node.jsなら公式SDKをインストールし、モデル名とプロンプトを指定してgenerateContentなどのメソッドを実行します。
Pythonでも同様にクライアントを初期化し、テキスト生成やマルチモーダル入力の呼び出しを行ってください。
どちらの言語もサンプルコードが公式ドキュメントに用意されているため、それをベースにエラーハンドリングやログ出力を追加していく流れが基本になります。
Next.jsなどWebフロントとAPIサーバーを分けて連携する

Gemini APIキーは秘密情報のため、Next.jsなどのWebフロントからは直接呼び出さず、バックエンドAPIを挟む構成が推奨されます。
フロントエンドでは、ユーザー入力や画面の状態だけを自前のAPIエンドポイントに送信しましょう。サーバー側では受け取った内容をもとにGemini APIを呼び出し、生成結果だけをフロントへ返します。
この構成にすると、APIキーをブラウザに露出させずに済むのです。
また、バックエンドでレート制限やログ記録、プロンプトの一部固定などの制御も行いやすくなり、運用しやすいアーキテクチャになります。
Androidなどモバイルアプリからバックエンド経由で利用する

AndroidなどのモバイルアプリからGeminiを利用する場合も、基本的にはバックエンドサーバー経由で呼び出す構成にしましょう。
モバイルアプリはユーザーの入力や撮影した画像、端末内のファイル情報などをHTTPSで自社サーバーに送信します。サーバー側でGemini APIに適切な形式でリクエストを送り、返ってきた応答をアプリ向けのJSONなどに整形して返却します。
こうすると、APIキーをアプリ内に埋め込まずに済み、キー漏えいや不正利用のリスクを下げられるでしょう。また、サーバー側で認証や課金ロジックを一元管理できるため、将来的な機能追加や他サービス連携にも対応しやすくなります。
Google AI Studioを使ったアプリ開発の料金と制限の考え方

この章では、Google AI Studioを使ったアプリ開発の料金と制限の考え方を以下の順で解説します。
1つずつ詳しく見ていきましょう。
無料枠でどこまで試せるかの目安を知っておく

Google AI Studioは、UI上での利用については無料で試せる範囲が用意されており、Gemini 2.0 Flashなど一部モデルには無料利用枠があります。
無料枠では、日ごとのリクエスト数やトークン量に上限があり、小規模な検証やプロトタイプ作成には十分なケースが多いです。一方で、商用環境での継続的な利用や大量リクエストを想定する場合は、早い段階から有料プランの料金表や上限値を確認しておくことが重要です。
まずはAI StudioのUIで挙動をつかみつつ、どの程度の頻度とトラフィックでAPIを呼び出すかを見積もると、本番運用に必要なコストの感覚をつかみやすくなります。
Google AI Studioの料金を詳しく知りたい人は、次の記事を参考にしてください。

RPD・RPM・TPMなどレート制限とアプリ設計の関係

Gemini APIには、1日あたりのリクエスト数を表すRPDや、1分あたりのリクエスト数を表すRPM、1分あたりのトークン数を表すTPMといったレート制限が設定されています。これらの上限値はモデルや料金プランによって異なり、ドキュメントで確認が可能です。
アプリ開発では、これらの制限を踏まえてキューイングやバッチ処理、リトライ制御などの設計を行う必要があります。
特に、ユーザー数の多いサービスやバックグラウンドで大量処理を行うワークフローでは、同時リクエスト数を調整し、エラー時に待機して再試行するロジックを組み込むことが欠かせません。
Search追加課金やマルチモーダル利用時のコスト感を把握する

Geminiでは、テキスト生成だけでなく検索連携やマルチモーダル入力を行う場合に、通常のトークン課金とは別に料金が発生する機能があります。
たとえば、Search機能を利用する場合は、検索ごとに追加料金が設定されており、料金表で単価が公開されています。また、画像や動画などのマルチモーダル入力は、テキストのみの利用と比べてトークンや処理負荷が増え、結果的にコストも高くなりやすいです。
アプリ設計時には、どの処理でSearchを使うか、どの画面でマルチモーダルを許可するかを決め、利用頻度をあらかじめシミュレーションしておくことが重要です。
Google AI Studioでのアプリ開発を成功させるコツ3選

この章では、Google AI Studioでのアプリ開発を成功させるコツを3つ紹介します。
1つずつ詳しく見ていきましょう。
プロンプトと設定をバージョン管理して再現性を高める

Google AI Studioでは、同じプロンプトでも最大トークン数、システムプロンプトの有無によって出力が大きく変わります。
そのため、本番に使うプロンプトとパラメータの組み合わせは、日付や目的と一緒に記録し、Gitなどでバージョン管理しておくことがおすすめです。
プロンプト文だけでなく、利用しているモデル名やモデルバージョン、入出力フォーマットの指定内容も残しておくと、後から不具合が出た際に原因を特定しやすくなります。
AI Studio上でうまくいった設定を「Get code」でコード化し、その時点のプロンプトとセットで管理すると、開発チーム内での共有もしやすくなります。
ログを見ながら誤回答や失敗ケースを改善する習慣をつくる

生成AIを組み込んだアプリでは、すべての回答が常に正しいとは限らないため、ログを前提にした改善サイクルが重要になります。
アプリ側でユーザー入力とAIの出力、エラーコードなどを記録しておき、誤回答が発生したケースを後から確認できるようにしましょう。誤回答が多いパターンを洗い出したうえで、プロンプトに禁止事項や補足説明を追加したり、前処理や後処理のロジックを見直したりすると、品質を段階的に高められます。
Google AI Studio上でテストした履歴も参考にしながら、ログを起点にした改善を習慣化すると、運用開始後のトラブルを減らしやすくなります。
小さく作ってユーザーテスト→改善を回す開発スタイルにする

生成AIを活用したアプリは、初期の段階で完璧な仕様を決めるよりも、小さなスコープで動くものを作り、実際のユーザーに試してもらいながら改善していくスタイルが適しています。
まずはGoogle AI Studioで1つのユースケースに絞ったプロンプトを作り、最小限の画面とAPI連携だけを実装します。そのうえで、ユーザーからのフィードバックやログをもとに、プロンプトの見直しやUIの改善、機能追加を小刻みに行いましょう。
このように「小さく作って試す」サイクルを前提にすると、想定外の使い方やニーズにも柔軟に対応でき、結果としてユーザーにとって使いやすいAIアプリへと育てられます。
まとめ
この記事では、Google AI Studioでのアプリ開発について以下の内容を解説しました。
Google AI StudioとGemini APIを組み合わせると、ブラウザだけでアイデア検証を行い、そのまま実装コードへつなげる開発フローを構築できます。Build機能でプロンプトと設定を調整し、Get codeでコード化し、Node.jsやPython、Next.jsやモバイルアプリから安全に呼び出すと、実務に耐えるAIアプリへと発展させられます。
その際には、無料枠と有料利用の境目やRPD・RPM・TPMなどのレート制限、Searchやマルチモーダル利用時のコストを早めに把握しておくことが重要です。
この記事の内容を参考にしながら、自社のユースケースに合ったスモールスタートからGoogle AI Studioでのアプリ開発を始めてみてください。


