
OllamaでClaude Codeを使うには?活用手順をわかりやすく解説

OllamaでClaude Codeって使える?
どうやって設定すればいいんだろう…
Claude CodeにOllamaを組み合わせると、ローカル環境でAIコーディングアシスタントを動かせます。API料金を抑えたい人や、コードをクラウドに送信したくない人に注目されている活用方法です。
ただ、初期設定にはいくつか手順があるため「どこから始めればいいかわからない」と感じる人も多いですよね。
そこでこの記事ではメリット・デメリットも交え、OllamaでClaude Codeを使う方法を解説します。おすすめモデルの選び方や動作が不安定なときの対処法も紹介するので、ぜひ参考にしてください。
Claude Codeの特徴をおさらいしておきたい人は、次の記事を参考にしてください。

- OllamaとClaude Codeの組み合わせではClaude APIの料金は発生し続ける
- ローカルモデル利用でコスト削減とプライバシー保護を両立できる
- 環境構築はOllama導入→モデル取得→OpenAI互換API接続の3ステップ
『ClaudeCodeに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- ClaudeCodeに作業や仕事を任せる方法
- ClaudeCodeを使いこなすたった1つのコツ
- 業務効率化や収入獲得に活かすClaudeCodeの実演
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。この時間が、あなたを変える大きなきっかけになりますよ。
OllamaでClaude Codeは使える
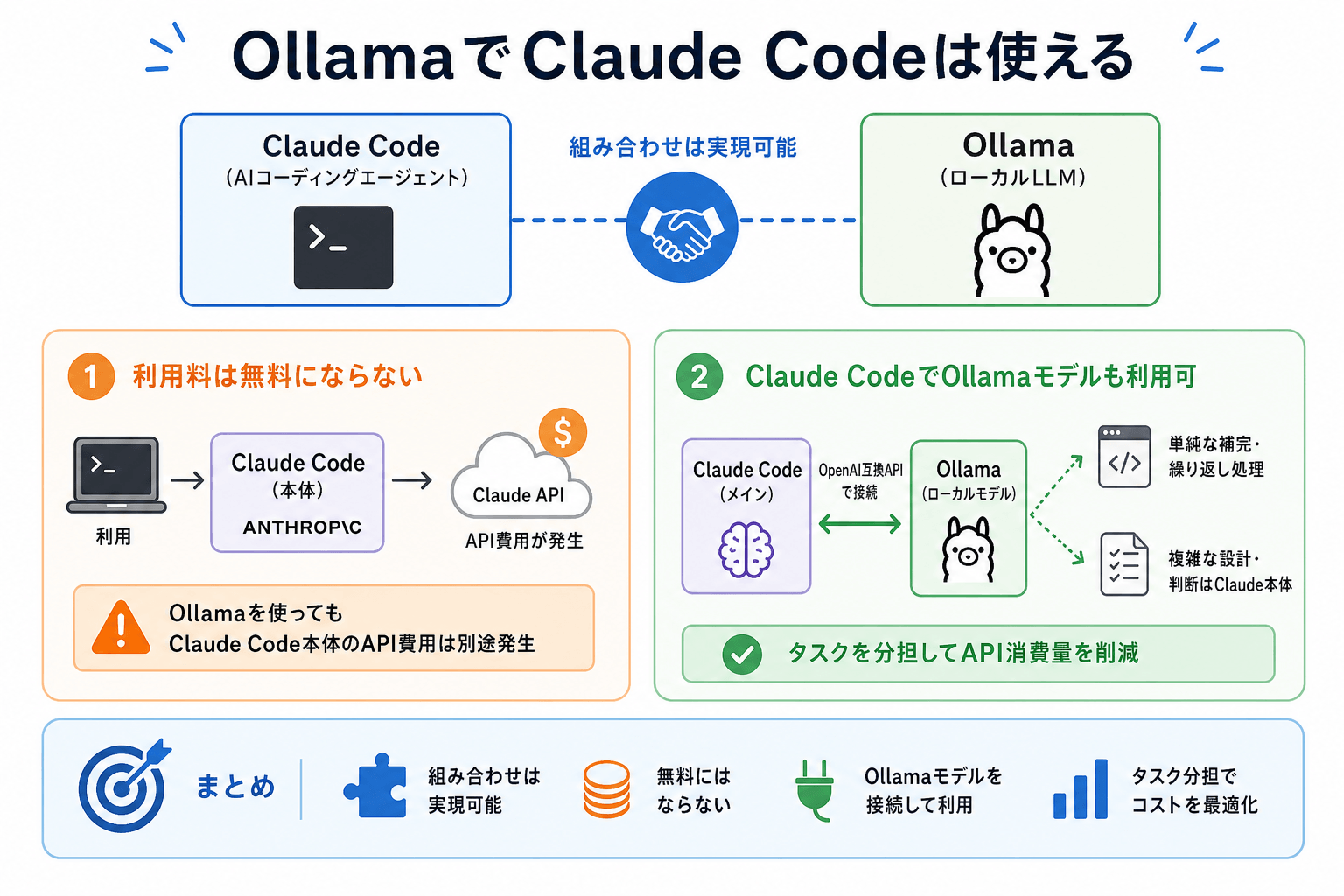
Anthropicが開発したClaude Codeは、ターミナル上で動作するAIコーディングエージェントです。Ollamaと組み合わせることで、ローカルLLM(大規模言語モデル)を活用した開発環境を構築できます。
ここからは次の2点を解説します。
利用料は無料にならない
Ollamaを使っても、Claude Codeの利用料が完全に無料になるわけではありません。
Claude Codeの利用には、基本的にClaude APIへのアクセスが必要です。OllamaはローカルLLMを動かすツールであり、Claude Code本体とは役割が異なります。
たとえば、OllamaでQwen3やGemma4などのモデルをローカルで動かしても、Claude Code自体の認証や一部機能ではAnthropicのAPIキーが必要になる場合があります。
また、Claude APIには従量課金があります。API料金は2026年5月時点でClaude Sonnet 4.6が入力100万トークンあたり3ドル、出力が15ドルとなっています。
そのため「Ollamaを使えば完全無料でClaude Codeを運用できる」という認識は正確ではありません。ただし、一部処理をローカルモデルへ分散することで、APIコストを抑える効果は期待できます。
Claude Codeの料金をより詳しく知りたい人は、次の記事を参考にしてください。

Claude CodeでOllamaモデルも利用可
Claude Codeは、Ollama上で動作するローカルモデルを補助的に利用できます。
これは、OpenAI互換APIを経由してOllamaのモデルを接続できるためです。設定を行うことで、Claude CodeからローカルLLMを呼び出せます。
たとえば、次のような使い分けが可能です。
- 単純なコード補完 → Ollamaモデル
- 定型的な処理 → Ollamaモデル
- 複雑な設計やレビュー → Claude本体
このように役割分担することで、API使用量を抑えながら開発効率を高められます。
とくにローカル環境で高速に試行錯誤したい人や、機密コードをクラウドへ送信したくない人に向いている構成です。
OllamaでのClaude Code活用でできること
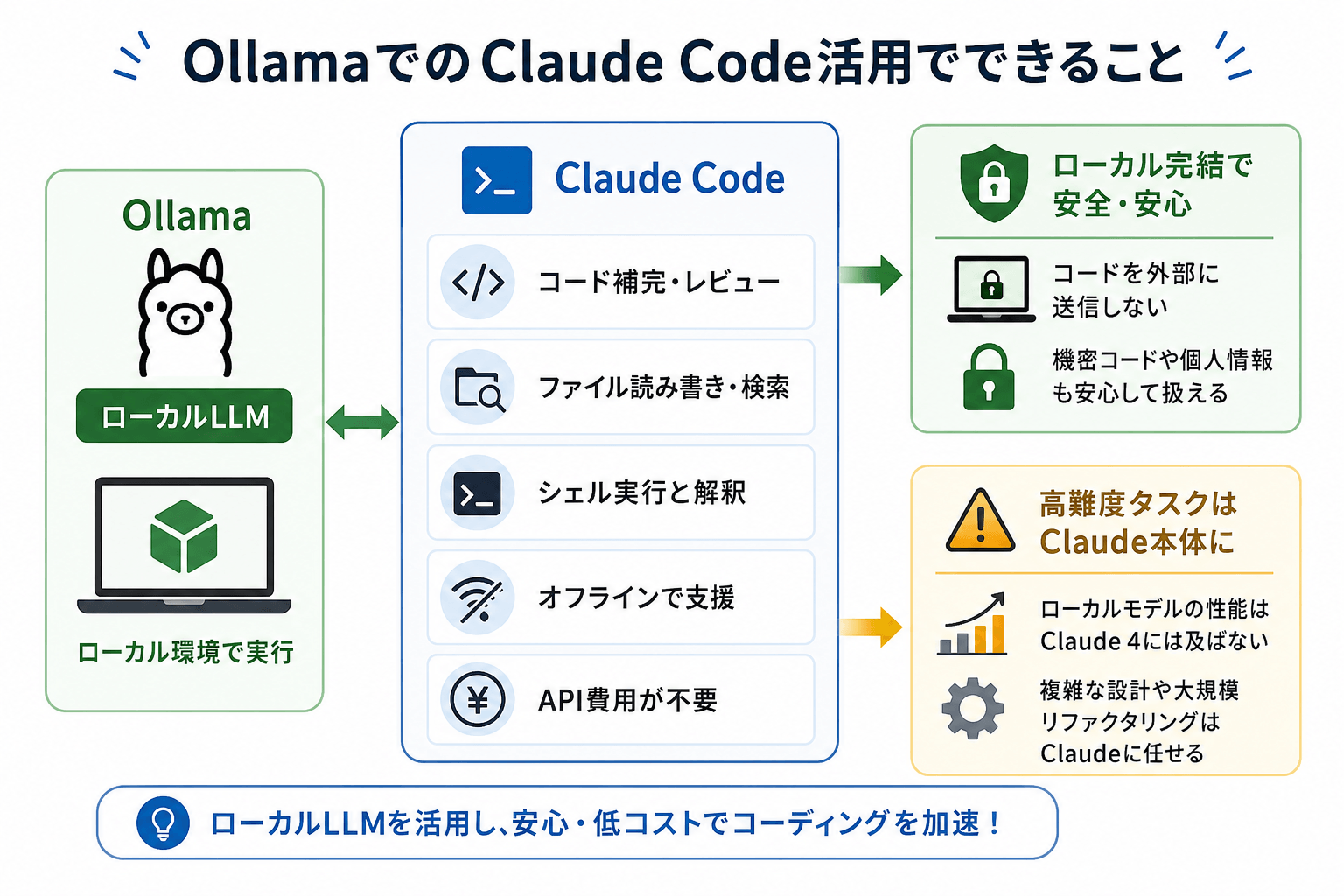
OllamaをClaude Codeに接続すると、ローカルLLMをコーディング補助に活用できます。
具体的には、次のような作業が可能です。
- コード補完・コードレビューのローカル処理
- プロジェクト内ファイル読み書きや検索
- シェルコマンドの実行と結果の解析
- オフライン環境でのコーディング支援
- API料金を抑えた繰り返しタスクの実行
なかでも注目したいのが、コードをクラウドに送信せずに処理できる点です。社内システムや個人情報を含むプロジェクトでも、ローカル環境だけで作業を完結できます。
また、軽量モデルを利用すれば、簡単なコード生成や定型作業を高速に処理できます。API従量課金を抑えながら試行錯誤しやすい点も魅力です。
ただし、Ollama上で動作するローカルモデルは、Claude Sonnet 4やClaude Opus 4などの推論性能には及ばない場合があります。
たとえば、次のような高度な作業では、Claude本体の方が高精度です。
- 複雑なアーキテクチャ設計
- 大規模リファクタリング
- 長文コンテキストを含む解析
- 高度な設計レビュー
そのため、ローカルモデルとClaude本体を用途ごとに使い分ける構成が現実的です。
そもそもClaude Codeでできることをより詳しく知りたい人は、次の記事を参考にしてください。

OllamaでClaude Codeは使うべき?
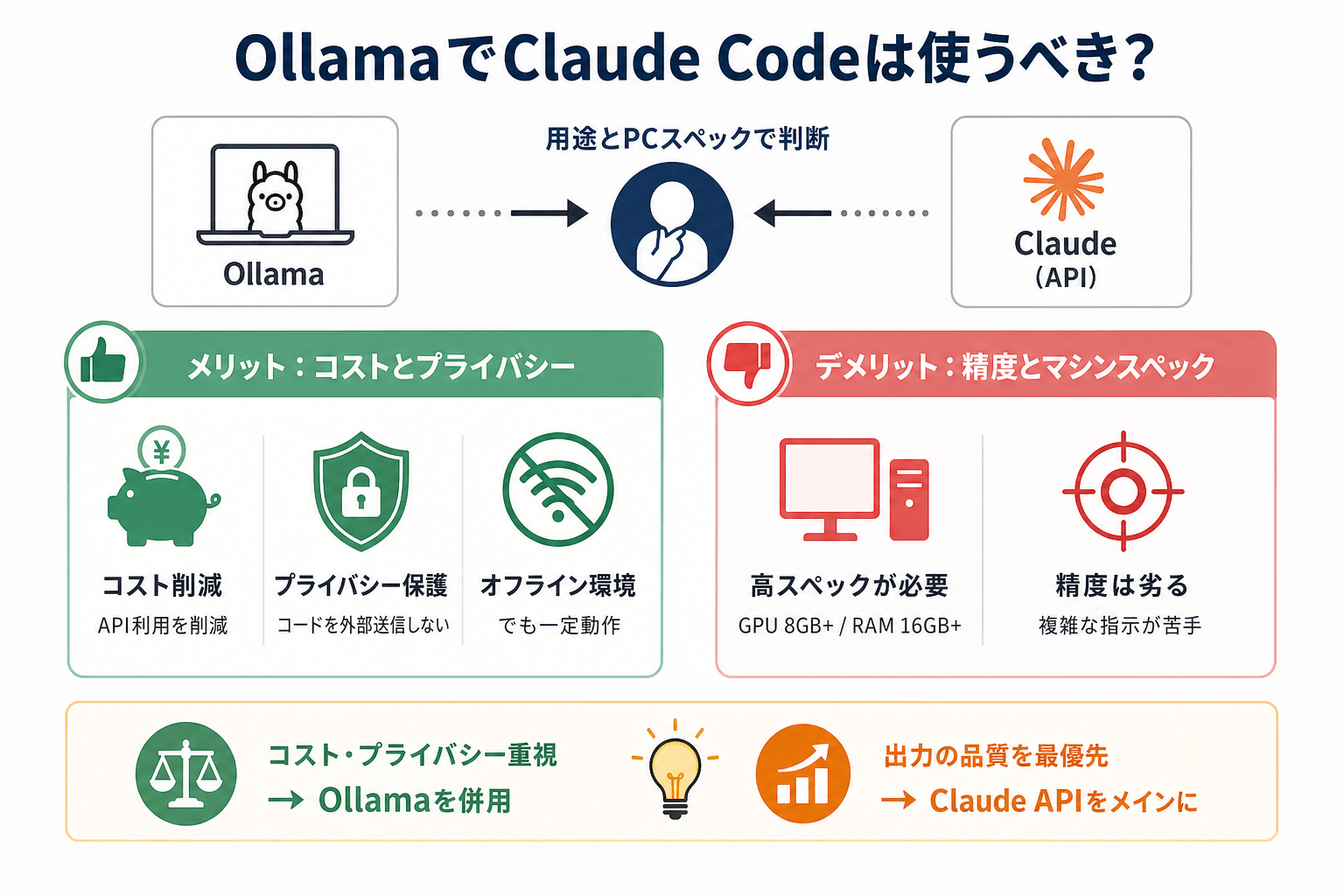
Ollamaとの組み合わせが向いているかどうかは、用途とPCスペックによって変わります。
ここからは下記のメリット・デメリット別に、判断のポイントを解説します。
メリットはコストとプライバシー
OllamaをClaude Codeに組み合わせる最大のメリットは、コスト削減とプライバシー保護の2点です。
たとえば、コード補完やテスト生成などの単純な処理をローカルモデルへ任せることで、Claude APIへのリクエスト回数を大幅に減らせます。日常的に大量のコード生成を行う場合、API利用料を抑えやすくなります。
また、ローカル環境で処理が完結するため、コードを外部サーバーへ送信せずに済む点も大きな利点です。
金融システムや医療系アプリなど、ソースコードの外部送信が規制されている環境でも活用できます。
とくに次のような環境では相性が良いです。
- 社内システム開発
- 金融・医療系システム
- 機密情報を扱うプロジェクト
- オフライン開発環境
さらに、インターネット接続が不安定な場所でも一定の作業を継続できます。出張先や移動中の開発用途にも向いています。
デメリットは精度とマシンスペック
OllamaでローカルLLMを動かすには、一定以上のPCスペックが必要です。一般的には、次のような構成が推奨されます。
| モデル規模 | 推奨スペックの目安 |
|---|---|
| 3B〜5B | RAM 8GB程度 |
| 7B | VRAM 8GB以上 |
| 13B以上 | VRAM 16GB以上 |
スペックが不足すると、応答に時間がかかったり、動作が不安定になったりする場合があります。
また、ローカルモデルはClaude Sonnet 4やClaude Opus 4と比べると、複雑な指示理解や長文処理が苦手な傾向があります。たとえば、複数ファイルを横断する大規模リファクタリングでは、コンテキストを正確に把握できず、不適切なコードを生成するケースもあります。
そのため、次の使い分けが現実的です。
- コストやプライバシー重視 → Ollama併用
- 精度や品質重視 → Claude API中心
まずは軽量モデルで試し、自分の開発スタイルに合うか確認するとよいでしょう。
【OS別】OllamaでClaude Codeを使う手順
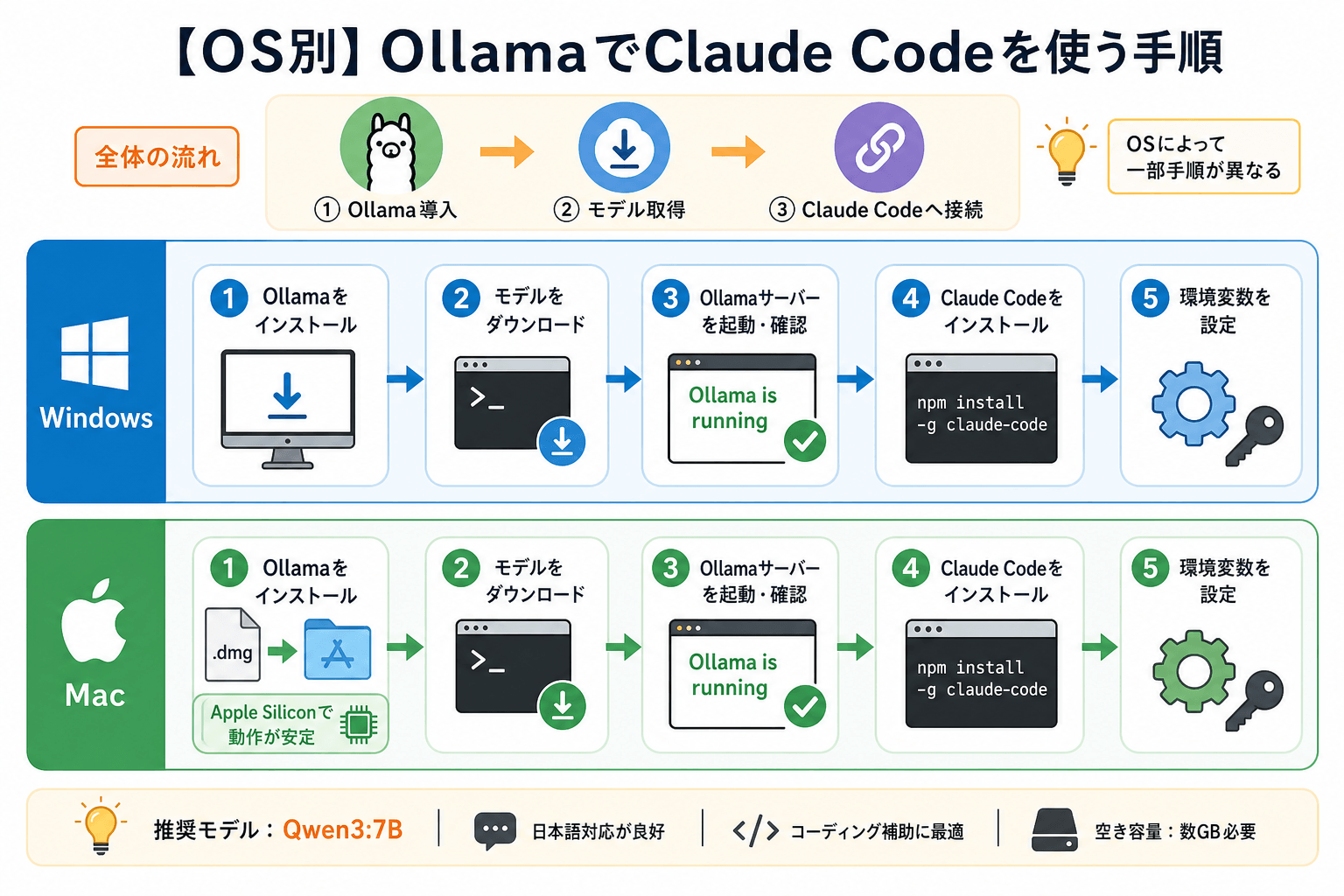
環境構築の流れは「Ollama導入→モデル取得→Claude Codeへの接続」の順番で進めます。OSによって一部の手順が異なるため、使用しているOSに合わせて確認してください。
ここからは下記のOS別に、手順を解説します。
Windowsでの利用手順
Windowsでの環境構築は、以下の手順で進めます。
ステップ1:Ollamaをインストールする
Ollamaの公式サイトにアクセスし、Windows用インストーラー(.exe)をダウンロードします。ダウンロード後、インストーラーを実行し、画面の案内に沿って進めればインストールは完了です。
ステップ2:モデルをダウンロードする
コマンドプロンプトかPowerShellを開き、次のコマンドを実行します。
ollama pull qwen3:7bQwen3:7Bは日本語性能と軽量性のバランスがよく、コーディング用途でも扱いやすいモデルです。なお、モデルのダウンロードには数GB以上の空き容量が必要です。
ステップ3:Ollamaサーバーを起動する
Ollamaをインストールすると、通常はタスクトレイに常駐します。
ブラウザで次のURLへアクセスし、「Ollama is running」と表示されるか確認してください。
http://localhost:11434表示されれば、ローカルAPIサーバーは正常に起動しています。
ステップ4:Claude Codeをインストールする
次にNode.js18以上がインストールされていることを確認し、次のコマンドを実行します。
npm install -g @anthropic-ai/claude-codeステップ5:環境変数を設定する
Windowsのシステム環境変数に ANTHROPIC_API_KEY を追加します。スタートメニューで「環境変数」と検索し、設定画面からAPIキーを登録してください。
設定後は、PowerShellを再起動して反映を確認します。
WindowsでClaude Codeを使う方法を詳しく知りたい人は、次の記事を参考にしてください。

Mac環境での利用手順
Mac環境での構築手順は次のとおりです。
ステップ1:Ollamaをインストールする
Ollamaの公式サイトからmacOS用のインストーラー(.dmg)をダウンロードします。ダウンロード後、アプリケーションフォルダへドラッグすればインストール完了です。Apple SiliconのMacでは、GPU統合メモリを利用できるためローカルLLMを比較的快適に動かせます。
ステップ2:モデルをダウンロードする
ターミナルを開いて次のコマンドを実行します。
ollama pull qwen3:7bM1・M2・M3チップ搭載のMacでは、16GB以上のメモリがあれば13Bクラスのモデルも動作しやすくなります。
ステップ3:Ollamaサーバーの確認
Ollamaアプリを起動すると、メニューバーにアイコンが表示されます。ターミナルで次のコマンドを実行し、起動状態を確認してください。
ollama listダウンロード済みのモデル一覧が表示されれば、サーバーは正常に動いています。
ステップ4:Claude Codeをインストールする
ターミナルで次のコマンドを実行します。
npm install -g @anthropic-ai/claude-codeステップ5:APIキーを設定する
~/.zshrc または ~/.bash_profile に次の行を追加します。
export ANTHROPIC_API_KEY="your-api-key-here"ファイルを保存後、source ~/.zshrc を実行して設定を反映させてください。
MacでClaude Codeを使う方法を詳しく知りたい人は、次の記事を参考にしてください。

Claude CodeにOllamaモデルを接続する設定
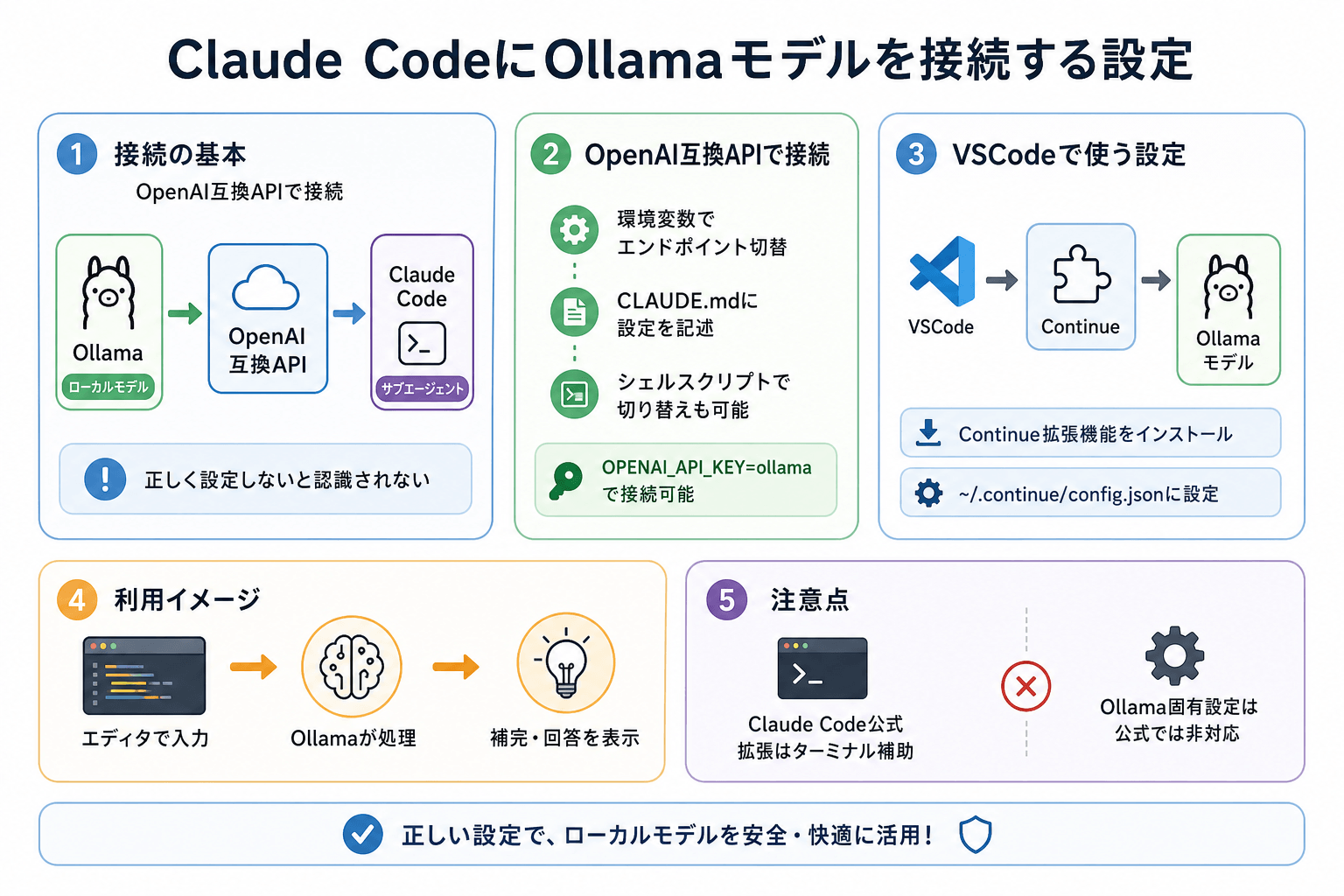
OllamaとClaude Codeを連携させるには、OpenAI互換APIを経由した設定が必要です。設定が正しく行われていないと、Claude Code側からローカルモデルを認識できません。
ここからは次の2つの設定方法を解説します。
OpenAI互換APIでの接続方法
OllamaはOpenAI互換を標準で提供しています。
そのため、環境変数を設定することで、Claude Codeや各種ツールからOllama上のローカルモデルを呼び出せます。
ただし、2026年5月時点ではClaude Code本体をOllamaへ置き換える構成は一般的ではありません。ローカルモデルを補助的に利用する運用が現実的です。
まずは、環境変数を設定します。
export OLLAMA_HOST=http://localhost:11434
export OPENAI_API_BASE=http://localhost:11434/v1
export OPENAI_API_KEY=ollamaOPENAI_API_KEY はダミー値でも問題ありません。OpenAI互換APIを利用するツールでは、キー入力が必須になっている場合があるためです。
さらに、プロジェクト内の CLAUDE.md にローカルモデル利用方針を記述しておくと、役割分担を整理しやすくなります。
# ローカルモデル設定
OLLAMA_BASE_URL=http://localhost:11434/v1
LOCAL_MODEL=qwen3:7b
# 軽量タスクはローカルモデルを使用
# コード補完・コメント生成などをOllamaに委譲このように設定しておくことで、以下をローカルモデルへ任せやすくなります。
- コード補完
- コメント生成
- 定型処理
一方で、複雑な設計レビューや長文解析はClaude本体へ処理させる構成がおすすめです。
VSCodeから使う場合の設定
Visual Studio Code(VSCode)からClaude CodeとOllamaを組み合わせて使う場合は、拡張機能の活用が有効です。
とくにContinueはOllamaとの連携実績が多く、ローカルLLM環境を構築しやすい拡張機能として知られています。
Continueをインストール後、設定ファイル(~/.continue/config.json)に次のような内容を追加します。
{
"models": [
{
"title": "Qwen3 Local",
"provider": "ollama",
"model": "qwen3:7b",
"apiBase": "http://localhost:11434"
}
]
}設定後にVSCodeを再起動し、Continueパネルでモデルが表示されるか確認してください。
正常に接続されると、エディタ上で以下のような機能をローカルモデルで利用できます。
- コード補完
- コード生成
- 質問応答
- リファクタリング補助
なお、Claude Code公式のVSCode拡張機能は基本的にCLI操作の補助を目的としています。そのため、Ollamaとの直接連携機能は限定的です。現状では、Continueなどのサードパーティ製拡張を併用する構成が現実的といえます。
VS CodeでのClaude Code活用法を詳しく知りたい人は、次の記事を参考にしてください。
OllamaでClaude Codeの動作が遅い時の対処法
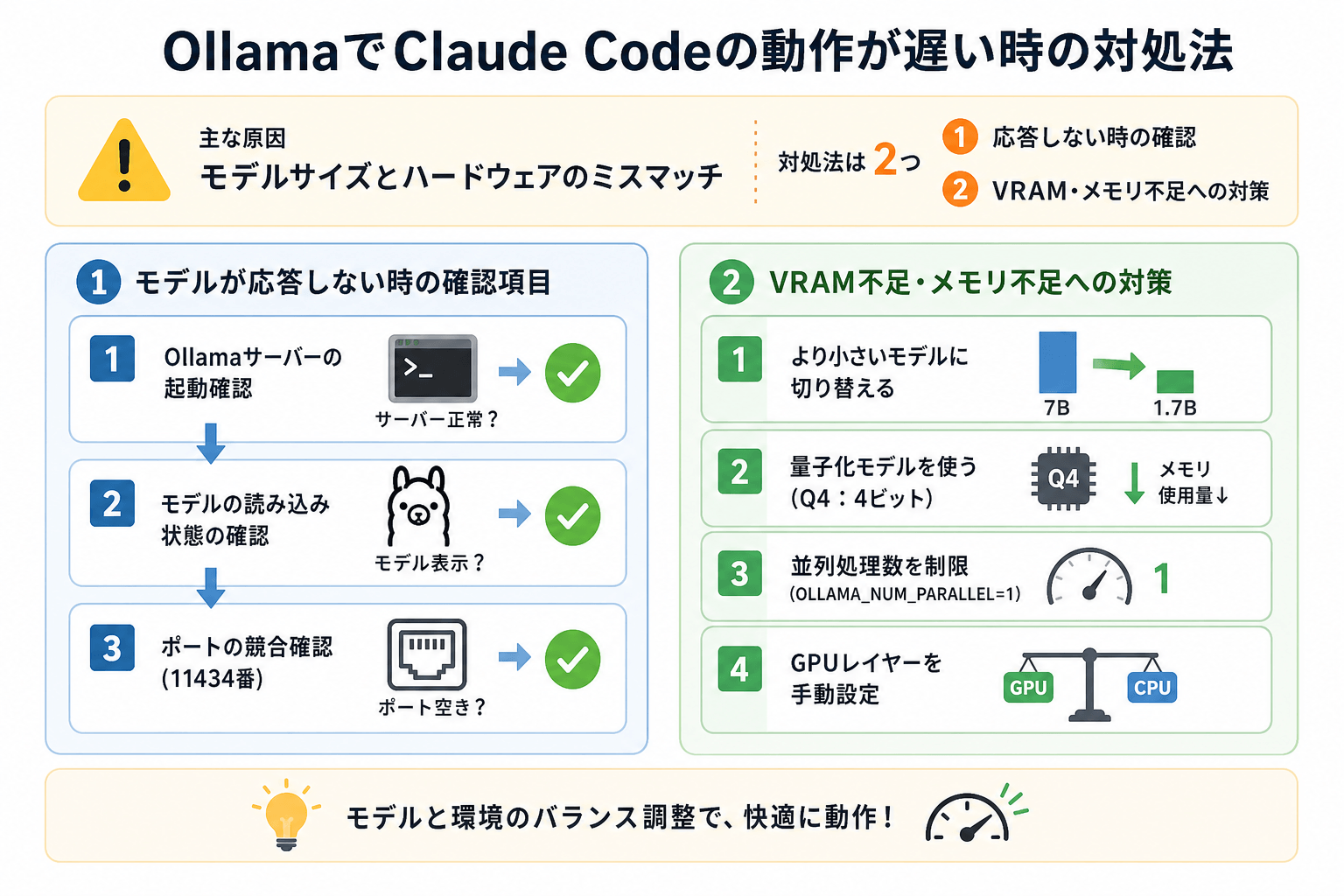
ローカルモデルの動作が遅くなる原因の多くは、モデルサイズとPCスペックのミスマッチです。
ここからは次の2つの対処法を解説します。
モデルが応答しないときの確認項目
モデルが正常に応答しない場合、まず次の項目を順番に確認してください。
Ollamaサーバーの起動確認
ターミナルで次のコマンドを実行し、サーバーが動いているかを確認します。
curl http://localhost:11434/api/tagsモデル一覧がJSON形式で返ってくれば正常です。何も表示されない場合は、Ollamaを再起動してください。
モデルの読み込み状態の確認
現在ロードされているモデルは、次のコマンドで確認できます。
ollama psモデルが表示されない場合は、明示的に起動します。
ollama run qwen3:7b初回起動時は、モデル読み込みに時間がかかることがあります。
ポートの競合確認
Ollamaは通常、11434番ポートを使用します。
別アプリが同じポートを利用していると、正常に起動できません。
Macでは、次のコマンドで確認できます。
lsof -i :11434Windowsではタスクマネージャーやnetstatコマンドで確認してください。
VRAM不足・メモリ不足への対策
VRAM不足している場合は、モデルを軽量化すると改善しやすくなります。
より小さいモデルに切り替える
7Bモデルが遅い場合は、より軽量な1.7Bクラスのモデルを試してください。
ollama pull qwen3:1.7b1.7Bモデルなら8GBのRAMでも比較的快適に動作します。ただし、軽量モデルは推論精度が下がる傾向があります。
量子化モデルを使う
Ollamaでは量子化モデルを利用することでメモリ消費を抑えられます。
たとえば、4bit量子化モデルは次のように取得できます。
ollama pull qwen3:7b-q4_0量子化モデルは、通常モデルより少ないVRAMで動作しやすい点がメリットです。
Ollamaの並列処理数を制限する
並列処理を減らすことで、メモリ使用量を抑えられる場合があります。
export OLLAMA_NUM_PARALLEL=1とくにメモリ容量が少ないPCでは有効です。
GPUレイヤーを手動設定する
OLLAMA_GPU_LAYERS を設定すると、GPUへ割り当てる処理量を調整できます。 VRAM不足でクラッシュする場合は、GPUレイヤー数を減らすと安定することがあります。
たとえば、GPU負荷を抑えたい場合は次のように設定します。
export OLLAMA_GPU_LAYERS=20PCスペックに合わせて調整しながら、最適な設定を探すのがおすすめです。
Claude Codeが使えるOllama以外のローカルツール
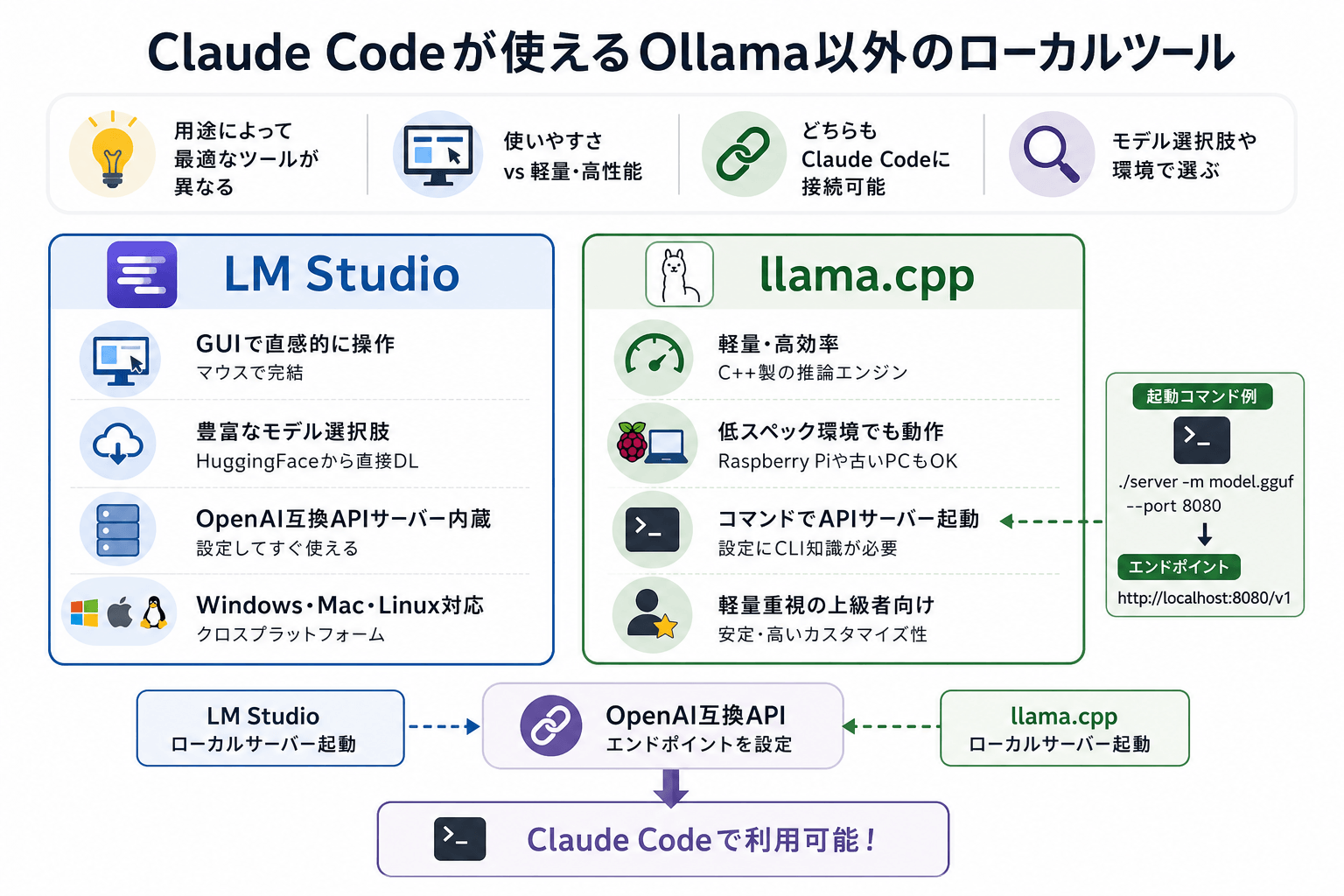
OllamaはローカルLLM実行環境として人気がありますが、ほかにも選択肢があります。用途やPCスペックによっては別のツールのほうが適している場合もあります。
ここからは下記のツール別に、特徴を解説します。
LM Studio
LM Studioは、GUI操作に対応したローカルLLMツールです。
コマンド操作に慣れていない人でも直感的に使えるのが最大の特徴です。モデルのダウンロードから起動まで、基本的にGUI上で完結できます。
また、LM StudioはOpenAI互換のAPIサーバーを内蔵しています。そのため、ローカルサーバーを起動し、APIエンドポイントを設定するだけでClaude Code系ツールと連携可能です。
対応OSは次の3種類です。
- Windows
- macOS
- Linux
さらに、HuggingFace上のモデルを直接検索してダウンロードできるため、モデル選択肢が豊富な点も魅力です。「まずはローカルLLMを試したい」という初心者には、LM Studioの方が導入しやすい場合があります。
llama.cpp
llama.cppは、C++で書かれた軽量なLLM推論エンジンです。
依存ライブラリが少なく、GPUがない環境でもCPUだけでモデルを動かせます。とくに次のような環境と相性があります。
- GPU非搭載PC
- 低スペックPC
- 小型Linux環境
- Raspberry Pi
Claude Code系ツールと連携する場合は、llama.cppのサーバー機能を使います。次のコマンドでAPIサーバーを起動できます。
./llama-server -m qwen3-7b.gguf --port 8080起動後は、OpenAI互換APIとして次のエンドポイントを利用可能です。
http://localhost:8080/v1軽量で安定性も高い一方、設定にはコマンドライン操作の知識が必要です。
そのため、次のように用途に応じて選ぶことをおすすめします
- GUI重視 → LM Studio
- 軽量性重視 → llama.cpp
OllamaでのClaude Code活用によく抱く疑問
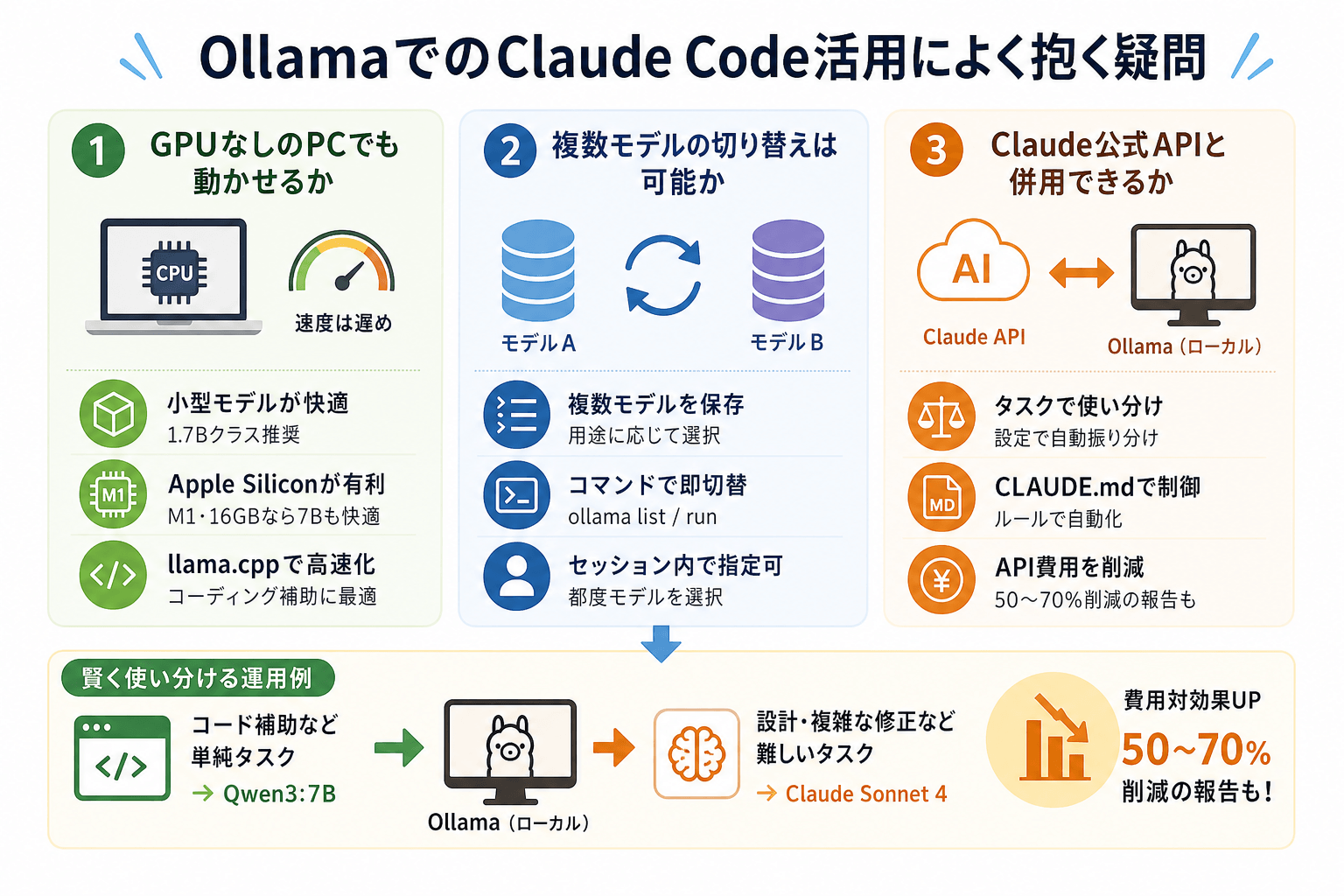
初めてOllamaとClaude Codeを組み合わせる際は、「GPUなしでも動くのか」「複数モデルを使い分けられるのか」といった疑問を持つ人が多くいます。
ここからは次の3つの疑問に回答します。
GPUなしのPCでも動かせるか
GPUなしのPCでもOllamaは動作します。
OllamaはCPU推論にも対応しているため、最低限の環境でもローカルLLMを実行可能です。ただし、CPUのみの場合は推論速度が大きく低下します。
たとえば、7Bモデルを一般的なCPU環境で動かすと、応答生成に時間がかかるケースがあります。そのため、GPUなし環境では、1.7B〜3B程度の軽量モデルから試すのがおすすめです。
また、Apple Silicon搭載Macは、CPUとGPUが統合されているため比較的高速です。とくに、M1・M2・M3 Macでは、16GB以上のメモリがあれば7Bクラスでも快適に動作しやすくなります。
CPU中心で利用する場合は、llama.cppのような軽量推論エンジンを併用する構成も有効です。
複数モデルの切り替えは可能か
Ollamaでは複数のモデルを自由に切り替えられます。
インストール済みモデルは、次のコマンドで確認できます。
ollama listモデルを切り替える場合は、次のように実行します。
ollama run qwen3:7b用途に応じて、次のように複数モデルを使い分ける運用も一般的です。
- コード補完 → Qwen3 7B
- 日本語文書生成 → Gemma系モデル
- 軽量処理 → 1.7Bモデル
ただし、複数モデルを同時に起動すると、RAMやVRAM消費量が増加します。そのため、スペックに余裕がない場合は、基本的に1モデルずつ利用するのがおすすめです。
Claude公式APIと併用できるか
Claude公式APIとOllamaのローカルモデルは、同時に併用できます。
設定次第で「複雑なタスクはClaude API、単純なタスクはOllamaのローカルモデル」という使い分けが可能です。CLAUDE.mdにルールを記述することで、タスクの種類に応じた自動振り分けが実現できます。
実際に、コードのコメント生成やテスト雛形の作成はQwen3:7Bに任せ、アーキテクチャ設計や複雑なバグ修正だけClaude Sonnet 4という使い分けをしているユーザーも多くいます。
このように処理を分担することで、API使用量を抑えながら品質も維持しやすくなります。また、CLAUDE.md にルールを書いておけば、タスクごとの使い分け方針を整理しやすくなります。
Claude CodeでのAPI利用について詳しく知りたい人は、次の記事を参考にしてください。

まとめ
OllamaとClaude Codeの組み合わることで、APIコストを抑えながらローカル環境中心のAI開発環境を構築できます。
とくにコードを外部へ送信したくない人や、繰り返し処理を低コストで実行したい人に向いている構成です。
ただし、Ollamaを利用してもClaude Code自体が完全無料になるわけではありません。実際には、ローカルモデルへ軽量タスクを分担させることで、Claude APIの利用量を削減する使い方が中心になります。
さらにGUIで手軽に使いたい人にはLM Studio、軽量さを優先する場合はllama.cppも選択肢のひとつです。
まずはOllamaをインストールし、Qwen3などの小さいモデルから試してみてください。


