
LLM(大規模言語モデル)とは?仕組みや生成AIとの違いをわかりやすく解説

LLMって何?
生成AIとは何が違うのかな?
生成AIの普及とともに、注目度が増している「LLM(大規模言語モデル)」。ただ、見聞きする機会はあるものの、実施にLLMがどんなものなのかあいまいな人は多いですよね。
そこで今回は生成AIの初心者に向け、LLM(大規模言語モデル)とは何かをわかりやすく解説します。生成AIとの違いやLLMの仕組みも紹介するので、ぜひ参考にしてください。
- LLMとは言語処理能力を持つAIモデル
- GPTやGemini、Claudeなどが代表的
- LLMには課題があることも知っておこう
『生成AIに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- 生成AIに作業や仕事を任せる方法
- ChatGPTなどの生成AIを使いこなすたった1つのコツ
- 業務効率化や収入獲得に生成AIを活かす体験ワーク
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。
参加者には限定で「生成AI活用に役立つ7大特典」をプレゼント中🎁

この時間が、あなたを変える大きなきっかけになりますよ。
本記事を音声で聴く
LLM(大規模言語モデル)とは

LLM(Large Language Models:大規模言語モデル)とは、人間の言語データを膨大に学習し、言葉を理解・生成する能力を身につけたAIモデルです。AIモデルは、与えた入力データを処理し、出力データを返すプログラムを指します。
LLMは、入力された文章の意味や指示内容を把握し、それに対応した自然な文章を出力します。こうした言語処理能力は、Web上の膨大なテキストデータを学習する過程で獲得したもの。人間が言葉を習得するプロセスに近いです。
たとえば「メール本文を作成する」「英語の文章を翻訳する」といったタスクを、部下に指示を与えるような感覚で自然にこなします。日常生活やビジネスの幅広いシーンで活用されており、LLMへの注目は年々高まっています。
生成AIとの違い
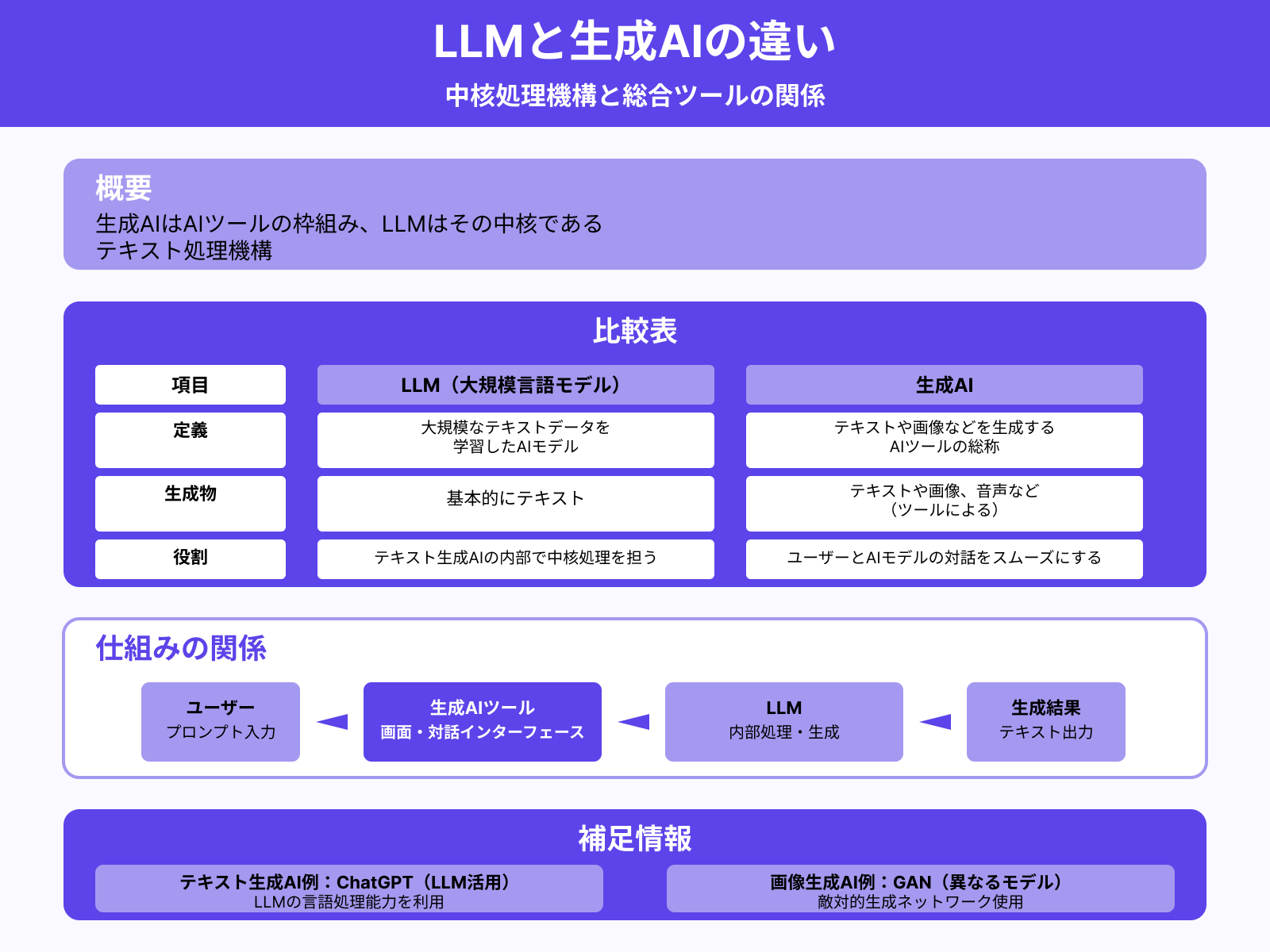
近年では、文章や画像の生成能力を持つ「生成AI」が注目されています。生成AIはあくまでAIツールの枠組みであり、その中核であるテキスト処理機構がLLMです。両者の違いを下表にまとめました。
| 定義 | 生成物 | 役割 | |
|---|---|---|---|
| LLM(大規模言語モデル) | 大規模なテキストデータを 学習したAIモデル | 基本的にテキスト | テキスト生成AIの内部で 中核処理を担う |
| 生成AI | テキストや画像などを 生成するAIツールの総称 | テキストや画像、 音声など(ツールによる) | ユーザーとAIモデルの 対話をスムーズにする |
生成AIは、ユーザーがプロンプト(指示文)を入力・送信し、生成結果を確認するための画面を持つツールです。ただし実際には、入力データの処理や出力データの生成は、内部に組み込まれたAIモデルが担っています。
なかでも、テキスト生成AIに欠かせないAIモデルがLLMです。たとえば「ChatGPT」のような生成AIも、LLMの言語処理能力を利用して文章の生成を行っています。
なお、LLMが活用されているのは主にテキスト生成系の生成AIです。たとえば画像生成AIでは「GAN(敵対的生成ネットワーク)」のように、まったく異なるAIモデルが使われています。
生成AIについてより詳しく知りたい人は、次の記事を参考にしてください。

RAGとの違い
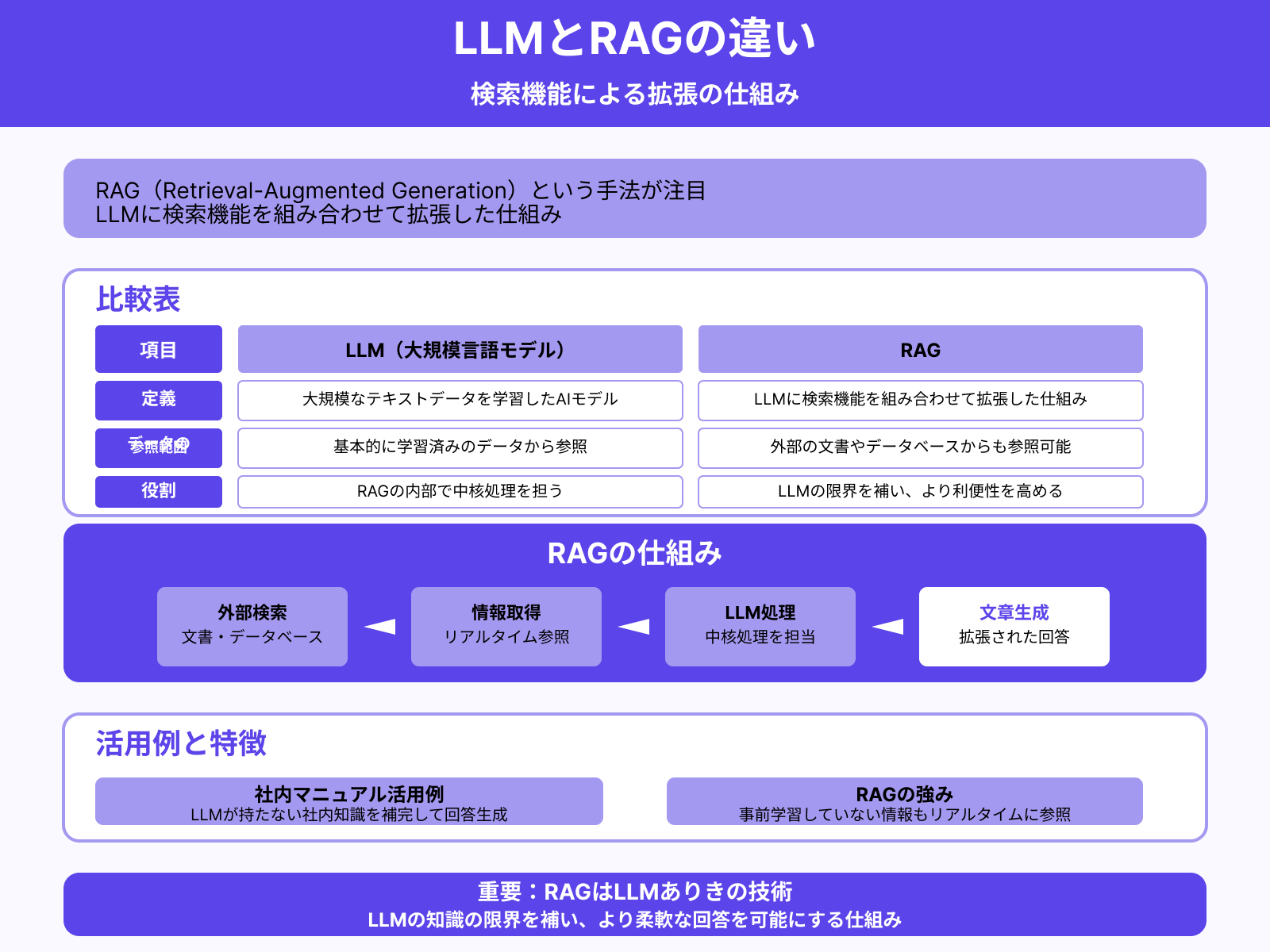
近年では「RAG(Retrieval-Augmented Generation)」という手法も注目を集めています。RAGとは、LLMに検索機能を組み合わせて拡張した仕組みのこと。両者の違いを下表にまとめました。
| 定義 | データの参照範囲 | 役割 | |
|---|---|---|---|
| LLM(大規模言語モデル) | 大規模なテキスト データを学習した AIモデル | 基本的に学習済みの データから参照 | RAGの内部で 中核処理を担う |
| RAG | LLMに検索機能を 組み合わせて 拡張した仕組み | 外部の文書やデータ ベースからも参照可能 | LLMの限界を補い より利便性を高める |
RAGでは、LLMに外部の文書やデータベースから情報を検索させ、その内容をもとに文章を生成します。LLMが事前に学習していない情報でも、リアルタイムに参照できる点が強みです。
たとえば、社内マニュアルにもとづいた回答をLLMにさせたい場合に、RAGが役立ちます。LLMが持っていない社内マニュアルの知識を補いながら、回答を生成できます。
このように、RAGはLLMが持つ知識の限界を補い、より柔軟な回答を可能にする仕組みです。ただし、RAGはあくまでLLMありきの技術であり、LLMなしでは成立しません。両者の関係性を押さえておきましょう。
LLM(大規模言語モデル)が動く仕組み

LLM(大規模言語モデル)が文章生成などのタスクを与えられたとき、大まかに5つのステップに沿って処理を行います。ここではLLMが動く基本的な仕組みを解説します。
- ステップ1:トークンへの分割
- ステップ2:数値ベクトルへの変換
- ステップ3:位置情報の付加(位置エンコーディング)
- ステップ4:Transformerによる文脈の理解
- ステップ5:次の単語を予測して生成
ステップ1:トークンへの分割

まずは、入力されたテキストデータを「トークン」と呼ばれる単位に分割します。トークンとは、単語や句読点など、それ以上分解できない言葉の最小単位です。
たとえば「富士山の高さは?」という質問を入力データとして与えるとします。このとき、多くのLLMは次のようにトークン分割するでしょう。
| 富士山 | の | 高さ | は | ? |
このように、細かいトークンに分割することで、テキストデータの意味や文脈を解析しやすくなります。
ステップ2:数値ベクトルへの変換
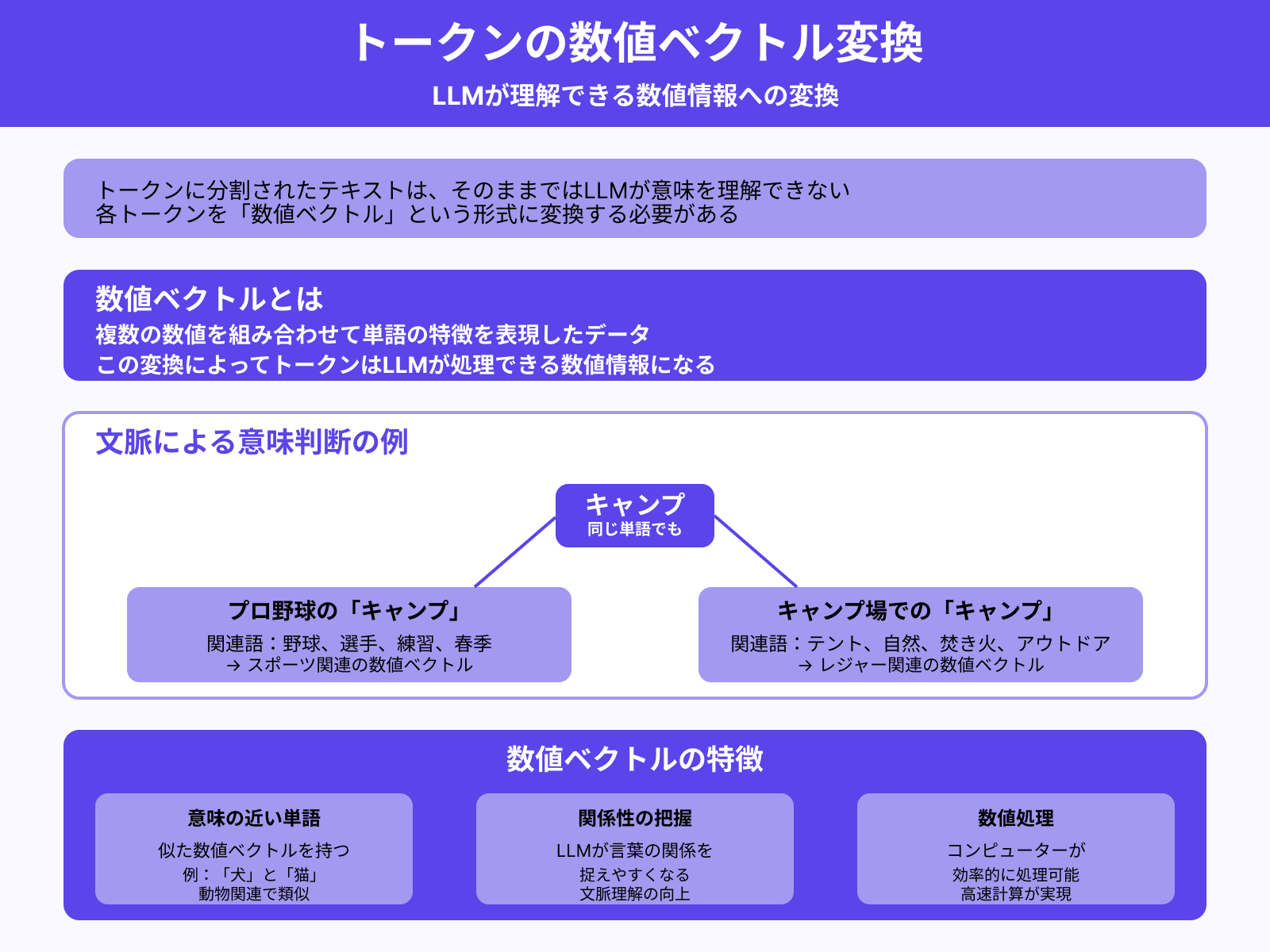
トークンに分割されたテキストは、そのままではLLMが意味を理解できません。そこで、各トークンを「数値ベクトル」という形式に変換します。
数値ベクトルとは、複数の数値を組み合わせて単語の特徴を表現したデータのこと。この変換によって、トークンはLLMが処理できる数値情報になるのです。
たとえば「キャンプ」という言葉に対し、近くに
- 野球関連の単語があればプロ野球の「キャンプ」
- テントや自然に関連する単語があればキャンプ場での「キャンプ」
だと判断します。
意味が近い単語同士は、似た数値ベクトルを持つように設計されています。そのため、LLMは言葉の関係性を捉えやすくなるわけです。
ステップ3:位置情報の付加(位置エンコーディング)
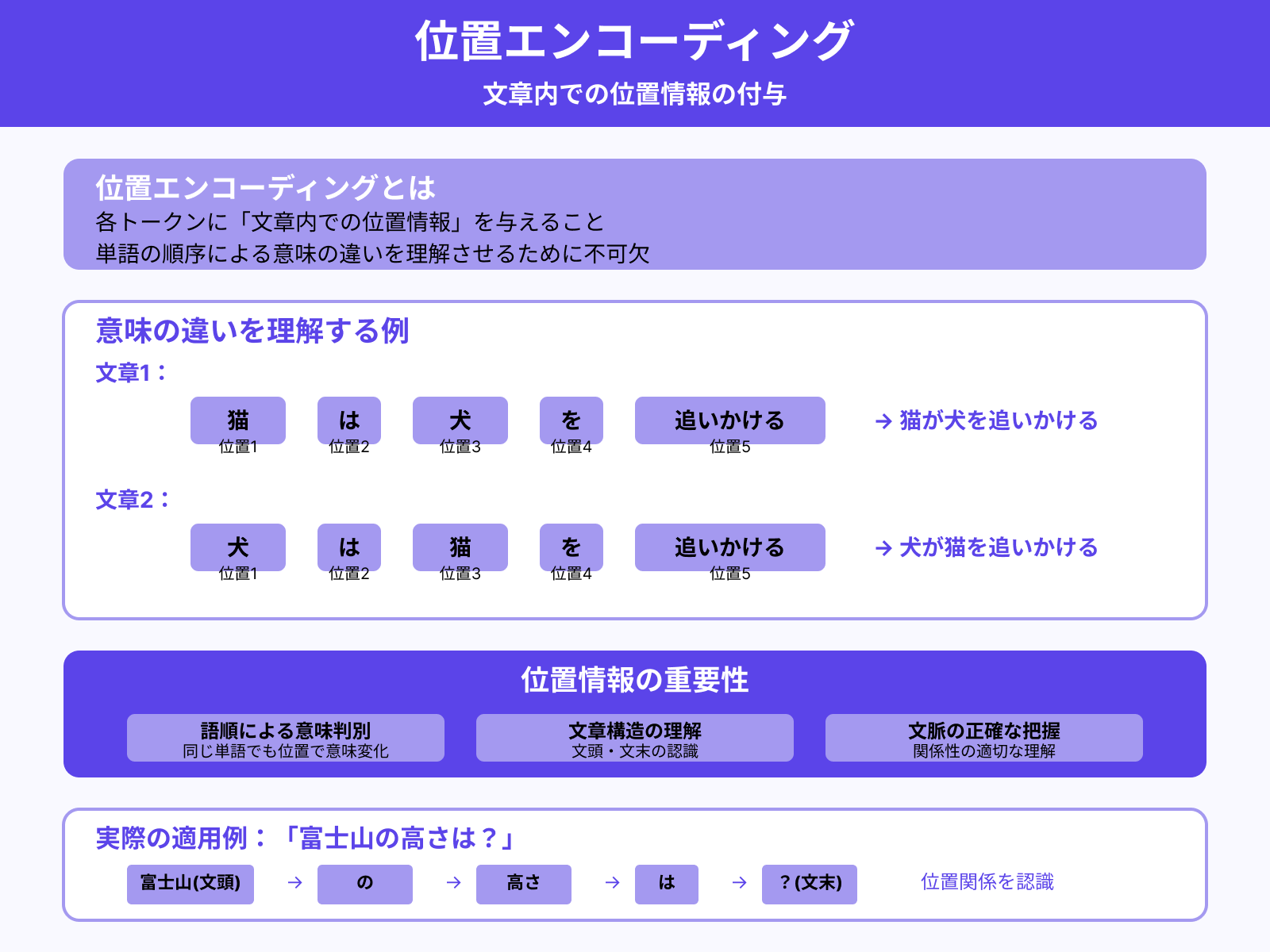
次に、各トークンに対して「位置エンコーディング」を行います。位置エンコーディングとは、各トークンに「文章内での位置情報」を与えること。
たとえば「猫は犬を追いかける」と「犬は猫を追いかける」では、同じトークン構成でも意味が異なります。こうした意味の違いを理解させるために、位置情報は不可欠です。
位置エンコーディングによって、LLMは「富士山」が文頭、「?」が文末といった構造上の位置関係を認識可能になります。
ステップ4:Transformerによる文脈の理解

続いて、位置情報付きの数値ベクトルをもとに「Transformer」で文脈を理解します。Transformerとは、効率的に文脈を理解するための仕組みです。多くのLLMにおいて中核技術となっています。
Transformerは、単語同士の関係性や順序をもとに、文章全体の意味を把握することが可能です。たとえば、「富士山」と「高さ」の関係性から、「具体的な高さを尋ねている」という意図を理解できます。
Transformerを通すことで、LLMはテキストデータの意味や指示内容を的確に読み取れるようになるのです。
ステップ5:次の単語を予測して生成
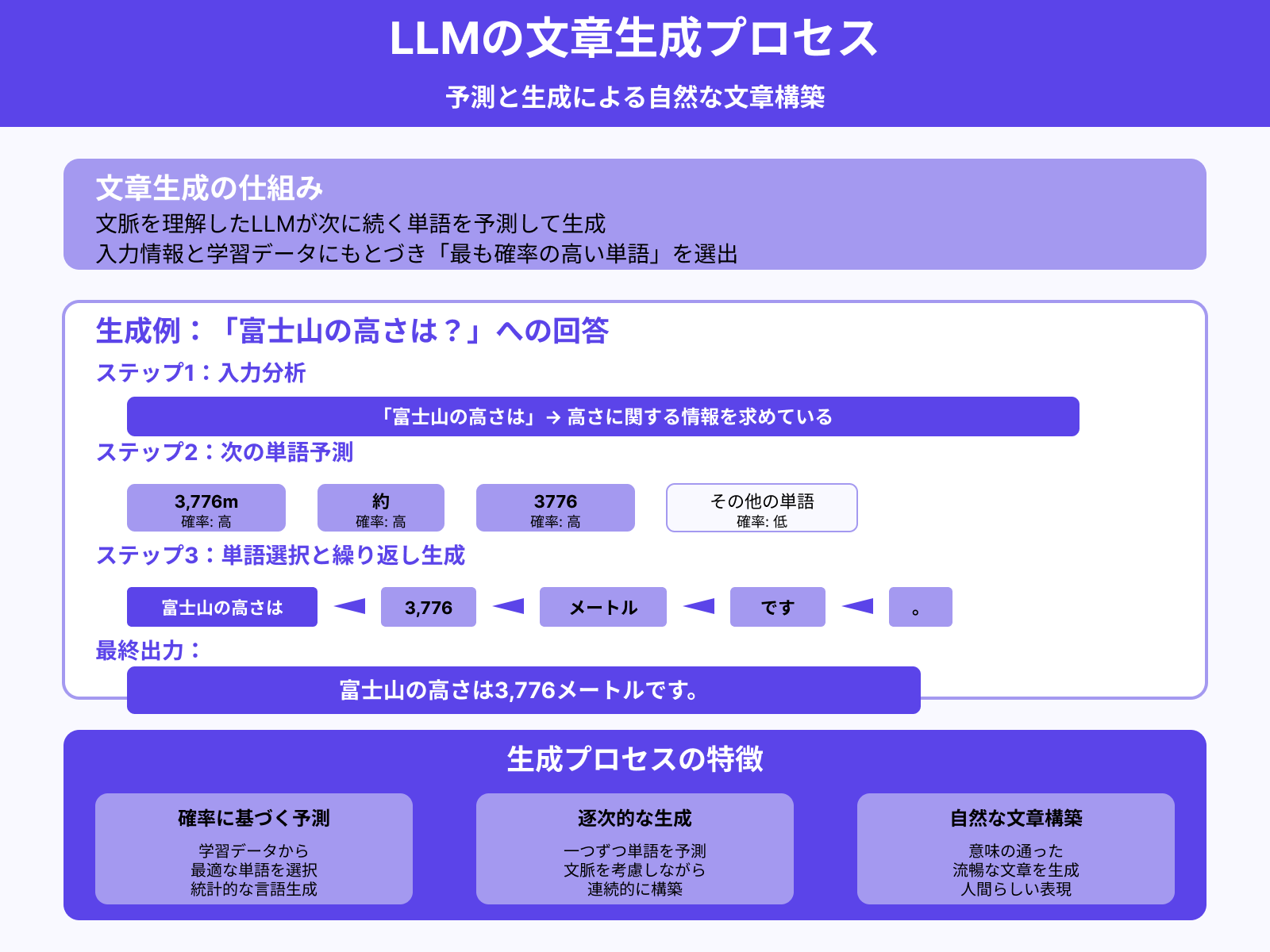
文脈を理解したLLMは、次に続く単語を予測して生成します。これまでの入力情報と学習データにもとづき「最も確率の高い単語」を選び出します。
たとえば「富士山の高さは」に続くと予測されるのは、もちろん富士山の高さに関する単語です。そのため「3,776m」や「約」といった言葉が生成される可能性が高いでしょう。
このように、LLMは予測と生成を繰り返しながら、意味の通った文章を構築します。最終的には「富士山の高さは3,776メートルです。」のように自然な文章を出力するのです。
LLM(大規模言語モデル)の主な種類

現在では特徴や強みもさまざまな、多数のLLM(大規模言語モデル)が登場しています。ここでは代表的な3種類のLLMを紹介します。
GPTシリーズ
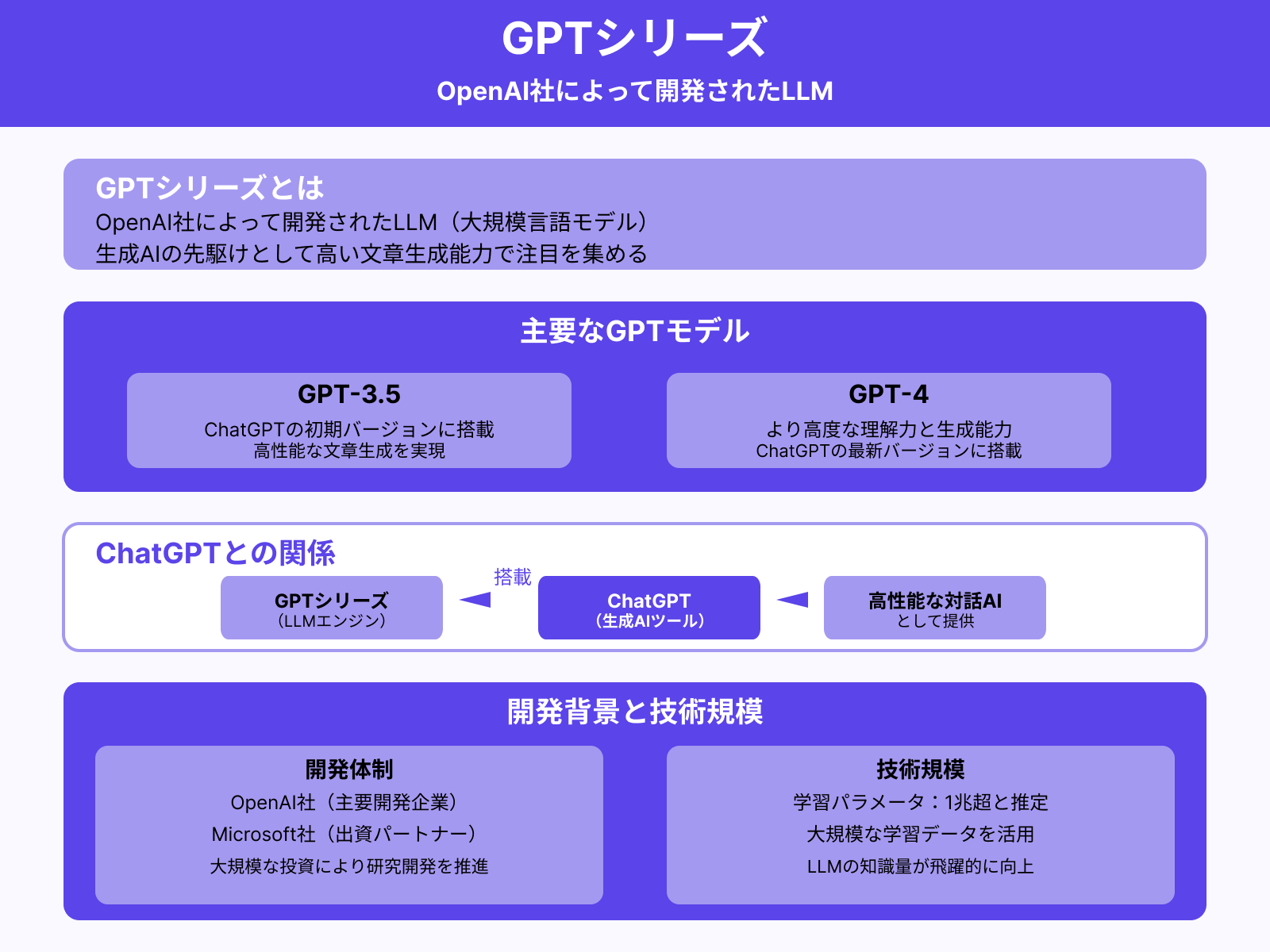
GPTシリーズは、OpenAI社によって開発されたLLMです。GPT-3.5やGPT-4は、生成AIの先駆けともいえる「ChatGPT」にも搭載されており、その高い文章生成能力で注目を集めました。
OpenAI社は、Microsoft社からの出資を受けつつ、大規模な学習データをもとにLLMの精度を高めています。近年のLLMでは、学習パラメータ(LLMの知識量)が1兆を超えるとも推定されます。
文脈を的確に捉え、指示に対して自然な回答を返せる点が、GPTシリーズの大きな強みです。ChatGPTの特徴をより詳しく知りたい人は、次の記事を参考にしてください。

Geminiシリーズ
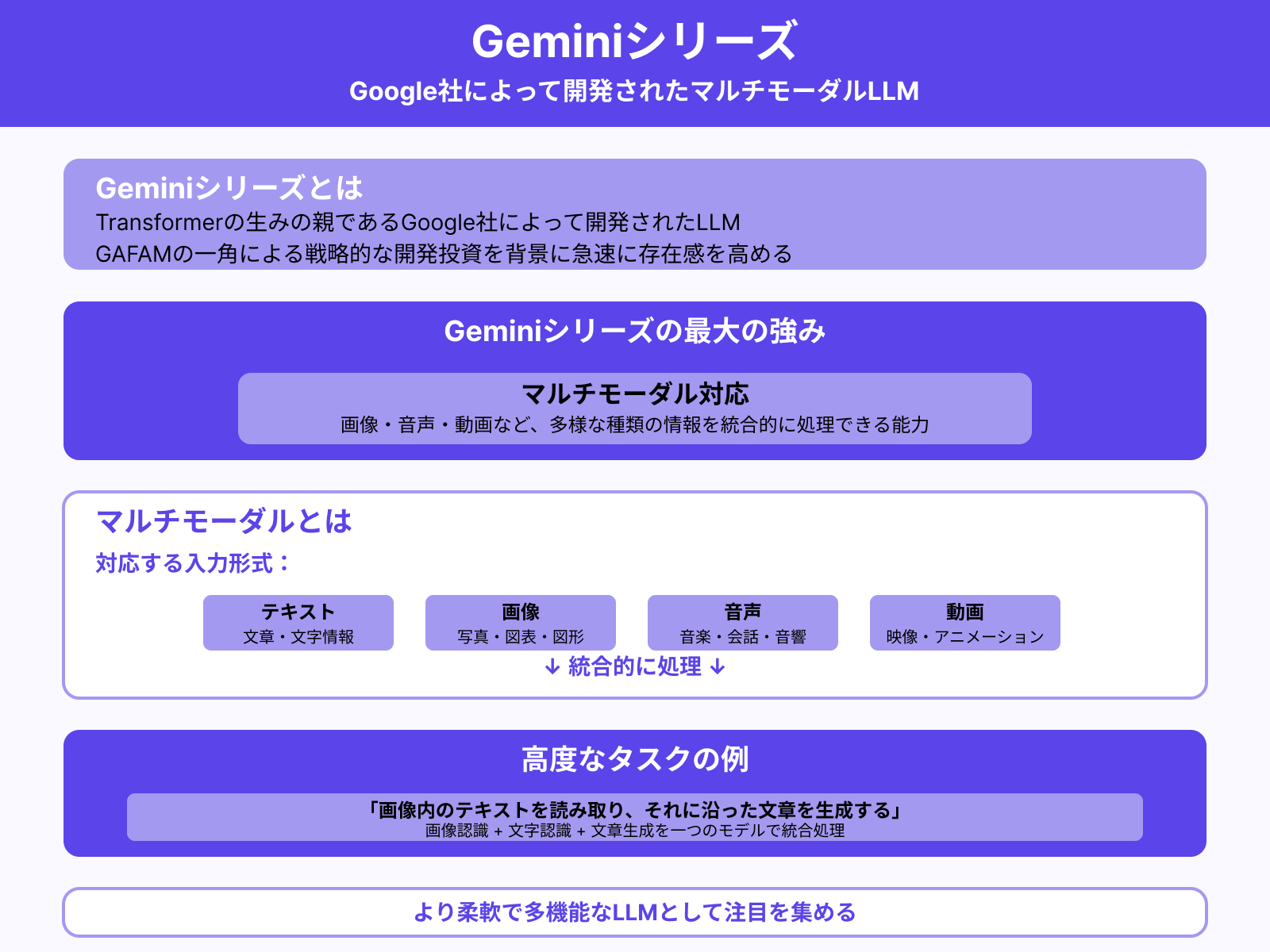
Geminiシリーズは、Transformerの生みの親であるGoogle社によって開発されたLLMです。GAFAMの一角であるGoogle社による戦略的な開発投資を背景に、急速に存在感を高めています。
Geminiシリーズの強みは「マルチモーダル」に対応している点です。マルチモーダルとは、画像や音声、動画など、多様な種類の情報を統合的に処理できる能力のこと。
たとえば「画像内のテキストを読み取り、それに沿った文章を生成する」といった高度なタスクにも対応可能です。Geminiシリーズは、より柔軟で多機能なLLMとして注目を集めています。
Geminiの特徴をより詳しく知りたい人は、次の記事を参考にしてください。

Claudeシリーズ
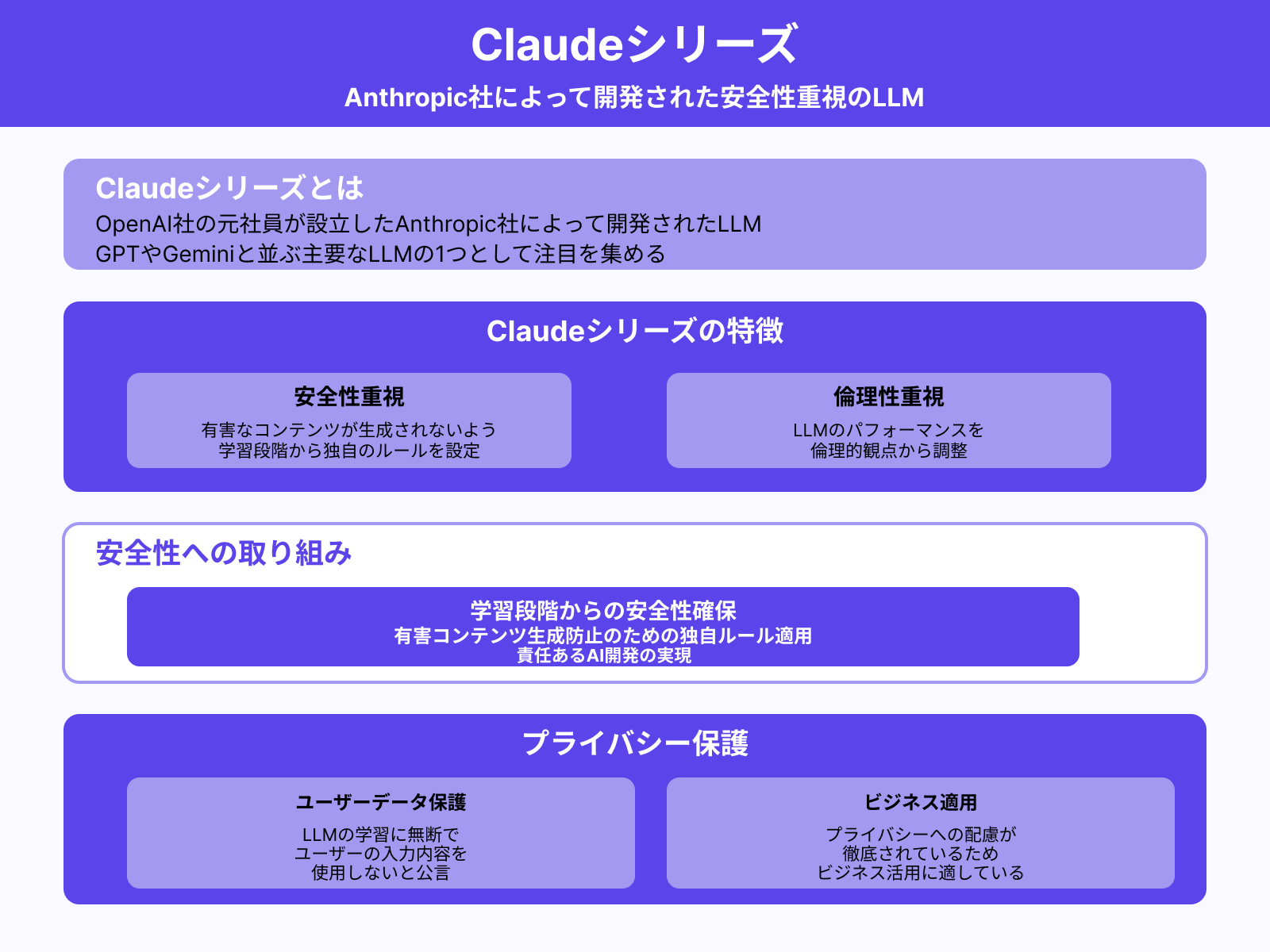
Claudeシリーズは、OpenAI社の元社員が設立したAnthropic社によって開発されたLLMです。GPTやGeminiと並ぶ主要なLLMの1つとして注目を集めています。
Claudeシリーズの大きな特徴は、安全性と倫理性を重視している点です。有害なコンテンツが生成されないよう、学習段階から独自のルールを設けてLLMのパフォーマンスを調整しています。
また、Anthropic社は「LLMの学習に無断でユーザーの入力内容を使用しない」と公言しています。プライバシーへの配慮が徹底されているため、ビジネスでの活用にも適したLLMと言えるでしょう。
LLM(大規模言語モデル)でできること

LLM(大規模言語モデル)は、テキストを扱う幅広い作業に活用できます。主な用途と具体例は次のとおりです。
| 用途 | 具体的な活用例 |
|---|---|
| ビジネス文章の作成 | メール本文の作成、レポートの作成 |
| 情報の要約 | 会議議事録の要約、長文メールの要点整理 |
| 翻訳 | 海外ドキュメントの内容把握、海外取引先とのやり取り |
| アイデア出し | 商品名やキャッチコピーの検討、企画案の検討 |
| プログラミング | コード生成、エラーの原因調査 |
このように、LLMをさまざまな作業に活用することで、業務効率化や新たな価値創造につながります。
なお、LLMでできることは、基本的に生成AIの活用範囲と重なります。生成AIでできることをより詳しく知りたい人は、次の記事を参考にしてください。

LLM(大規模言語モデル)の現状課題

さまざまな用途に使えるLLM(大規模言語モデル)ですが、いくつかの課題も抱えています。ここからは、現状のLLMが抱える課題を、3つにまとめて解説します。
ハルシネーションのリスク

LLMには「ハルシネーション」のリスクがあります。ハルシネーションとは、AI(人工知能)が誤った情報を真実であるかのように出力する現象のこと。
たとえば、架空の人物を実在するかのように紹介する、歴史的な出来事の年代を誤って伝える、といったケースは少なくありません。LLMは自然な文章を生成できますが、内容の正確性には注意が必要です。
LLMの性能が向上すれば、ある程度ハルシネーションが減る可能性はあります。ただし、完全に防ぐのは難しいため、最終的には人間が真偽を確かめることが大切です。
プロンプトインジェクションの脆弱性
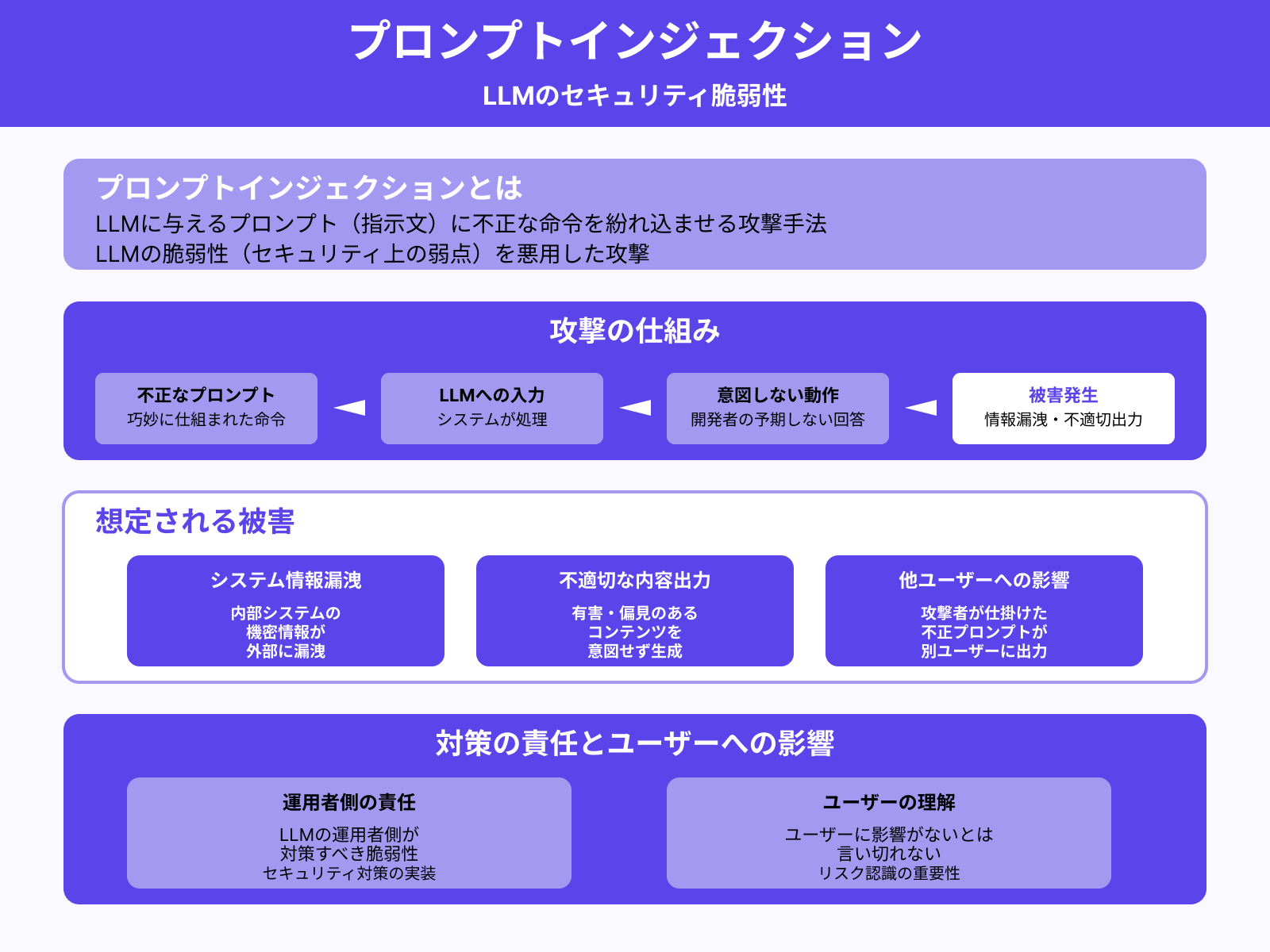
LLMには「プロンプトインジェクション」と呼ばれる脆弱性(セキュリティ上の弱点)があります。これは、LLMに与えるプロンプト(指示文)に不正な命令を紛れ込ませる攻撃手法です。
LLMは巧妙に仕組まれた命令を受けると、開発者の意図しない回答を返すケースがあります。その結果、システム内部の情報が漏洩したり、不適切な内容を出力したりする恐れも。
プロンプトインジェクションはLLMの運用者側が対策すべき脆弱性ですが、ユーザーに影響がないとは言い切れません。たとえば、攻撃者が仕掛けた不正なプロンプトが、別のユーザーに誤って出力されるケースも考えられます。
そのため、プロンプトインジェクションのリスクが存在することを、ユーザー自身も理解しておくことが大切です。プロンプトインジェクションについて詳しくは、次の記事を参考にしてください。

倫理問題の懸念

LLMは、さまざまな倫理問題が懸念されています。例を挙げると、次のとおりです。
- 出力に偏りが含まれることで、差別を助長してしまう
- 既存の著作物に酷似した内容が生成され、著作権を侵害してしまう
- 意図せず個人情報に関わる内容が出力され、プライバシーを侵害してしまう
こうした倫理問題をめぐり、OpenAI社などの開発企業が実際に訴訟の対象となるケースも出ています。LLMを活用するうえでは、利便性だけでなく倫理面への配慮も欠かせません。
生成AIの著作権についてより詳しく知りたい人は、次の記事を参考にしてください。

正しくLLM(大規模言語モデル)を使うには
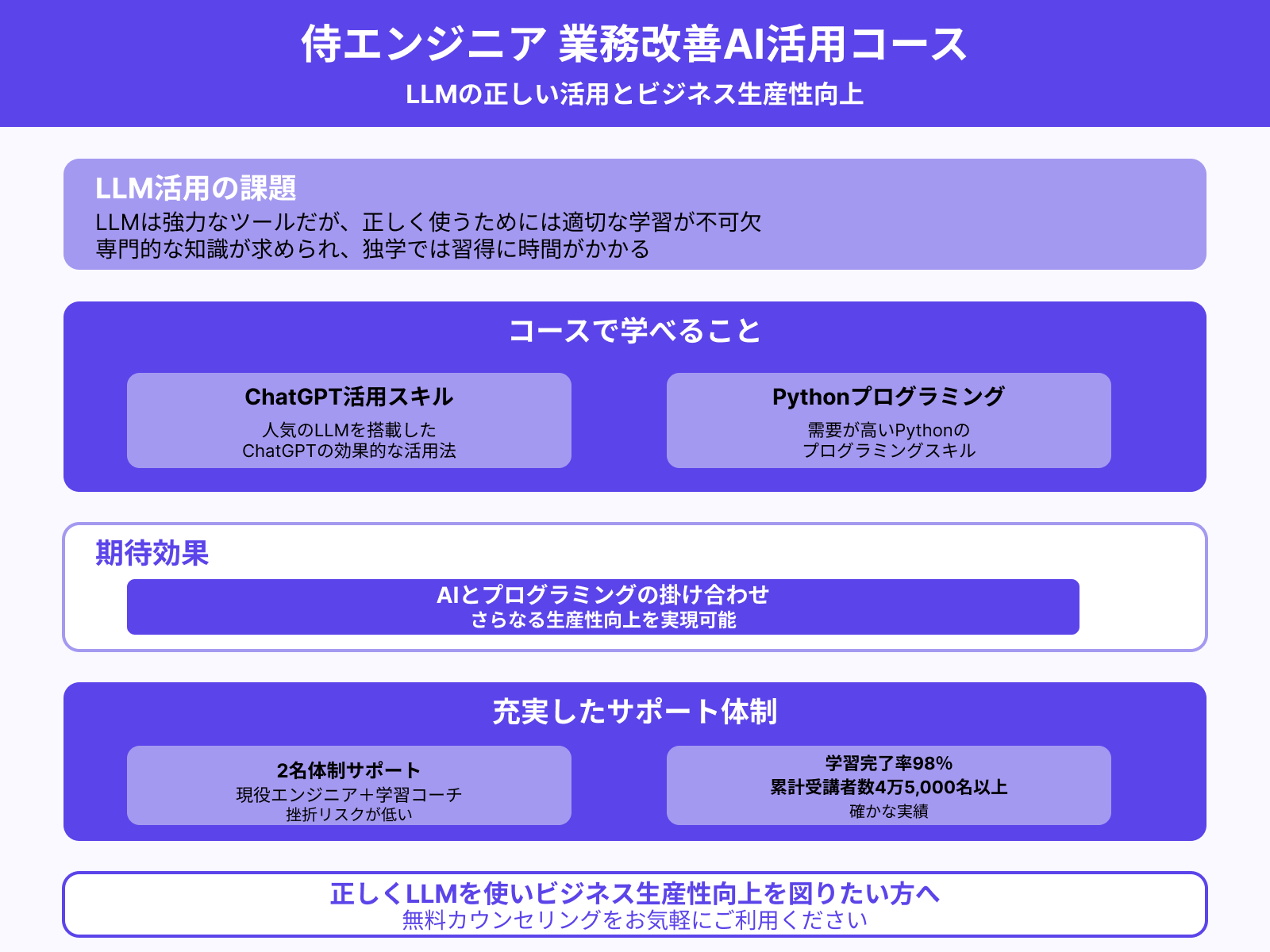
LLM(大規模言語モデル)は強力なツールですが、正しく使うためには適切な学習が不可欠です。注意点やリスクの把握はもちろん、効果的なプロンプトの作り方も学ぶ必要があります。
しかし、LLMの扱いには専門的な知識が求められ、独学では習得に時間がかかります。そこで、おすすめするのが「侍エンジニア」の「業務改善AI活用コース」です。
業務改善AI活用コースでは、人気のLLMを搭載したChatGPTの活用スキルに加え、需要が高いPythonのプログラミングスキルも効率よく学べます。AIとプログラミングの掛け合わせにより、さらなる生産性向上を実現可能です。
侍エンジニアでは、現役エンジニアと学習コーチの2名体制で学習をサポートします。そのため挫折のリスクが低く「受講生の学習完了率98%」「累計受講者数4万5,000名以上」という実績につながっています。
正しくLLMを使いつつ、ビジネスの生産性向上を図りたい人は、無料カウンセリングをお気軽にご利用ください。
まとめ
今回は、LLM(大規模言語モデル)とは何かについて、基本からお伝えしました。
LLMは業務効率化の心強い味方ですが、利用にはリスクをともないます。LLMの価値を最大化するためには、LLMの基本事項を把握し、正しく使うことが大切です。
今回の内容を参考に、ぜひLLMを活用してみてください。


