
Claude Codeに学習させない(オプトアウト)設定方法【デメリットも紹介】

Claude Codeでのやり取りって、学習に使われてるの?
情報漏洩とかが心配…
学習させないようにするにはどうしたらいいの?
Claude Codeを業務や個人開発で使い始めると、入力したコードや会話がどう扱われるのか気になりますよね。とくに業務で利用する場合、社内のソースコードや機密情報が学習に利用されないか、不安に感じる人も多いはずです。
一方で「学習させない設定があるのは知っているけど、そもそも本当に学習に使われているのか分からない」「オプトアウトすると不便になるのでは?」と判断に迷う人も多いでしょう。
そこでこの記事ではメリット・デメリットも交え、Claude Codeに学習させない(オプトアウト)設定方法を解説します。学習させるかを判断するポイントも紹介するので、ぜひ参考にしてください。
Claude Codeの特徴をおさらいしておきたい人は、次の記事を参考にしてください。

- 個人向けプランは初期設定でデータが学習に使われる
- オプトアウト設定で学習利用を停止できる
- API・CLI経由の利用はデフォルトで学習対象外
『ClaudeCodeに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- ClaudeCodeに作業や仕事を任せる方法
- ClaudeCodeを使いこなすたった1つのコツ
- 業務効率化や収入獲得に活かすClaudeCodeの実演
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。この時間が、あなたを変える大きなきっかけになりますよ。
Claude Codeでのやり取りは学習に使われるのか
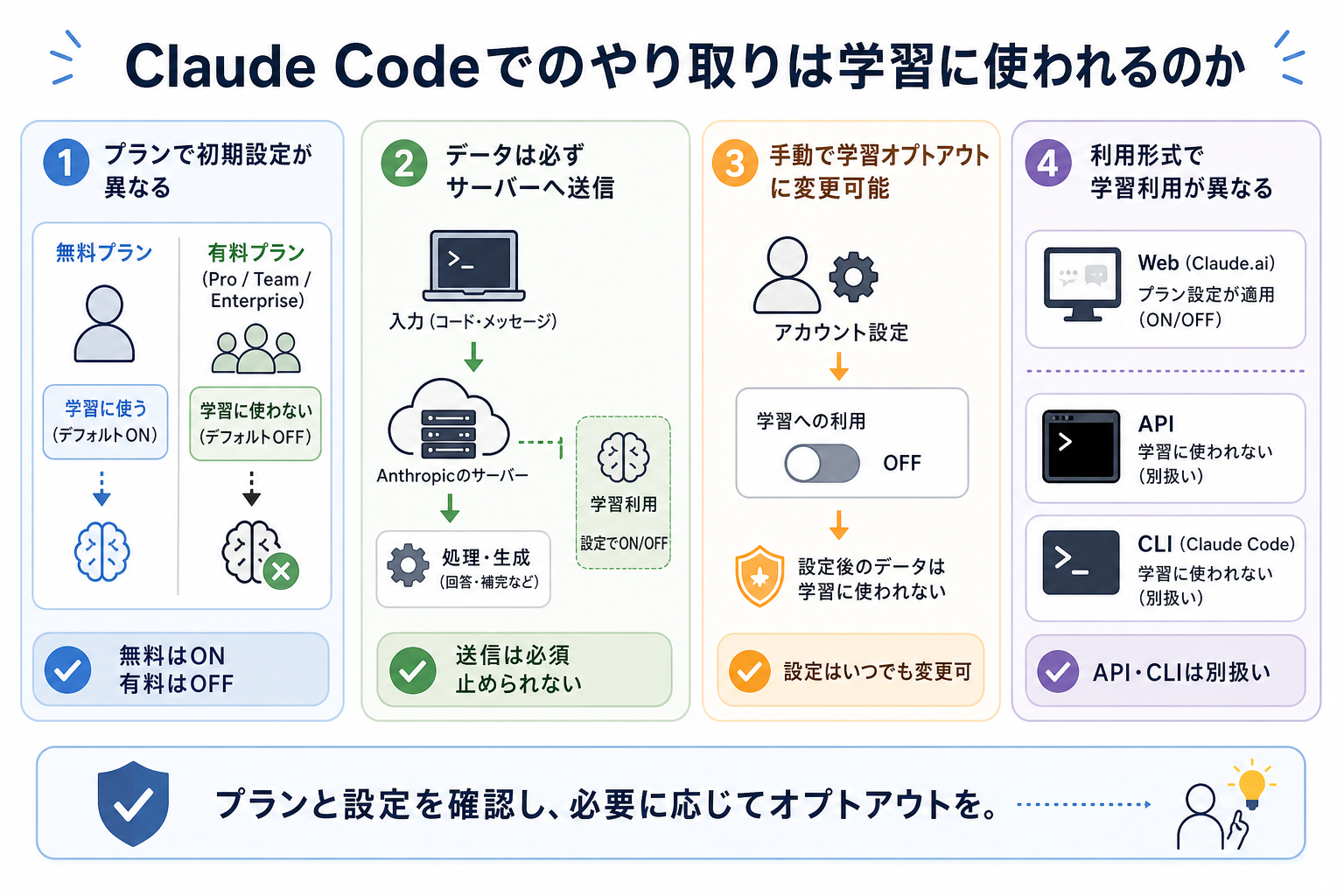
Claude Codeでのやり取りが学習に使われるかどうかは、利用しているプランや設定をはじめ、利用形式によって異なります。
「Claude Codeを使うと、入力したコードがすべて自動で学習に使われる」と思われがちですが、実際にはプランごとに初期設定が異なり、手動でオプトアウトすることも可能です。また、Web版・API・CLIではデータの扱いにも違いがあります。
ここからはClaude Codeにおける学習利用の仕組みを、次の4つに分けて解説します。
プランごとに初期設定が異なる
Claude Codeのデータが学習に利用されるかどうかは、契約しているプランによって初期設定が異なります。
Anthropicの公式情報によると、ProやMaxなどの個人向けプランは2025年9月28日以降、ユーザーがオプトイン(同意)した場合に会話データがモデル改善に利用される仕組みになっています。オプトアウトしていれば学習には使用されません。。
一方、Claude for Work・Enterprise・Educationなどの法人向けプランでは、デフォルトで学習利用がオフになっています。なお、個人向け有料プランのProおよびMaxは、2025年9月以降はオプトイン形式(ユーザーが明示的に許可した場合のみ学習に使用)となっています。
利用プランを確認しないまま使い続けると、意図せず学習対象になっている可能性もあるため、事前に設定を確認しておきましょう。
Claude Codeにおける各プランの特徴をより詳しく知りたい人は、次の記事を参考にしてください。



やりとりのデータ自体は送信される
「学習させない設定にすれば、入力したコードが外部に送信されなくなる」と考える人もいますが、これは正確ではありません。
Claude Codeに入力したコードやメッセージは、回答生成やコード補完を行うためにAnthropicのサーバーへ送信されます。オプトアウト設定で停止できるのは、あくまで「モデルの改善・学習への利用」です。つまり、学習対象外に設定していてもサービス提供のためのデータの送信自体は発生します。
そのため、機密情報を扱う場合は「学習されない=完全にローカルで処理される」という意味ではない点を理解しておくことが重要です。
手動で学習させない設定に変更可
アカウント設定から手動でオプトアウトすれば、学習利用を停止できます。
設定はAnthropicの公式サイトから数分で変更可能です。オプトアウト後に入力したデータは、モデル改善のための学習には使用されません。ただし、設定変更以前に送信したデータには基本的にさかのぼって適用されない点には注意が必要です。気になる場合は、Claude Codeを本格利用する前に設定を確認しておくと安心です。
具体的な設定手順は、この記事の後半で画像付きで解説します。
利用形式における学習利用の違い(API・CLIは別扱い)
Claude CodeをAPIまたはCLI(コマンドラインインターフェース)経由で利用する場合、Web版とはデータの扱いが異なります。
AnthropicのAPIでは、入力データはデフォルトでモデルのトレーニングに使用されません。Claude Code CLIもAPIベースで動作するため、基本的には学習対象外として扱われます。
そのため、業務システムや開発環境へ組み込む用途では、Web版よりもAPI・CLI利用のほうが管理しやすいケースもあります。
ただし、障害調査や不正利用対策など、サービス品質向上の目的で一部データが確認される可能性はあります。利用前には、最新の利用規約やプライバシーポリシーを確認しておきましょう。
Claude CodeでのAPI利用について詳しく知りたい人は、次の記事を参考にしてください。

Claude Codeに学習させない設定手順
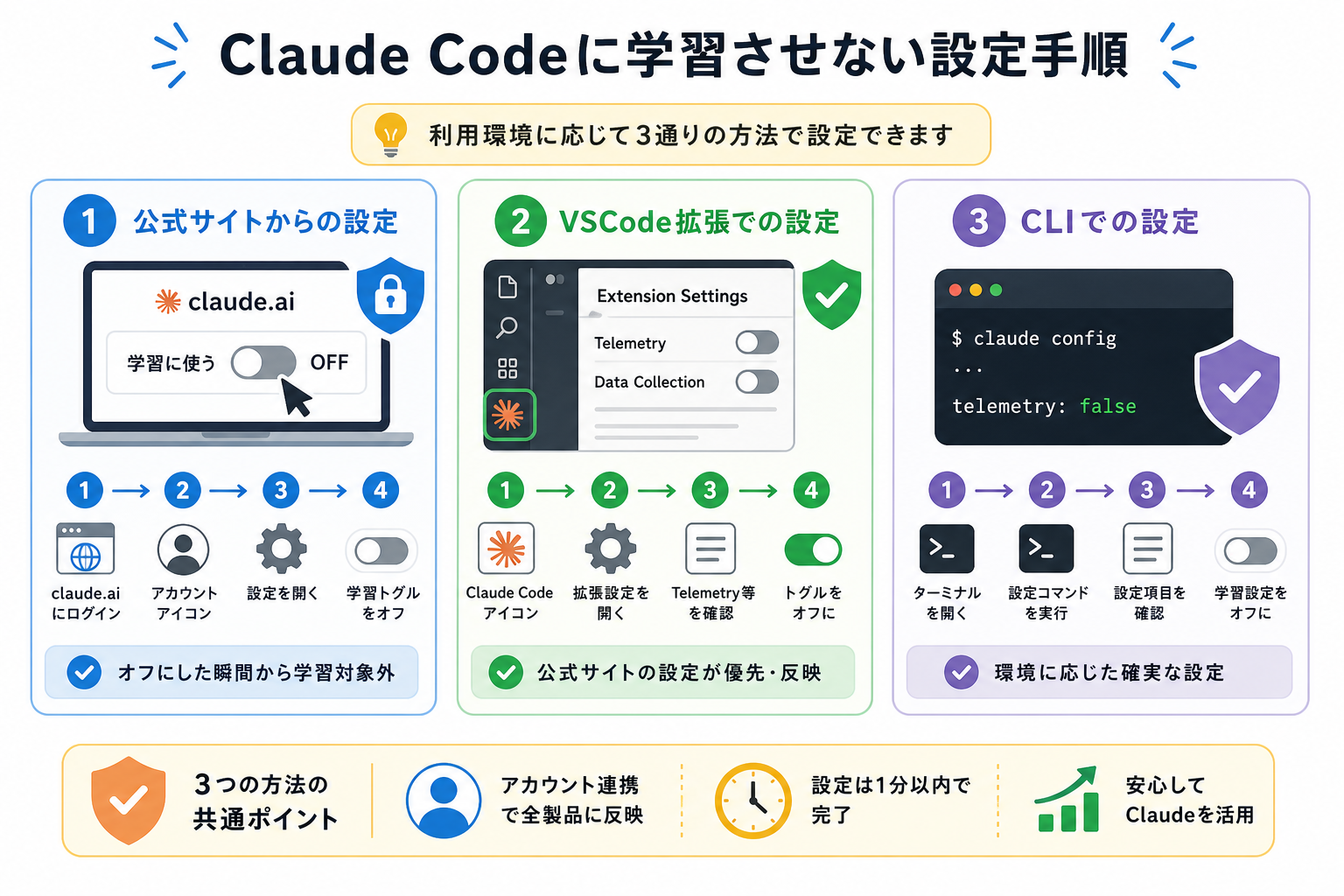
Claude Codeで入力内容を学習に利用されたくない場合は、利用環境に応じて設定を変更できます。主な設定方法は次の3つです。
公式サイトからの設定方法
もっとも簡単な方法は、Anthropicの公式サイトのアカウント設定からオプトアウトする方法です。
- claude.aiにアクセスしてログインする
- 画面左下のアカウントアイコンをクリックする
- 「Settings(設定)」を開く
- 「Privacy」または「Data & Privacy」を選択する
- 「Improve Claude for everyone」トグルがオンになっている場合はオフにする
操作はこれだけです。トグルをオフにすると、それ以降の会話データはモデル改善の学習対象として利用されなくなります。
操作自体は1分ほどで完了するため、Claude Codeを使い始めた段階で設定しておくと安心です。
また、Anthropicのプライバシー設定はアカウント単位で管理されています。そのため、この設定を変更すると、Claude Codeを含む関連サービスにも反映されます。
VSCode拡張での設定手順
VSCode(Visual Studio Code) のClaude Code拡張を利用している場合も、基本的な考え方は同じです。
VSCode拡張はAnthropicのアカウントと連携して動作するため、公式サイト側でオプトアウトを行えば拡張機能側にも反映されます。
そのうえで、下記手順にてVSCode側の設定も確認しておくとより安心です。
- VSCodeを開く
- 左側のサイドバーからClaude Code拡張を選択する
- 歯車アイコンから設定画面を開く
- 「Telemetry」や「Data Collection」関連の項目を確認する
- データ収集に関する設定が有効ならオフにする
なお、拡張機能のバージョンによって設定名が異なる場合があります。設定項目が見つからない場合は、公式ドキュメントもあわせて確認してください。
VS CodeでのClaude Code活用法を詳しく知りたい人は、次の記事を参考にしてください。
CLIでの設定方法
Claude Code CLIはAPIベースで動作するため、基本的には入力データがモデル学習に利用されない仕様です。ただし、使用状況データ(テレメトリ)の送信を抑えたい場合は、環境変数を設定することで無効化できます。
ターミナルで以下のコマンドを実行してください。
“`bash
export DISABLE_TELEMETRY=1
“`
毎回設定するのが面倒な場合は、`.bashrc`または`.zshrc`に追記しておくと便利です。
“`bash
echo ‘export DISABLE_TELEMETRY=1’ >> ~/.zshrc
source ~/.zshrc
“`
これで、シェル起動時に自動で設定が反映されます。
とくに複数のプロジェクトでClaude Code CLIを利用する場合や、業務環境で継続的に使用する場合は、設定ファイルへ追記しておくと管理しやすくなります。
また、企業のCI/CD環境で利用する場合は、組織レベルで環境変数を設定しておくと運用負荷を減らせます。
なお、上記を含めClaude Codeのおすすめ設定を詳しく知りたい人は、次の記事を参考にしてください。

Claude Codeに学習させないメリット
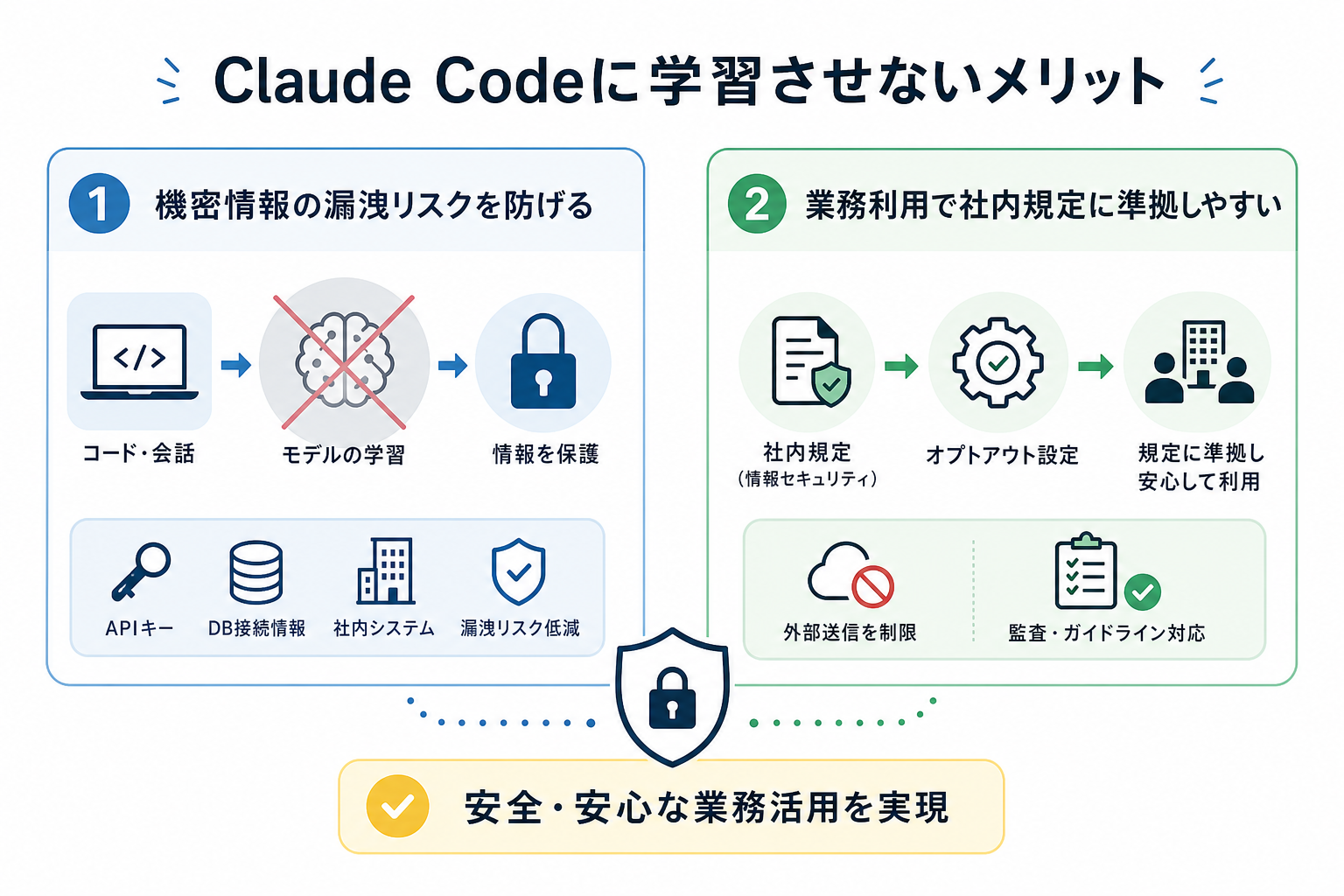
Claude Codeに学習させないようにするメリットは、主に2つあります。ここからは下記のメリットを、それぞれ詳しく解説します。
機密情報の漏洩リスクを防げる
オプトアウトの最大のメリットは、入力したコードや会話内容がモデルの学習に利用されなくなることです。
業務でClaude Codeを利用する場合、ソースコードの中にはAPIキー・データベース接続情報・認証処理・社内システム構成など、外部へ公開すべきでない情報が含まれるケースがあります。
もし、これらがモデル改善用データとして利用されれば、将来的に意図しない形で情報が露出するリスクを完全には否定できません。
たとえば、認証ロジックや社内ツールのコードをそのまま貼り付けてデバッグを依頼するケースでは、機密性の高い情報が含まれる可能性があります。オプトアウト設定を行っておけば、少なくともモデル学習への利用は防げます。
もちろん、オプトアウトしてもデータ送信自体は行われます。しかし、「学習データとして二次利用されない」という点だけでも、セキュリティリスクの低減につながります。
そのため、業務利用や機密情報を扱う用途では、基本的にオプトアウト設定を有効化しておくのがおすすめです。
業務利用で社内規定に準拠しやすい
オプトアウト設定は、企業の情報セキュリティポリシーに対応しやすくなる点でも重要です。
多くの企業では「外部サービスへのデータ送信」や「第三者によるデータ利用」に関するルールを設けています。とくに近年は、生成AI利用ガイドラインを整備する企業が急増しています。
たとえば「顧客情報や機密コードを学習用途に利用させてはならない」といった規定がある場合、オプトアウト設定は実質的に必須です。また、Claude Pro・Team・Enterpriseプランでは、初期状態で学習利用がオフになっているため、業務利用との相性も比較的良好です。
さらに、社内監査やセキュリティチェックの際にも「学習利用を停止済み」と説明できることは大きなメリットになります。
生成AIを安全に業務へ導入するためにも、設定状況を明確にしておくことが重要です。
Claude Codeに学習させないデメリットはある?
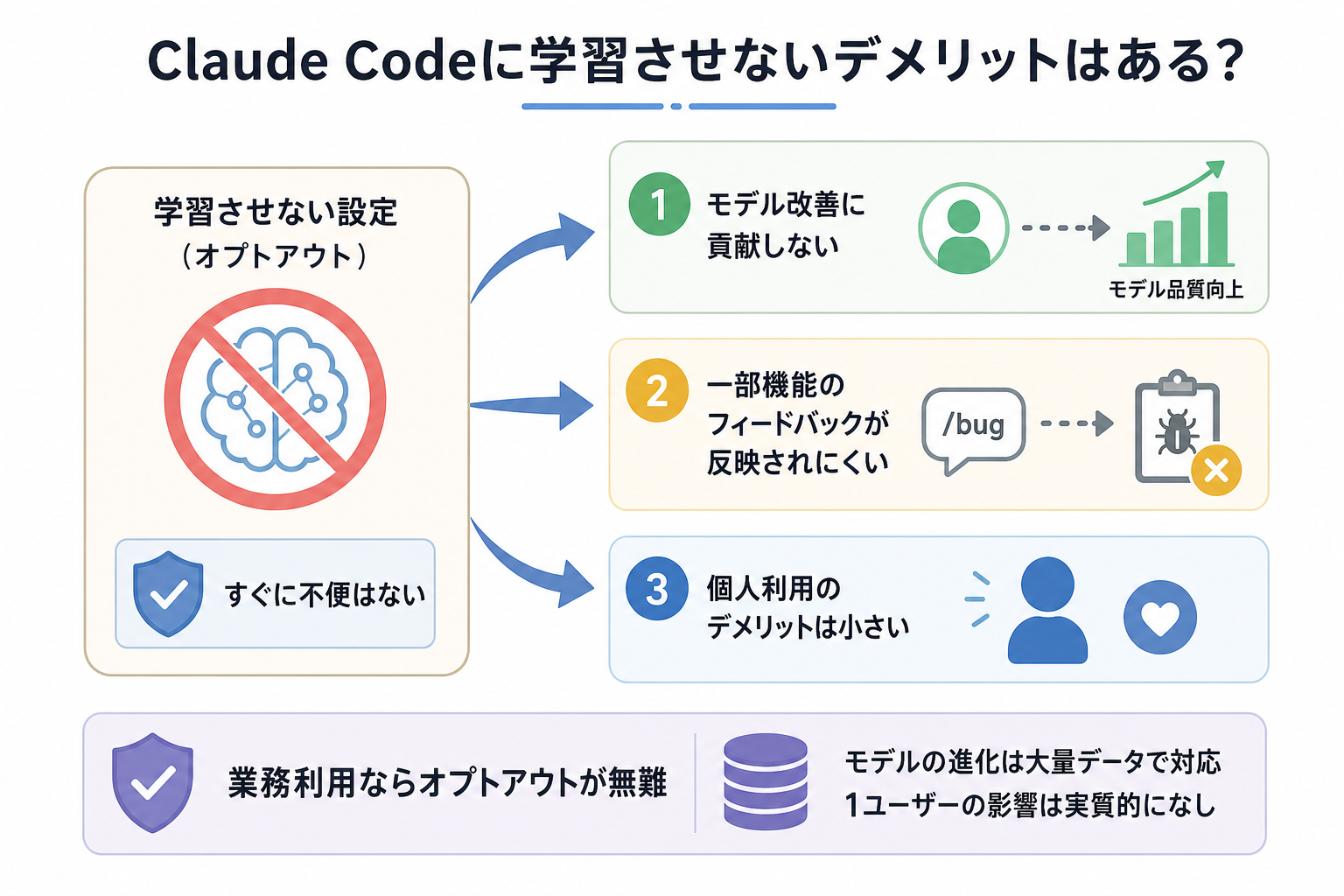
結論として、学習させない設定(オプトアウト設定)によって日常的な使い勝手が悪くなることは、ほとんどありません。
ただし、事前に理解しておきたい点は2つあります。
1つ目は、モデル改善へのフィードバックに参加しなくなることです。
Anthropicはユーザーから許可を得たデータを活用してモデル品質を改善しています。そのため、オプトアウトすると自分の利用データは改善用データとして使われなくなります。とはいえ、これはあくまでAnthropic側の学習データ量に関する話であり、ユーザー自身の利用体験が悪化するわけではありません。
2つ目は、一部の機能でフィードバック機能との関係です。
たとえば不具合報告に利用される「/bug」コマンドでは、問題解析のために追加情報が送信される場合があります。オプトアウト設定時は、こうしたデータ利用の範囲にも注意が必要です。
ただし、通常利用においてオプトアウトのデメリットを感じる場面はほぼありません。
とくに業務利用では、利便性よりも情報管理の安全性が優先されるケースが多いため、基本的にはオプトアウト設定を有効にしておくのが無難です。
Claude Codeに学習させるかを判断するポイント
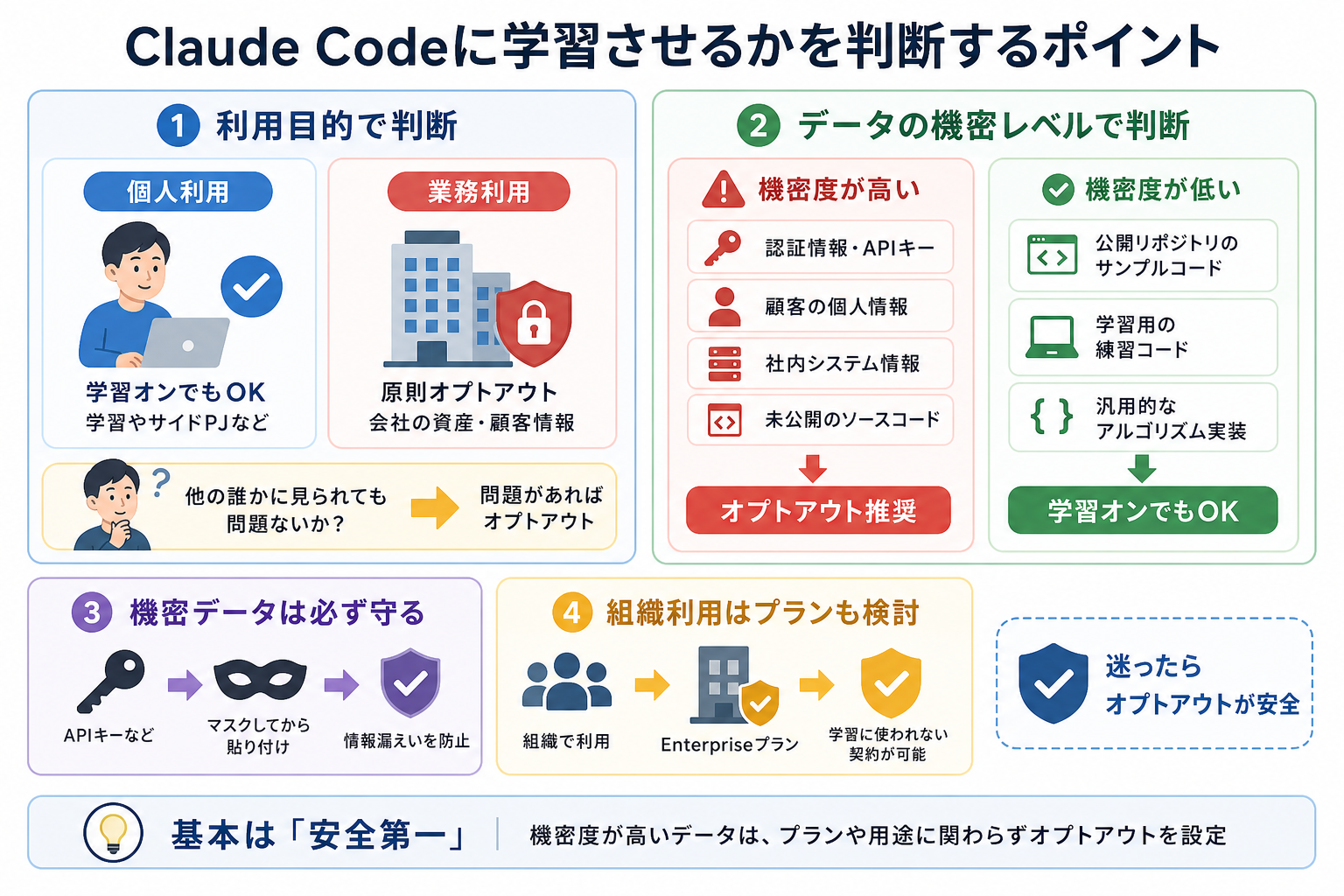
Claude Codeに学習させるかどうかは「どのような用途で使うか」と「どんなデータを入力するか」で判断するのが基本です。ここからは下記の軸別に、判断のポイントを解説します。
個人・業務利用かで基準を分ける
まず重要なのは、Claude Codeを個人用途で使っているのか、業務用途で使っているのかです。
個人利用の場合は、学習設定をオンのまま使っていても大きな問題にならないケースが多いでしょう。たとえば、次のような用途です。
- プログラミング学習
- 個人開発
- 公開予定のサンプルコード作成
- 技術検証用の簡単なコード生成
こうした内容は、仮に学習対象になったとしても実害が発生しにくいためです。
一方、業務利用の場合は基本的にオプトアウトを推奨します。
業務コードには、顧客情報・社内ロジック・認証情報・未公開機能など、企業資産に関わる内容が含まれる可能性があります。そのため、「念のため学習対象外にしておく」という考え方が一般的です。
判断に迷う場合は、「このコードや会話内容を第三者に見られても問題ないか」を基準にすると分かりやすいでしょう。
少しでも不安がある場合は、オプトアウト設定を有効にしておくのがおすすめです。Claude Codeの使い方を詳しく知りたい人は、次の記事を参考にしてください。

扱うデータの機密レベルで分ける
次に確認したいのが、Claude Codeに入力するデータの機密レベルです。とくに、以下のような情報を扱う場合は、オプトアウト設定を推奨します。
- APIキー
- アクセストークン
- 秘密鍵
- 顧客情報を含むコード
- 社内システム構成情報
- 未公開プロダクトのソースコード
- 独自アルゴリズムや業務ロジック
これらは、万が一でも外部へ漏えいした場合の影響が大きいため、慎重に扱う必要があります。
機密度が高いデータを扱うなら、プランや用途にかかわらずオプトアウトを設定しておくのが安全です。とくに開発現場では、「機密情報は入力前にマスクする」をルール化しておきましょう。
なお、EnterpriseプランではデータがAnthropicのモデル学習に使われない契約を結べます。組織全体でClaude Codeを使う場合はEnterpriseプランへの移行も検討してください。
Claude Codeの学習使用によくある疑問
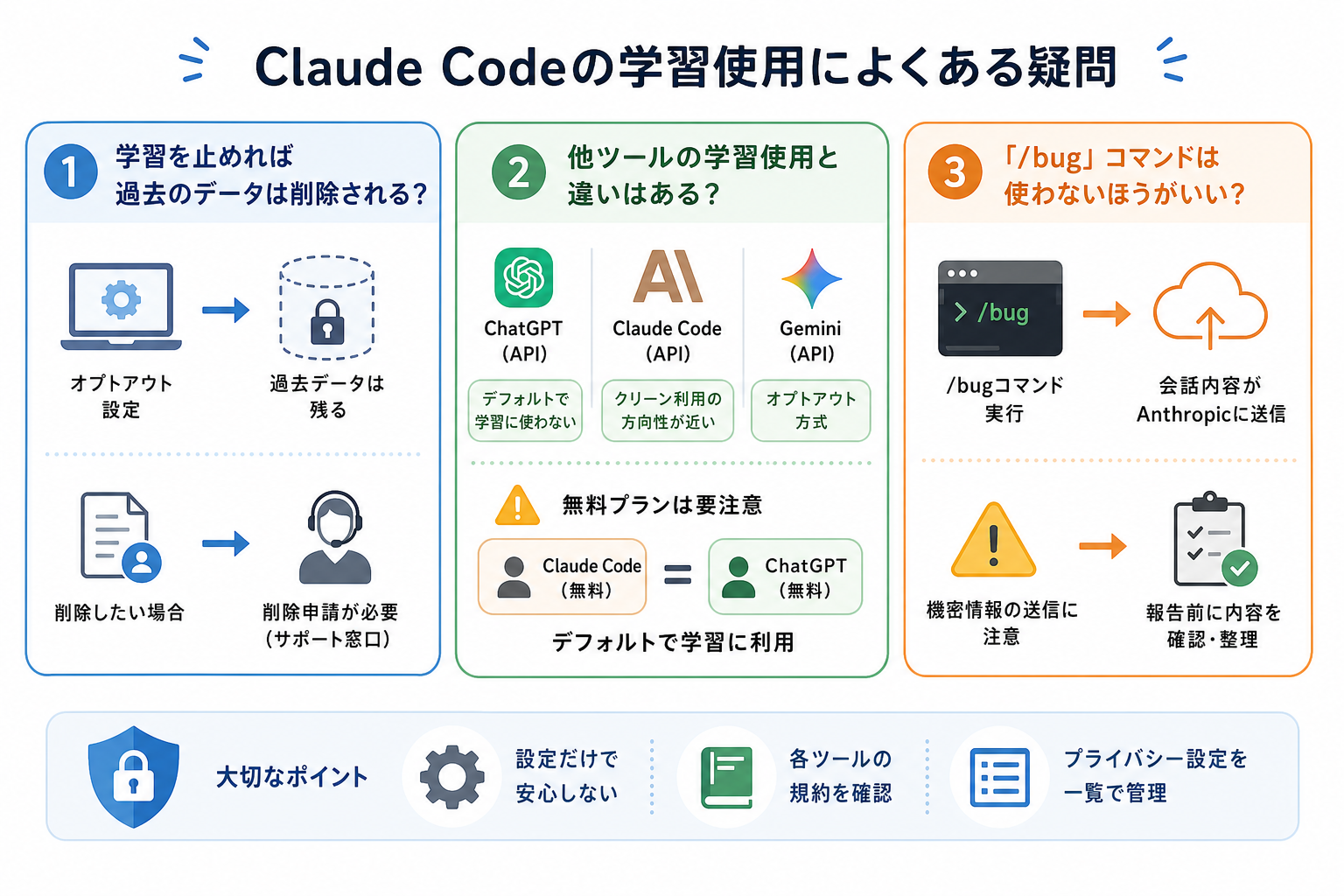
ここからは、Claude Codeの学習利用についてよくある疑問を解説します。
学習を止めれば過去のデータは削除される?
オプトアウト設定を有効にしても、設定以前にやり取りした過去のデータが自動的に削除されるわけではありません。
Anthropicの公式プライバシーポリシーによると、オプトアウトは「今後のデータをモデル改善に利用しない」ための設定として扱われています。そのため、設定変更前に送信したデータについては、さかのぼって削除される保証はありません。
過去データの削除を求める場合は、早めにデータ削除申請を検討しましょう。申請の窓口はAnthropicの公式サポートページから確認できます。
とくに業務利用では「あとでオプトアウトすれば大丈夫」と考えず、利用開始前に設定を済ませておくことが重要です。
他ツールの学習使用と違いはある?
ChatGPTやGeminiなど他の生成AIサービスでも「入力データを学習に使うかどうか」は重要なテーマになっています。
Claude Codeの特徴は、API利用時のデータがデフォルトで学習対象外になっている点です。この点は、OpenAIやGoogleのAPIポリシーとも近い考え方です。
一方でClaude Code(Claude.ai)のPro・Maxプランでは、会話データがモデル改善に利用される設定が有効になっています。これはChatGPT無料版などと同様の考え方です。
つまり、「APIは基本的に学習対象外」「無料Web版は学習対象になる場合がある」という構造は、多くの生成AIサービスで共通しています。ただし、細かな規約やデータ保持期間はサービスごとに異なります。
複数のAIツールを業務利用する場合は「どのツールがデフォルトで学習オンなのか」を一覧で管理しておくと安全です。
「/bug」コマンドは使わないほうがいい?
Claude Codeの「/bug」コマンドは、不具合やエラーをAnthropicに報告するための機能です。
このコマンドを実行すると、問題調査のために会話内容や実行情報が送信される場合があります。そのため、業務コードや機密情報を扱っている最中は注意が必要です。
たとえば、デバッグ中のコードに以下のような情報が含まれているケースがあります。
- APIキー
- 顧客情報
- 社内URL
- データベース接続情報
- 未公開機能のコード
こうした状態で「/bug」コマンドを実行してしまうと、機密情報が含まれた会話が送信されるリスクがあります。そのため、バグ報告時は次の点を確認しましょう。
- 送信前に会話内容を見直す
- 機密情報をマスクする
- 業務利用では利用ルールを決める
- 必要に応じて別経路で報告する
重要なのは「/bugを絶対に使わない」ことではなく、送信内容を確認する習慣を持つことです。普段からAPIキーや機密情報をそのまま貼り付けない運用を徹底しておけば、誤送信リスクも自然と下がります。
まとめ
この記事では、Claude Codeに学習させない設定方法や、オプトアウトを判断するポイントを解説しました。
Claude.aiのProやMaxなどの個人向けプランはデフォルトで会話データがモデル改善に利用される設定になっています。一方、Pro・Team・EnterpriseやAPI・CLI利用では、学習対象外となるケースが多く、利用形式によって扱いが異なります。
とくに業務利用や機密情報を扱う場合は、オプトアウト設定を有効化しておくのがおすすめです。個人利用でも、「第三者に見られると困る情報を入力する可能性があるか」を基準に判断するとよいでしょう。
まずは Claude公式サイト の設定画面を開き、自分のプライバシー設定がどうなっているか確認するところから始めてみてください。


