
Claude Codeのコンテキストとは?確認/管理方法から節約術まで全解説

Claude Codeのコンテキストって何のこと?
コンテキストが足りなくなったらどうすればいいの?
Claude Codeを使いはじめ便利だと感じている反面、動作が重くなったり、エラーが出たりして困っている人も多いですよね。
どうすればいいのかわからず、思うようにClaude Codeを動かせていない人もいるはず。
実のところ、Claude Codeにおける動作の不具合やエラーは、コンテキストの消費が原因である可能性があります。コンテキストを正しく管理すれば、長時間の開発作業も快適に進められます。
そこでこの記事では仕組みも交え、Claude Codeにおけるコンテキストの特徴を解説します。コンテキストの消費を減らすコツも紹介するので、ぜひ参考にしてください。
Claude Codeの特徴をおさらいしておきたい人は、次の記事を参考にしてください。

- コンテキストウィンドウはプランとモデルで上限が異なる
- `/compact`コマンドで会話を圧縮しコンテキストを節約できる
- CLAUDE.mdに文脈を記録すれば新セッションでも作業を引き継げる
『ClaudeCodeに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- ClaudeCodeに作業や仕事を任せる方法
- ClaudeCodeを使いこなすたった1つのコツ
- 業務効率化や収入獲得に活かすClaudeCodeの実演
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。この時間が、あなたを変える大きなきっかけになりますよ。
Claude Codeのコンテキストとは

Claude Codeにおけるコンテキストとは、AIが「現在の会話や作業状況をどこまで把握しているか」を示す情報の範囲です。
コンテキストはAIの「作業記憶」そのものであり、会話履歴や読み込んだファイルの内容、実行したコマンドの結果などをすべて含みます。
ここからは、コンテキストに関する次の3点を解説します。
コンテキストウィンドウの仕組み
コンテキストウィンドウとは、AIが一度に参照できる情報の「枠」のことです。
枠の中に入っている情報だけを、AIは認識して応答します。
人間に例えると、机の上に広げられた書類の量に相当します。机の広さ(=ウィンドウサイズ)を超えると、古い書類を端に追いやらなければ新しい作業ができません。
Claude Codeでは、以下のすべてが枠の中に積み重なっています。
- ユーザーの発言
- AIの返答
- 読み込んだファイル内容
- ツール実行結果
枠が埋まると、古い情報が参照できなくなったり、新たな指示を受け付けなくなったりします。
作業をスムーズに進めるには、コンテキストウィンドウの整理が欠かせません。
コンテキストサイズの目安と上限
Claude Codeが使用するモデルのコンテキストウィンドウは、モデルとプランによって異なります。
標準的なプランでは20万トークンですが、Pro・Max・Team・EnterpriseプランではOpus 4.8、Opus 4.7、Opus 4.6で最大100万トークンが利用可能です。
Sonnet 4.6も有料プランのClaude Codeで100万トークンに対応していますが、利用にはusageクレジットの有効化が必要です(usage-based Enterpriseプランを除く)。
トークンとは、テキストを処理する際の単位です。日本語では1文字がおおよそ1〜2トークンに相当します。20万トークンを文字数に換算すると、日本語でおよそ10万〜20万文字分です。
一見すると膨大な量に見えますが、実際の開発作業では思いのほか早く消費されます。具体的な消費量の目安は次のとおりです。
- ソースコード1,000行:約5,000〜8,000トークン
- 通常の会話1往復:約200〜500トークン
- 大きめのファイル(設定ファイルなど):約1,000〜3,000トークン
複数ファイルを読み込みながら長い会話を続けると、数十回のやりとりでウィンドウが埋まることもあります。
残量が少なくなったときの挙動
コンテキストの残量が少なくなると、通常とは異なる挙動を起こす可能性があります。コンテキストが約95%に達したあたりで、Claude Codeは自動的にコンテキストの圧縮(auto-compaction)を実行します。
それ以前の段階でも、次のような現象が起こります。
- 「コンテキストが不足しています」という警告メッセージが表示される
- 以前の会話内容を「忘れた」ように、同じ質問を繰り返してしまう
- コードの前半部分を参照できず、整合性のない回答が返ってくる
- 新たなタスクの受け付けを拒否される
とくに危険なのは、コードの前後の整合性が崩れるケースです。前半で定義した変数名や関数名を参照できない状態になると、正常に動かないコードが生成されます。
コンテキストが消費される主な原因
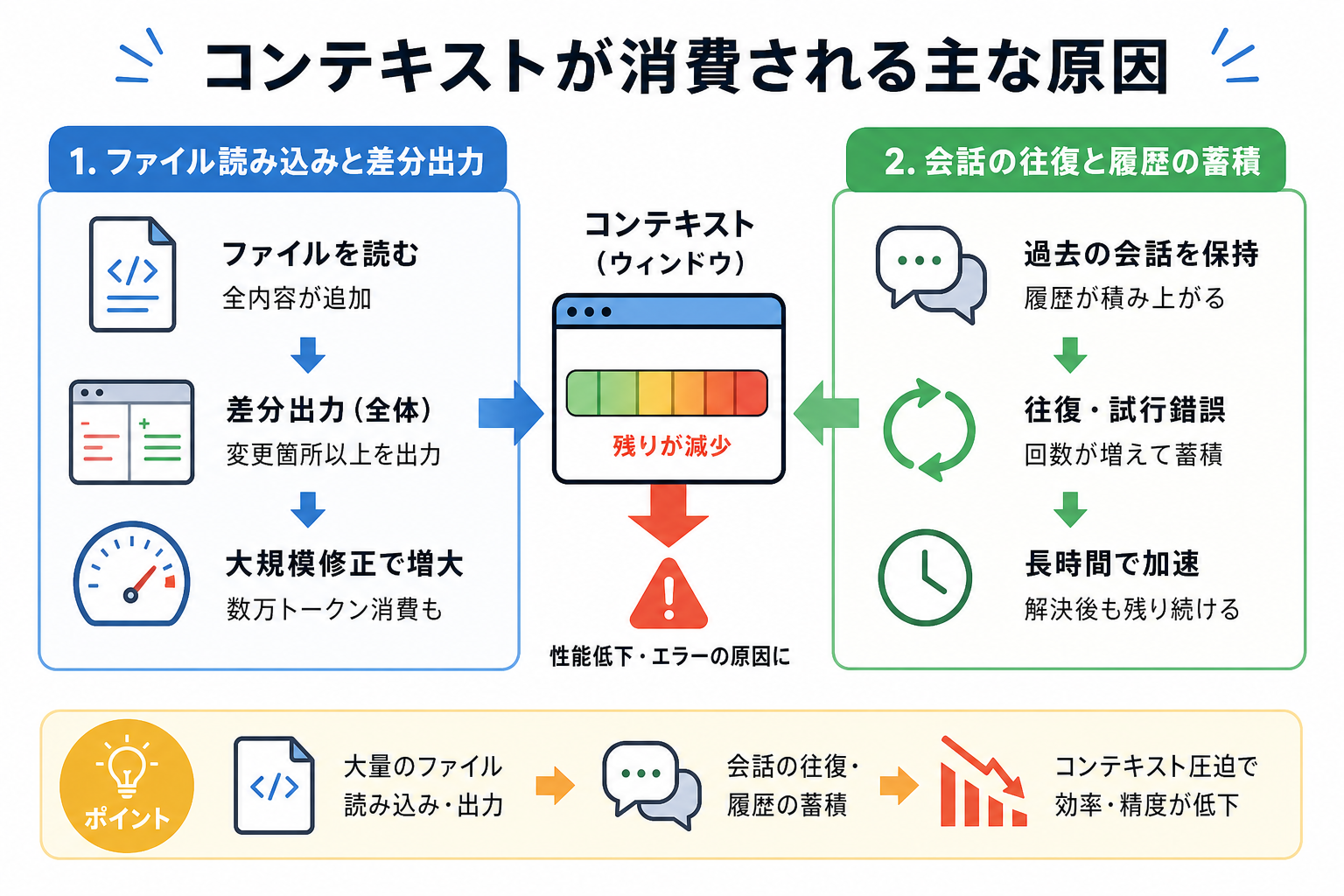
Claude Codeでコンテキストを大量に消費する主な原因は、ファイルの読み込みと会話の蓄積の2つに集約されます。ここからは下記の原因別に、ファイル読み込みと会話蓄積がコンテキストに与える影響を解説します。
ファイル読み込みと差分出力の影響
Claude Codeがファイルを読み込む際、ファイルの全内容がコンテキストウィンドウに追加されます。たとえば、500行のPythonファイルを読み込むと、それだけで数千トークンが一気に消費されます。
さらに問題になるのが「差分出力」です。Claudeがコードを修正する際、変更箇所だけでなくファイル全体を出力するケースがあります。1,000行のファイルに10行の変更を加えただけでも、1,000行分のトークンが消費されます。
コードのリファクタリングや大規模な修正作業では、差分出力が繰り返し発生することも多いです。1回の作業で数万トークンを消費することも珍しくなく、コンテキストを消費する原因になりえます。
会話の往復と履歴の蓄積
Claude Codeでの会話や作業履歴が増えることで、コンテキストを消費するケースがあります。
Claude Codeは、過去のやりとりすべてをコンテキストとして保持します。会話が長くなるほど、蓄積される履歴も増え続ける仕組みです。
よくある失敗パターンとして、次のようなケースが挙げられます。
- エラーを何度もやりとりしながらデバッグを続ける
- 仕様変更を何度も繰り返し、修正の指示が積み重なる
- 同じファイルを何度も「確認して」と依頼する
- 試行錯誤しながら方針をコロコロ変える
たとえば、バグの原因特定に20往復の会話を費やした場合、全履歴がコンテキストに残ります。問題が解決した後も、会話は削除されずにウィンドウを占有し続けます。ひとつのセッションで長時間作業するほど、消費速度が加速する構造のため、作業が複雑になることで履歴が増えてコンテキストを消費する可能性があるのです。
Claude Code・コンテキストの確認方法
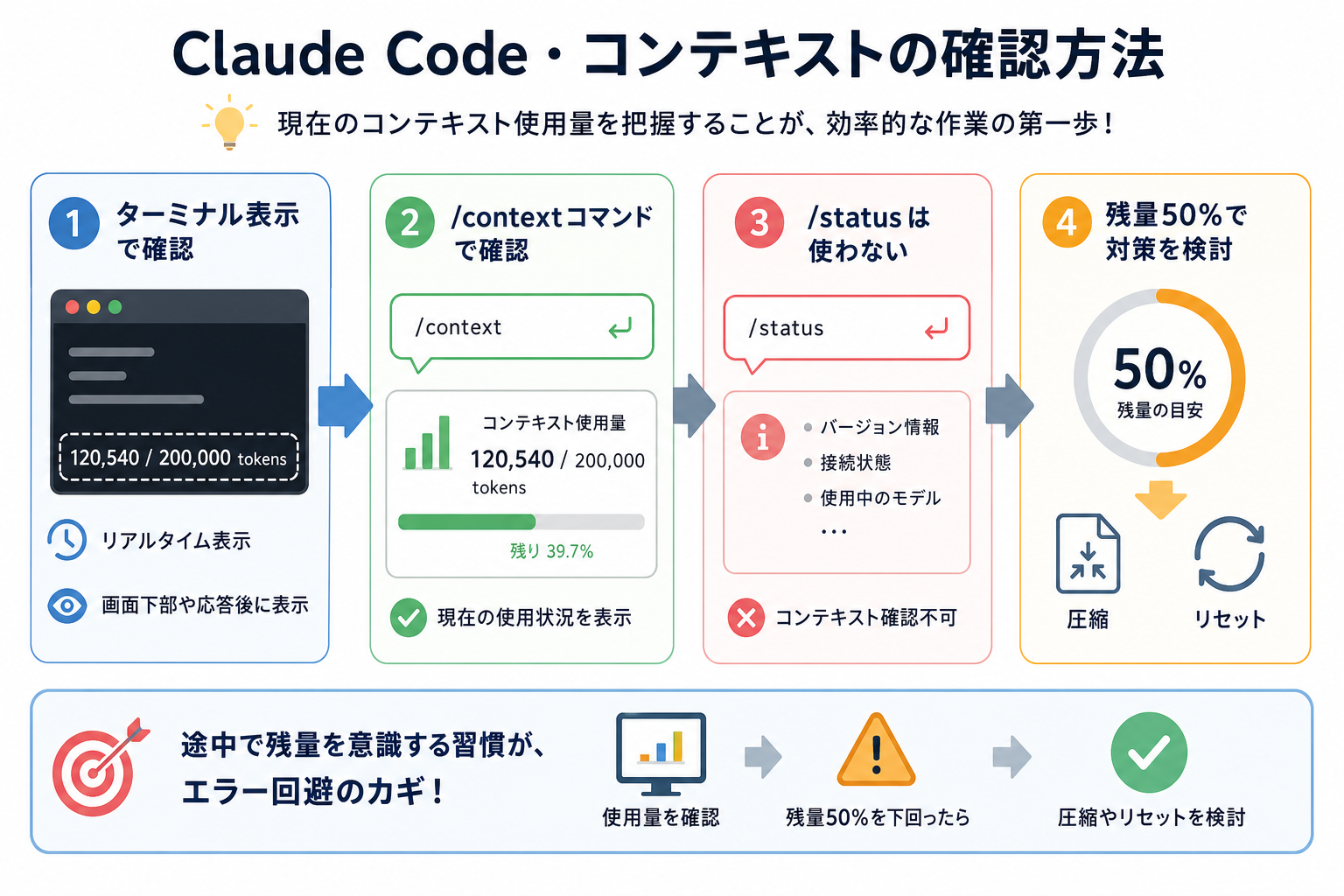
現在のコンテキスト使用量を把握することは、効率的な作業の第一歩です。Claude Codeでは、コンテキストの使用状況をターミナル上で確認できます。
確認する主な方法は、次の2つです。
1.ターミナルの表示で確認する
Claude Codeのセッション中、ターミナルには現在のトークン使用量がリアルタイムで表示されます。
画面下部や応答後に「tokens used」や「context」といった表記で、使用済みトークン数と上限が確認可能。具体的な表示形式はバージョンによって異なりますが、「XX,XXX / 200,000 tokens」のような形式で表示されます。
2.’/context‘コマンドで確認する
Claude Codeのチャット欄に `/context` と入力することで、現在のコンテキスト使用量を確認できます。なお、`/status` はバージョン情報や接続状態・使用中のモデルなどのセッション情報を表示するコマンドであり、コンテキスト使用量の確認には使いません。
作業の途中でコンテキスト残量を意識する習慣をつけると、突然のエラーを防ぎやすいです。残量が50%を下回ったタイミングで、次の節で紹介する圧縮やリセットを検討するのがおすすめです。
Claude Codeのコマンドについて詳しく知りたい人は、次の記事を参考にしてください。

コンテキストが足りなくなったときの対処法
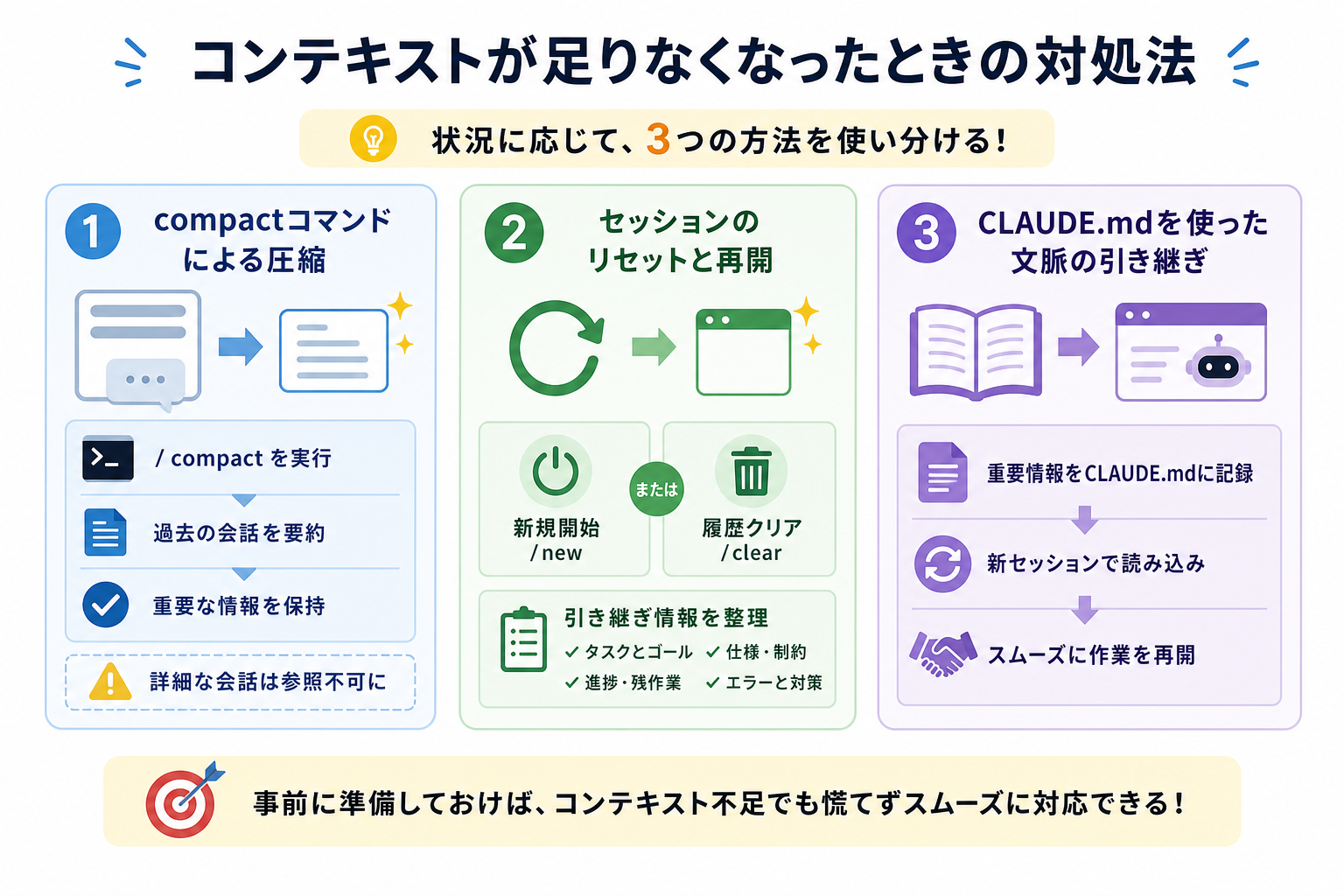
コンテキストが不足したときに慌てないよう、対処法を事前に知っておくことが重要です。
コンテキスト不足の主な対処法は3つあり、状況に応じて対策を変える必要があります。
ここからはコンテキストが足りなくなったときの対処法を、3つにまとめて解説します。
compactコマンドによる圧縮
compactコマンドを実行することで、コンテキストを圧縮できます。
`/compact`コマンドは、コンテキストを圧縮してウィンドウの空きを作るコマンドです。実行すると、過去の会話を要約した形でコンテキストを縮小します。
使い方は非常に簡単で、チャット欄に次のように入力するだけです。
```
/compact
```オプションとして、圧縮時に残したい情報を指定することもできます。
```
/compact 現在のバグ修正タスクに関する情報を優先して残してください
```圧縮を実行すると、Claude Codeは会話履歴を自動的に要約します。詳細なやりとりは削除されますが、作業の核心部分(現在取り組んでいるタスクの概要・直近の変更内容など)は保持されるので安心です。
注意点として、圧縮後は細かい過去の指示を参照できなくなります。圧縮前に重要な決定事項や制約条件をメモしておくか、後述のCLAUDE.mdに記録しましょう。
セッションのリセットと再開
コンテキストが完全に埋まった場合や、作業の方向性が大きく変わった場合は、セッションをリセットして新たに始め直すのが効果的です。
リセットには、2つの方法があります。
- 新規セッションの開始
- 履歴のクリア
Claude Codeを再起動するか、`/new`コマンドを実行することで新しいセッションを開始できます。`/clear`コマンドで現在のセッション履歴を削除すれば、セッションがリセット可能です。
リセットの最大のメリットは、コンテキストを100%の状態に戻せることです。ただし、それまでの会話内容はすべて失われるため、作業の引き継ぎが必要になります。
引き継ぎを効率よく行うには、次の情報を整理してから新セッションを開始してください。
- 現在のタスクの目的と達成したいゴール
- 完了済みの作業と残っている作業の一覧
- 決定済みの仕様や制約条件
- 直前のエラー内容と試した解決策
必要な履歴をテキストファイルや後述のCLAUDE.mdにまとめておくと、新セッションでスムーズに作業を再開できます。
CLAUDE.mdを使った文脈の引き継ぎ
CLAUDE.mdを利用すれば、作業の文脈を新しいセッションに引き継げます。
CLAUDE.mdは、Claude Codeがプロジェクトを開始する際に自動的に読み込む設定ファイルです。このファイルに作業の文脈を記録しておけば、新しいセッションを開始してもClaude Codeが状況を把握した状態で作業を再開できます。
CLAUDE.mdは、プロジェクトのルートディレクトリに配置します。ファイルの作成は次のコマンドで行えます。
```
/init
```このコマンドを実行すると、Claude Codeが現在のプロジェクト構造を解析してCLAUDE.mdの雛形を自動生成します。
CLAUDE.mdに記載しておくべき内容の例は、次のとおりです。
“`markdown
# プロジェクト概要
ECサイトのバックエンドAPI開発。FastAPI + PostgreSQLを使用。
# 現在のタスク
ユーザー認証機能の実装(JWTトークン方式)
# 完了済みの作業
データベース設計
商品一覧APIの実装
# 技術的な決定事項
Pythonバージョン:3.11
認証ライブラリ:python-jose
テストフレームワーク:pytest
# 注意事項
本番環境のDBには直接アクセスしない
コミット前に必ずテストを実行する
“`
CLAUDE.mdはセッションをまたいで読み込まれるため、コンテキストをリセットするたびに一から説明し直す手間がなくなります。長期間にわたるプロジェクト開発では、CLAUDE.mdの活用が作業効率を大きく左右します。
Claude Code・コンテキストの節約術
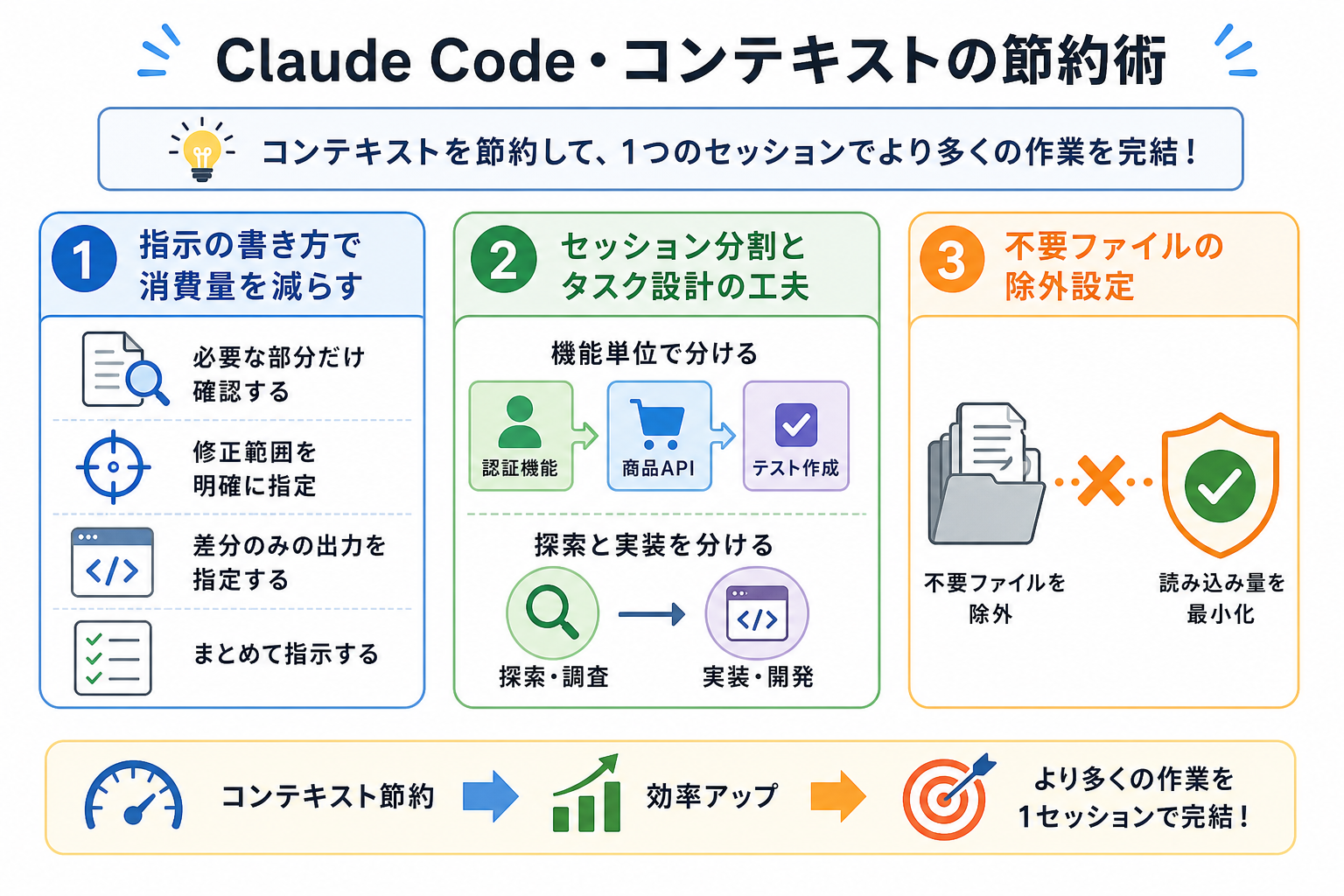
コンテキストは「指示の書き方」「セッション設計」「ファイル管理」を工夫することで節約できます。
ここからはコンテキストの節約術を、3つにまとめて解説します。
指示の書き方で消費量を減らすコツ
指示の書き方ひとつで、コンテキストの消費量は大きく変わります。要点を絞った簡潔な指示は、冗長な指示と比べてトークン消費量を30〜50%削減できます。
消費を減らすための具体的なコツは、次のとおりです。
1.ファイル全体の読み込みを避ける
ファイル全体の読み込みを避けることで、コンテキストの消費を減らせます。
たとえば「このファイルを確認して」というあいまいな指示は、ファイル全体をコンテキストに読み込みます。代わりに「`auth.py`の`login`関数だけを確認して」のように、対象を絞ることでトークン消費を削減可能です。
2.修正範囲を明確に指定する
修正範囲を明確に指定することで、コンテキストの消費を減らせます。
「バグを直して」という曖昧な指示より、「`user.py`の42行目のNullエラーを修正して。変更は最小限にすること」のように、変更範囲を具体的に指示するほうが効果的です。
範囲が明確だと、Claudeがファイル全体を出力する可能性が下がります。不要な修正を減らすことにもつながるため、できるだけ修正範囲は明確かつ狭く指定しましょう。
3.差分のみの出力を指定する
修正した場所のみを指定して出力することで、コンテキストの消費を抑えられます。
コード修正を依頼する際、「変更した箇所のみを出力してください。ファイル全体を出力しないでください」と明示することで、不要なトークン消費を防げます。
4.まとめて指示する
修正依頼をまとめて指示することで、コンテキストの消費量を抑えられます。
複数の小さな修正を1つずつ依頼すると、その都度コンテキストが消費されます。「次の3点を一度に修正してください」のようにまとめて依頼することで往復回数が減り、消費量を削減可能です。
ただし、一度に多くの修正を指示した場合、作業が複雑になって処理精度が落ちることも。修正が複雑になると、コード内容がわかりにくくなる可能性もあります。
一定程度まとめて指示を出しつつも、コードの読みやすさや処理の負荷も考慮してください。Claude Codeで使えるプロンプトを詳しく知りたい人は、次の記事を参考にしてください。

セッション分割とタスク設計の工夫
作業をタスク単位で分割し、セッションを戦略的に使い分けることでコンテキストを節約できます。
1つのセッションで何でもこなそうとすると、コンテキストが急速に埋まります。複数にセッションをわけることで、構造をシンプルにしてコンテキストの消費を削減可能です。
効果的なセッション分割の考え方は、次のとおりです。
1.機能単位でセッションを分ける
機能単位でセッションを分けることで、コンテキスト数を抑えつつコードのメンテナンス性も高められます。
「認証機能の実装」「商品一覧APIの実装」「テストの作成」のように、機能単位でセッションを分けます。1つのセッションで1つの機能を完成させるイメージで進めると、コンテキストが無駄に消費されません。
また、機能別でコードを管理することで、メンテナンス性を高めることも可能です。バグなどのトラブルが起きたときも原因を特定しやすく修正もスムーズに行えます。
コンテキストの消費を減らしつつ、メンテナンス性も向上させるために機能単位でセッションを分けるのが効果的です。
2.探索と実装のセッションを分ける
開発の設計と実装のセッションを分けることで、コンテキスト数を削減できます。
「どう実装するか検討する探索セッション」と「実際にコードを書く実装セッション」を分けると、探索段階の試行錯誤がコンテキストに残らないため、実装セッションをクリーンな状態で始められます。
3.デバッグは独立したセッションで行う
デバッグを独立したセッションを実施することで、コンテキスト数を削減できます。
バグ修正は往復が多く、コンテキストを大量消費します。通常の開発セッションとは別に、デバッグ専用のセッションを設けることで、メインの開発作業へのコンテキスト汚染を防げます。
不要ファイルの除外設定
不要ファイルの設定を行うことで、必要最小限のファイルだけ読み込み、コンテキスト数を削減できます。
Claude Codeがプロジェクト内のファイルを自動探索する際、不要なファイルまで読み込んでしまうとコンテキストが無駄に消費されます。
`.claudeignore`ファイルを設定することで、参照対象から除外するファイルを指定可能です。`.claudeignore`ファイルは、プロジェクトのルートディレクトリに作成します。記述方法は`.gitignore`と同じ形式です。
除外すべき代表的なファイルの例は、次のとおりです。
```
# 依存パッケージ
node_modules/
venv/
__pycache__/
# ビルド成果物
dist/
build/
*.pyc
# ログファイル
*.log
logs/
# テストカバレッジ
coverage/
.coverage
# 環境設定ファイル(セキュリティ上も重要)
.env
.env.local
# 大きなデータファイル
*.csv
data/
````node_modules`や`venv`のような依存パッケージのディレクトリは、数万〜数十万行のコードを含みます。除外設定をしないと、Claudeがこれらを参照するたびにコンテキストが大量消費されます。
`.env`ファイルのような機密情報を含むファイルを除外することは、セキュリティの観点からも重要です。除外設定はプロジェクト開始時に行うと、後から慌てずに済みます。
CLAUDE.mdに「このプロジェクトで参照が必要なファイルはsrc/ディレクトリ内のみです」のように参照範囲を明示しておくと、Claudeが不必要なファイルを読み込む頻度を下げられるのでおすすめです。
まとめ
今回は、Claude Codeのコンテキストについて解説しました。
コンテキストはファイルの読み込みや会話の蓄積、デバッグなどの作業で消費されます。意識しないとコンテキストは消費されやすいため、本記事を参考に消費量を意識しつつ活用してください。


