
Claude Codeでデータ分析を効率化・自動化する方法【活用術も紹介】

Claude Codeってデータ分析にも使えるの?
どうすれば分析作業を自動化できるのかな…
Claude Codeでデータ分析が効率化・自動化できないか、気になっている人も多いですよね。
分析できる量や効率化できる範囲などを、把握してから使い始めたい人もいるはず。
そこでこの記事では、Claude Codeでデータ分析を効率化・自動化する方法を解説します。他ツールとの連携方法や分析手順も紹介するので、ぜひ参考にしてください。
Claude Codeの特徴をおさらいしておきたい人は、次の記事を参考にしてください。

- Claude Codeはデータ分析コード生成から実行まで1つの環境で完結できる
- CSV読み込み→分析実行まで4ステップで始められる
- 繰り返し分析はスクリプト化でほぼ自動化できる
『ClaudeCodeに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- ClaudeCodeに作業や仕事を任せる方法
- ClaudeCodeを使いこなすたった1つのコツ
- 業務効率化や収入獲得に活かすClaudeCodeの実演
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。この時間が、あなたを変える大きなきっかけになりますよ。
Claude Codeでデータ分析は効率・自動化できる
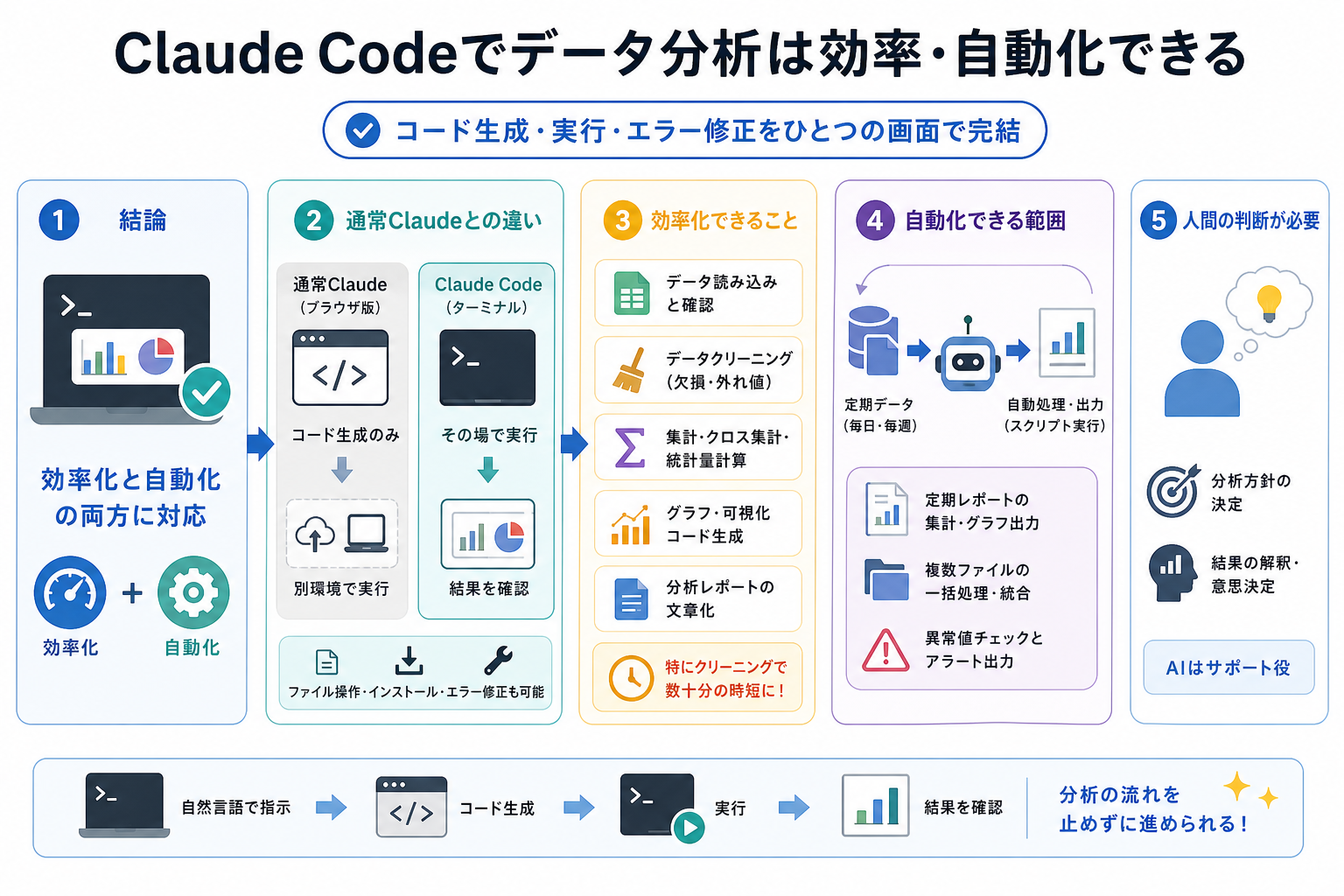
結論として、Claude Codeはデータ分析の効率化・自動化の両方に対応できます。
コード生成・実行・エラー修正を、ひとつの画面で完結できる点が最大の強みです。分析担当者がPythonの細かい文法を覚えなくても、自然言語で指示するだけで分析コードを書いてそのまま動かせます。
ここからは、Claude Codeでデータ分析する際、自動化できる範囲や効率化できることを解説します。
通常Claudeとの違い
通常のClaude(ブラウザ版)との最大の違いは、「コードをそのまま実行できるかどうか」です。
Claudeもブラウザ上の「分析ツール(Code Execution)」機能でコードを実行できますが、対応言語やファイル操作に制限があります。
Claude Codeはターミナル上で動くため、Pythonライブラリのインストールやファイルの読み書きなど、より自由度の高い分析環境として利用できます。
ファイルの読み書き・ライブラリのインストール・エラーの自動修正も可能なので、分析の一連の流れを途切れさせずに進められます。
Claudeの特徴を詳しく知りたい人は、次の記事を参考にしてください。

効率化できること
Claude Codeをデータ分析に使うと、次の作業を大幅に速くできます。
- CSVやExcelファイルの読み込みとデータ確認
- 欠損値処理・外れ値検出などのデータクリーニング
- 集計・クロス集計・グループ別の統計量計算
- グラフ・可視化コードの生成と出力
- 分析レポートの文章化
とくにデータクリーニングのコード生成は、手作業と比べて数十分の時間短縮になります。「この列の欠損値を平均値で埋めて」と一言指示するだけで、Pandasのコードが即座に生成・実行されます。
分析データをレポートにすることも可能なため、開発業務だけでなくマーケティングなどにも活かせるところが魅力です。
自動化できる範囲
Claude Codeで自動化できる範囲は、主に「繰り返し発生する定型分析」です。
毎日・毎週同じ形式のデータが届く業務では、分析スクリプトを一度作成すれば、次回からはスクリプトを実行するだけで作業が完了します。具体的には、次の処理が自動化の対象です。
- 定期レポート用の集計・グラフ出力
- 複数ファイルの一括処理と結果の統合
- データの異常値チェックとアラート出力
一方で、分析の方針決定や結果の解釈は人間の判断が必要です。「何を分析するか」の設計はClaude Codeに丸投げせず、自分で指示内容を考える必要があります。
Claude Codeでのデータ分析に必要なもの

Claude Codeでデータ分析を始めるには、次のものを用意します。
| 必要なもの | 詳細 |
|---|---|
| Anthropicアカウント | Claudeの公式サイトで無料作成できる |
| Claude Maxプラン(推奨) | 月額100ドル〜。後述の料金詳細を参照 |
| Node.js(v18以上) | Claude Codeのインストールに必要 |
| Python(3.8以上) | データ分析コードの実行環境 |
| 分析用ライブラリ | pandas、numpy、matplotlib などをpipでインストール |
| 分析対象のデータ | CSVやExcelなどのファイル形式で用意 |
Claude Codeの利用にはAnthropicのアカウントが必須です。料金はProプラン(月額20ドル)でも使えますが、データ分析のような長いやりとりが続く作業には、Maxプラン(月額100ドル)が向いています。
Proプランは使用量の上限に達するとセッションが止まるため、大規模なデータを扱う場合は処理の途中で止まる可能性も。Maxプランであれば上限が大幅に拡張されるため、長時間の分析作業をスムーズに続けられます。
Pythonは標準でインストールされていないOSもあるため、事前に`python –version`でバージョンを確認してください。
Claude Codeはデータ分析に活用すべき?
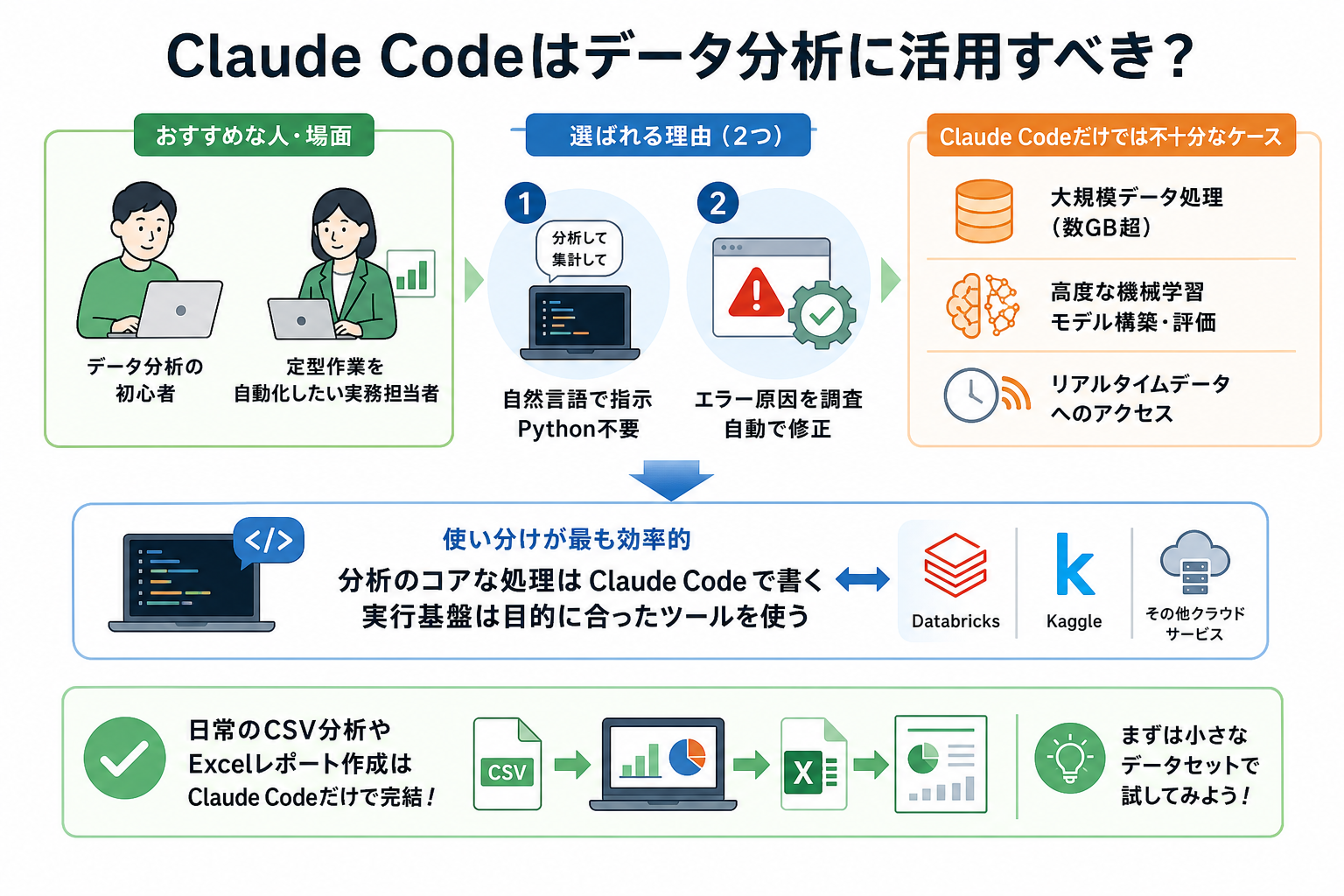
Claude Codeは、コードを書き慣れていないデータ分析初心者や、定型作業を自動化したい実務担当者は積極的に活用するのがおすすめです。
Claude Codeは日本語で指示できるため、Pythonの文法を覚えなくても分析を進められます。エラーが出たときは自動で原因を調べて修正してくれます。データ分析をスタートするまでのコード作成を任せられる分、他作業に専念できるところが魅力です。
一方で、次のようなケースではClaude Codeだけでは不十分なこともあります。
- 数GBを超える大規模データの処理(ローカル環境のメモリ制限が影響する)
- 高度な機械学習モデルの構築と評価(専用のML基盤が必要)
- リアルタイムデータへのアクセス(Claude Codeは内蔵のWebSearch・WebFetch機能で検索可能だが、専用のデータ分析基盤と比べるとリアルタイムデータの取得・処理には限界がある)
膨大なデータを分析したい場合や高度な分析作業を行う場合は、後述するDatabricksやKaggleとの組み合わせが有効です。つまり、「分析のコアな処理はClaude Codeで書き、実行基盤は目的に合ったツールを使う」という使い分けが最も効率的といえます。
日常的なCSV分析やExcelレポート作成であれば、Claude Codeだけで完結できます。まずは小さなデータセットで試してください。
Claude Codeでデータ分析を始める手順
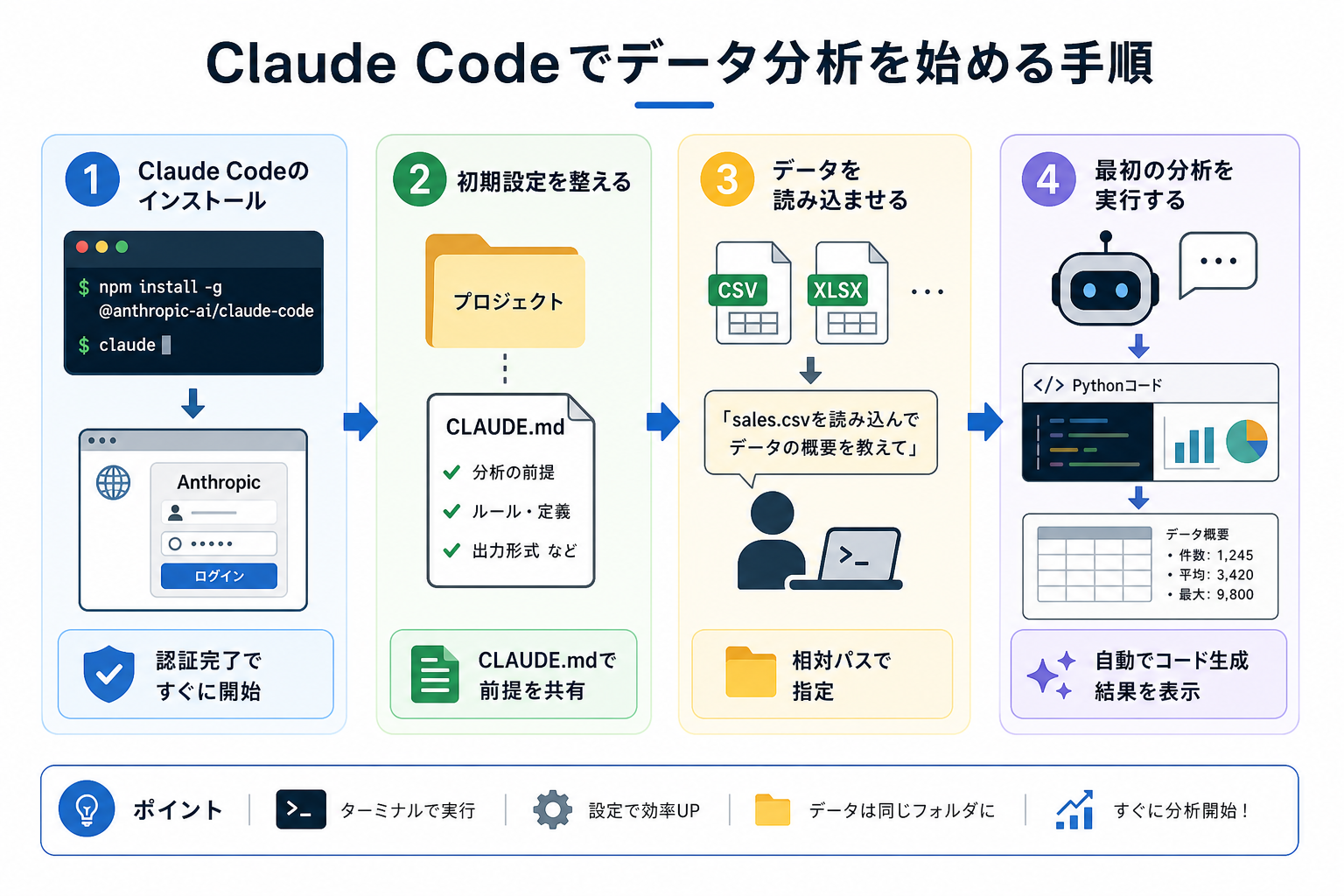
ここからはClaude Codeでデータ分析を始める手順を、4つにまとめて解説します。
1.Claude Codeのインストール
まずは、Claude Codeのインストールを実行してください。
Macはターミナル、WindowsはPowerShellを開き、次のコマンドを実行します。
```
npm install -g @anthropic-ai/claude-code
```インストール後、`claude`と入力してEnterを押すと初回認証画面が表示されます。
```
claude
```ブラウザが自動で開いてAnthropicのログイン画面に遷移するため、アカウントでログインして認証を完了してください。認証が完了するとターミナルにプロンプトが表示され、すぐに操作を開始できます。
Node.jsのバージョンが古い(v17以下)場合、インストールが失敗することがあります。`node -v`でバージョンを確認し、必要であればNode.jsの公式サイトから最新版をインストールしてください。
2.初期設定を整える
Claude Codeのインストールが完了したら、初期設定を行います。
Claude Codeで効率的にデータ分析を行うために、CLAUDE.mdを作成します。CLAUDE.mdはClaude Codeが起動時に読み込む設定ファイルで、作成することで分析の前提条件を毎回指示する手間がかかりません。
分析用プロジェクトのフォルダを作成し、CLAUDE.mdを置きます。
```
mkdir data-analysis-project
cd data-analysis-project
```フォルダ内にCLAUDE.mdを作成し、以下のような内容を記述します。
“`
# プロジェクト概要
このプロジェクトは売上データの分析を行います。
使用技術
Python 3.11
pandas, numpy, matplotlib, seaborn
コーディング規約
変数名は日本語コメントを必ず付ける
グラフは必ずタイトルと軸ラベルを入れる
分析結果は outputs/ フォルダに保存する
禁止事項
データの無断削除・上書きは行わない
元データファイルは変更しない
“`
CLAUDE.mdの内容は、プロジェクトの性質に合わせて書き換えてください。売上分析なら通貨の単位や期間の定義を、医療データなら個人情報の取り扱いルールを記載すると、毎回規定を説明する手間が省けます。
Claude Codeの始め方を詳しく知りたい人は、次の記事を参考にしてください。

3.データを読み込ませる
事前設定が完了したら、分析に必要なデータを読み込ませます。
分析対象のCSVやExcelファイルをプロジェクトフォルダに配置。その後、Claude Codeのターミナルから、次のように指示します。
```
claude
```Claude Codeが起動したら、日本語でそのまま指示できます。
“`
sales_data.csv を読み込んで、データの基本情報(行数、列数、各列のデータ型、欠損値の数)を確認してください。
“`
Claude Code が自動でPythonコードを生成し、その場で実行します。出力結果の例は次のとおりです。
“`
行数: 12,450行
列数: 8列
欠損値: 売上金額列に32件
データ型: 日付(object), 商品名(object), 売上金額(float64) …
“`
ファイルパスは、Claude Codeを起動したフォルダからの相対パスで指定すると認識しやすいです。ファイルが別のフォルダにある場合は、先にプロジェクトフォルダへコピーしておくと指示がシンプルになります。
CSVの文字コードがShift-JISの場合、読み込みエラーが発生することも。「読み込みエラーが出ました」と伝えるだけで、Claude Codeが文字コードを自動判定して修正コードを生成します。
4.最初の分析を実行する
データの基本確認ができたら、分析を始めます。
指示は日本語でOKです。以下は実際に使える指示の例です。
“`
月別の売上合計を計算して、折れ線グラフで可視化してください。
グラフはoutputs/monthly_sales.pngとして保存してください。
“`
Claude Codeは指示に対して、次の処理を自動で行います。
- 日付列をdatetime型に変換するコードを生成
- 月別集計のコードを生成
- matplotlibで折れ線グラフを作成するコードを生成
- コードを実行してPNGファイルを出力
- グラフの概要をテキストで説明
コードの内容を理解しなくても分析を進められますが、生成されたコードに目を通す習慣をつけると、分析の精度確認やトラブル対応に役立ちます。
データ分析を効率化・自動化するコツ
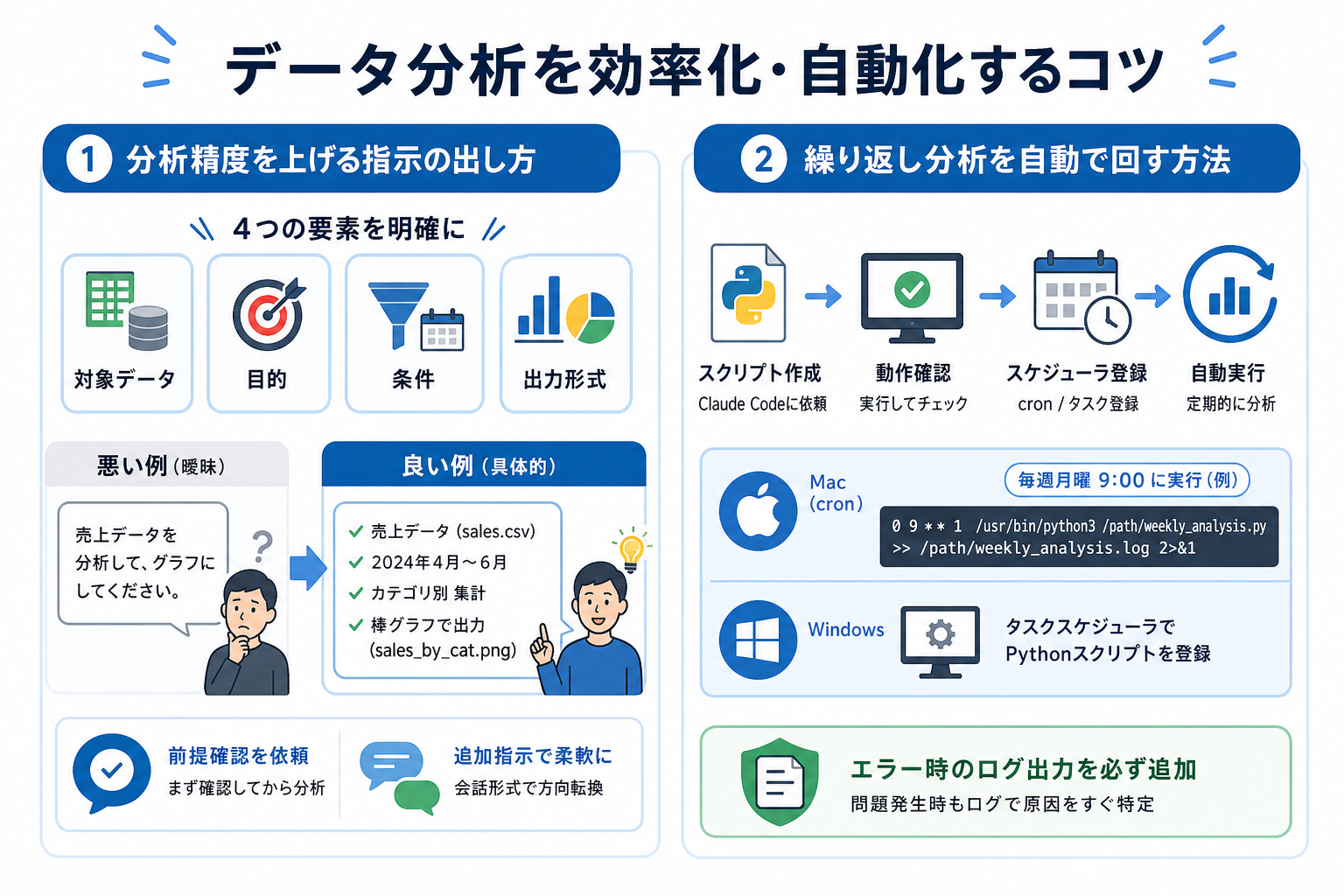
ここからはClaude Codeによるデータ分析をさらに効率化するコツを、2つにまとめて解説します。
分析精度を上げる指示の出し方
Claude Codeへの指示は、曖昧にするほど出力の精度が下がります。指示の質を上げるには、「5W1H」を意識することが大切です。
分析精度を上げるためには、次の4つの要素を含めましょう。
- 対象データ:どのファイルのどの列か
- 目的:何を明らかにしたいのか
- 条件:期間・カテゴリ・閾値などの絞り込み条件
- 出力形式:グラフの種類・ファイル名・表形式など
悪い例と良い例を比較すると、違いがよくわかります。
悪い例:
“`
売上を分析してください。
“`
良い例:
“`
sales_data.csv の2024年1月〜12月のデータを対象に、
商品カテゴリ別の月次売上合計を計算してください。
上位5カテゴリを棒グラフで比較し、outputs/category_sales_2024.png に保存してください。
“`
良い例では、対象・期間・集計方法・出力先がすべて明示されています。最初に「前提条件を確認してから分析を始めてください」と一言加えると、Claude Codeが仮定を置かずに確認してから動くため、的外れな分析結果を防げます。
また、分析の途中で「前の結果と比較して変化量も出してください」のように追加指示を重ねるのも有効です。会話形式で指示できるため、分析の方向性を柔軟に変えながら進められます。
繰り返し分析を自動で回す方法
毎週・毎月同じ分析を繰り返す場合は、スクリプト化して自動実行する仕組みを作るのがおすすめです。
まず、Claude Codeに次のように指示します。
“`
毎週月曜日に実行する想定で、weekly_report.csv を読み込み、
週次売上サマリーを計算してCSVとグラフで outputs/ に保存するスクリプトを
weekly_analysis.py として作成してください。
“`
Claude Codeが`weekly_analysis.py`を生成したら、動作確認をします。
```
weekly_analysis.py を実行して、正常に動くか確認してください。
```動作確認が取れたら、OSのスケジューラに登録することで完全自動化できます。
Macの場合はcronを使います。
```
crontab -e
```エディタが開いたら次の行を追加します(毎週月曜日9時に実行する例)。
```
0 9 * * 1 /usr/bin/python3 /path/to/weekly_analysis.py
```Windowsの場合はタスクスケジューラからPythonスクリプトを登録します。
スクリプトには、エラー時のログ出力を必ず含めておくのがおすすめです。「エラーが起きたときにログファイルに書き込む処理も追加してください」と指示するだけで、Claude Codeが例外処理を含むコードに書き換えてくれます。自動実行中に何か問題が起きた場合も、ログを見ればすぐに原因を特定できます。
Claude Codeでデータ分析する際によく抱く疑問
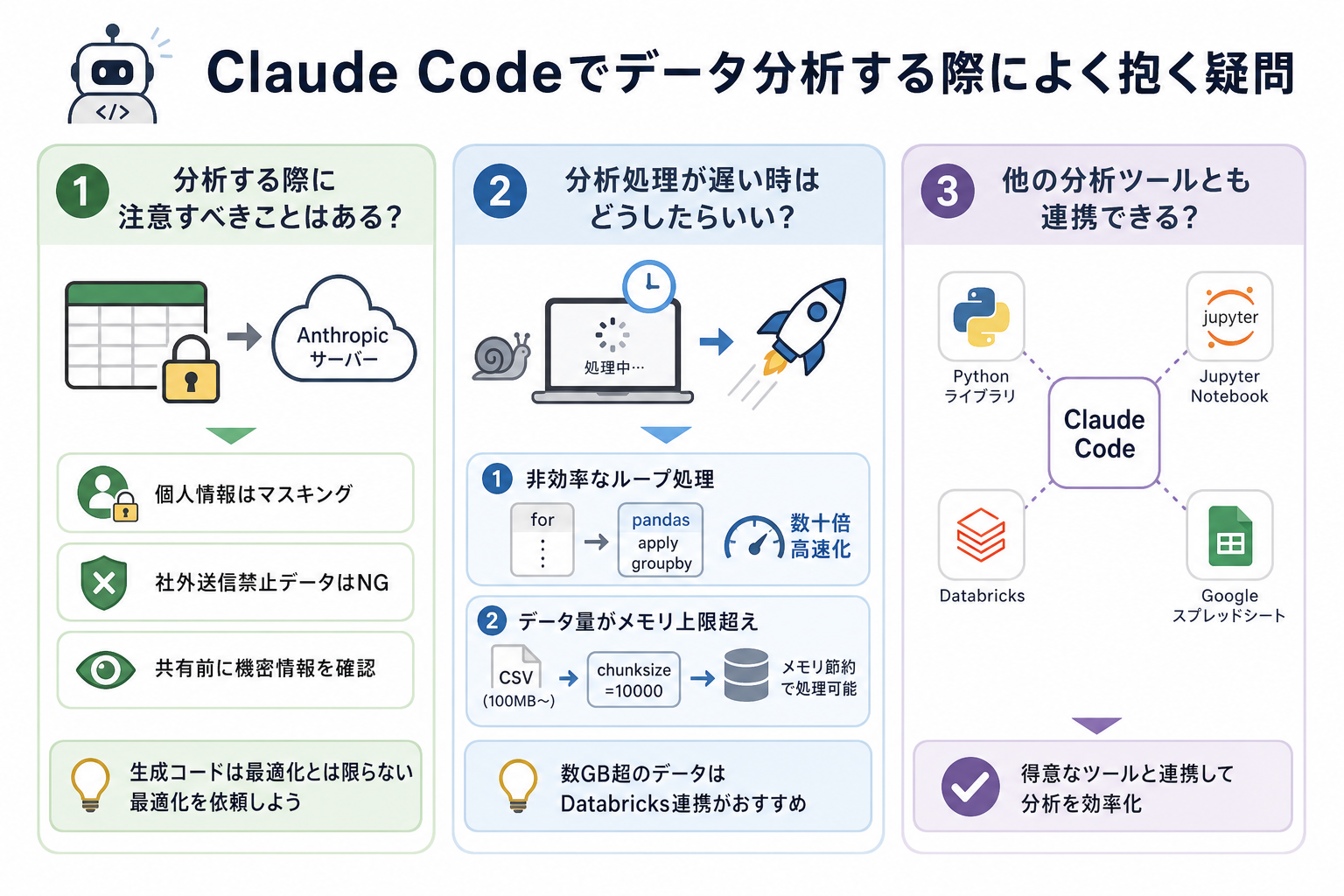
ここからは、Claude Codeでデータ分析する際によく抱く疑問を、3つにまとめて解説します。
分析する際に注意すべきことはある?
Claude Codeでデータ分析をする際は、個人情報・機密情報の取り扱いに注意が必要です。
Claude Codeに入力したデータは、Anthropicのサーバーへ送信されます。
Anthropicの利用規約では、商用プラン(Claude for WorkやAPI利用)のユーザーデータはモデルトレーニングに使用しないと明記されています。
ただし、個人向けプラン(Free・Pro・Max)ではオプトアウトしない限りデータがトレーニングに使用される可能性があるため、社内の機密情報や顧客の個人情報をそのまま入力することは避けるべきです。
実務での注意点は、次のとおりです。
- 個人情報(氏名・住所・電話番号)を含むデータはマスキング処理してから使う
- 社内規定で社外送信が禁止されているデータは使用しない
- 分析結果をスクリーンショットで共有する際も、機密情報が映り込んでいないか確認する
また、Claude Codeが生成するコードは必ずしも最適化されているとは限りません。大量のデータを扱う場合は、「このコードをより高速に処理できるよう最適化してください」と指示して、改善版を生成するなど工夫が必要です。
分析処理が遅い時はどうしたらいい?
分析処理が遅い原因は、大きく2つに分かれます。
1つ目は、Pythonコードの非効率なループ処理が原因のケースです。forループで行を1件ずつ処理しているコードは、pandasのベクトル演算(applyやgroupby)に書き換えると数十倍速くなることがあります。
下記の指示を出すことで、Claude Codeが最適版を生成します。
“`
このコードの処理が遅いです。pandasのベクトル演算を使って高速化してください。
(遅いコードをここに貼り付ける)
“`
2つ目は、データ量がローカル環境のメモリ上限を超えているケースです。100MB以上のCSVファイルを一度に読み込もうとすると、メモリ不足になる場合があります。メモリ不足であれば「chunksize=10000でファイルを分割読み込みするコードに変更してください」と指示すると、メモリを節約しながら処理できるコードに書き換えられます。
数GBを超えるデータを日常的に扱う場合は、後述のDatabricksとの連携を検討してください。
他の分析ツールとも連携できる?
Claude Codeは、他の分析ツールやプラットフォームと連携できます。代表的な組み合わせは、以下の通りです。
Excel・Googleスプレッドシートとの連携
ExcelファイルはPythonのopenpyxlライブラリ、Googleスプレッドシートはgspreadライブラリを使って読み書きできます。
“`
openpyxlを使ってsales_report.xlsxを読み込み、
Sheet1のB列からD列のデータを集計してください。
“`
上記の指示をすると、Claude Codeがライブラリのインストールからデータ読み込みまで自動で処理します。
Kaggleとの連携
Kaggleのデータセットは、Kaggle CLIを使ってローカルにダウンロードできます。
ダウンロードしたCSVファイルをClaude Codeに読み込ませて分析できるため、公開データセットを使った練習や検証に向いています。
“`
kaggle datasets download -d データセット名
“`
上記コマンドでダウンロード後、Claude Codeで「このデータセットのEDA(探索的データ分析)をしてください」と指示してください。データ概要の提示や分布確認、相関分析を自動で実行可能です。
Databricksとの連携
Databricksは、Apache Sparkベースのデータ分析基盤です。大規模データの処理や機械学習パイプラインの構築に使われます。
Claude Codeで生成したPythonコードをDatabricksのNotebookに貼り付けて実行することで、ローカル環境では処理できない大規模データへ対応できます。
Claude Codeを「コード生成機」、Databricksを「実行基盤」として使い分けるのが、大規模データ分析での定番の組み合わせです。
Databricks上でClaude APIを直接呼び出す構成も技術的には可能で、完全自動化パイプラインを構築したい企業での導入事例が増えています。
まとめ
本記事では、Claude Codeを使ったデータ分析の方法を解説しました。
まずは手元のCSVファイルをClaude Codeに読み込ませ、基本的な集計や可視化から試してみましょう。基本操作に慣れてきたら、定型作業のスクリプト化やExcel・Kaggleとの連携にも挑戦することで、分析業務をさらに効率化できます。


