
Claude Codeで文字起こしする方法【精度や制限&効率化するコツ】

Claude Codeって文字起こしにも使えるの?
どんなツールと組み合わせればいいのかな…
さまざまな作業を効率化できるツールとして話題のClaude Code。文字起こしにも活用できないかと気になっている人も多いですよね。
ただ、いざ文字起こししようにもどうClaude Codeを使えばいいか、わからない人もいるはず。文字起こしできる文量や対象ファイル・精度などを確認してから、使うかを決めたい人もいますよね。
そこでこの記事では、Claude Codeで実際に文字起こしを行う方法を解説します。活用するメリット・デメリットも紹介するので、ぜひ参考にしてください。
Claude Codeの特徴をおさらいしておきたい人は、次の記事を参考にしてください。

- Claude Code単体では音声の文字起こしはできず、外部ツールとの連携が必要
- 高精度かつ導入しやすいWhisperとの組み合わせがおすすめ
- 長時間音声は分割して処理すると安定して運用しやすい
『ClaudeCodeに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- ClaudeCodeに作業や仕事を任せる方法
- ClaudeCodeを使いこなすたった1つのコツ
- 業務効率化や収入獲得に活かすClaudeCodeの実演
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。この時間が、あなたを変える大きなきっかけになりますよ。
Claude Codeで文字起こしはできる?
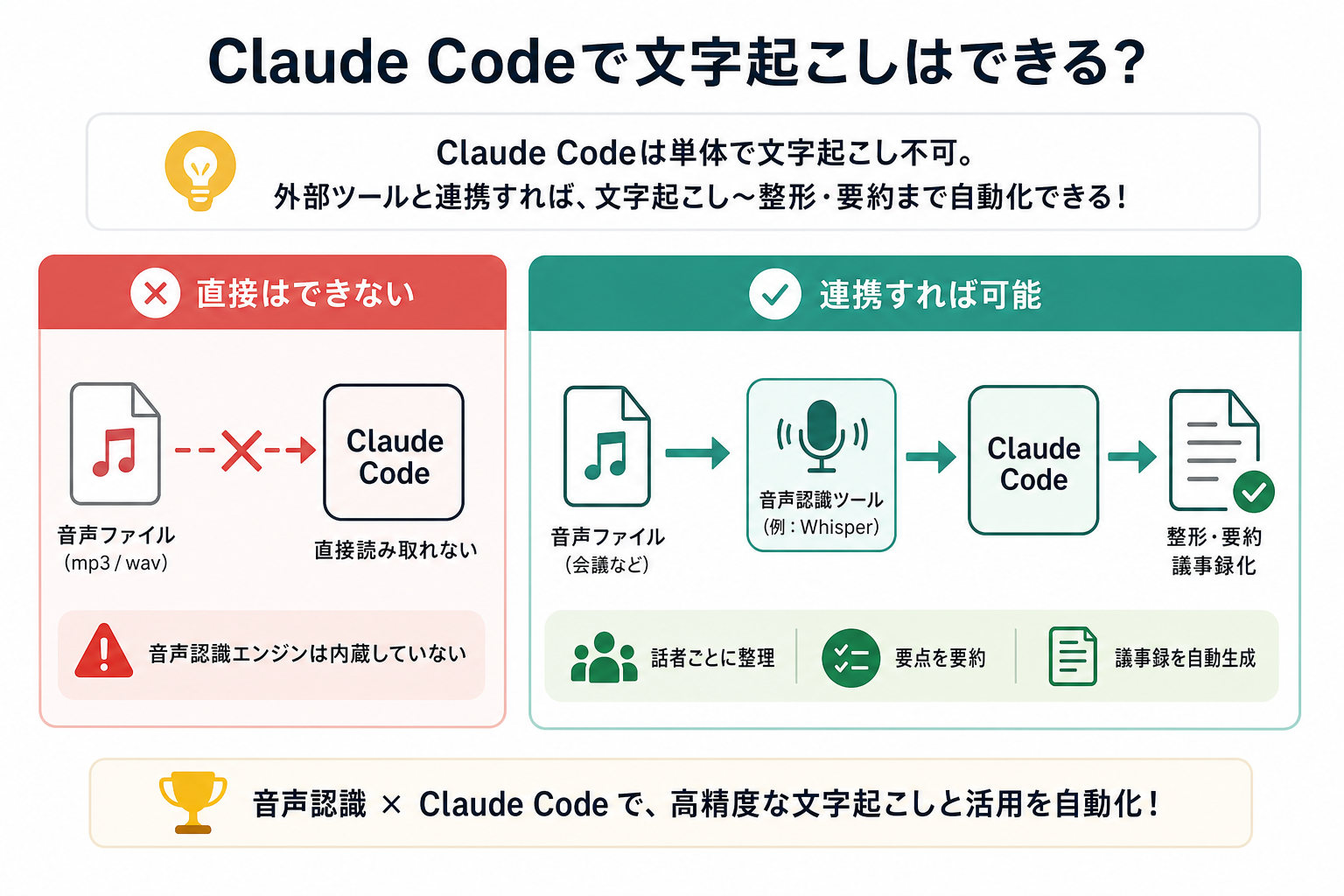
Claude Code単体には、文字起こし機能がありません。ただし、外部の音声認識ツールと組み合わせることで、高精度な文字起こしから整形・要約までを効率的に自動化できます。
ここからは下記の2点にわけて、Claude Codeと文字起こしの関係を解説します。
音声ファイルは直接処理できない
Claude Codeは、コードの生成・実行・修正を支援するAIコーディングツールです。音声認識機能は搭載されておらず、mp3やwavといった音声ファイルを直接テキストへ変換することはできません。
そのため、音声ファイルをそのままClaude Codeに渡しても内容を認識できず、文字起こしは実行されません。文字起こしを行う場合は、音声認識に特化した外部ツールを利用する必要があります。
外部ツールと連携すれば可能
Whisperなどの音声認識ツールで文字起こしを行い、その結果をClaude Codeに渡すことで、テキストの整形・要約・議事録化まで自動化できます。
たとえば、会議音声をWhisperで文字起こし後、Claude Codeで話者ごとに発言を整理して議事録を生成するといった活用が可能です。
音声認識とテキスト処理を組み合わせることで、文字起こし後の作業負担を大幅に削減できます。単なる文字起こしにとどまらず、情報整理やドキュメント作成まで一連の作業を効率化できる点が大きなメリットです。
Claude Code連携できる文字起こしツール
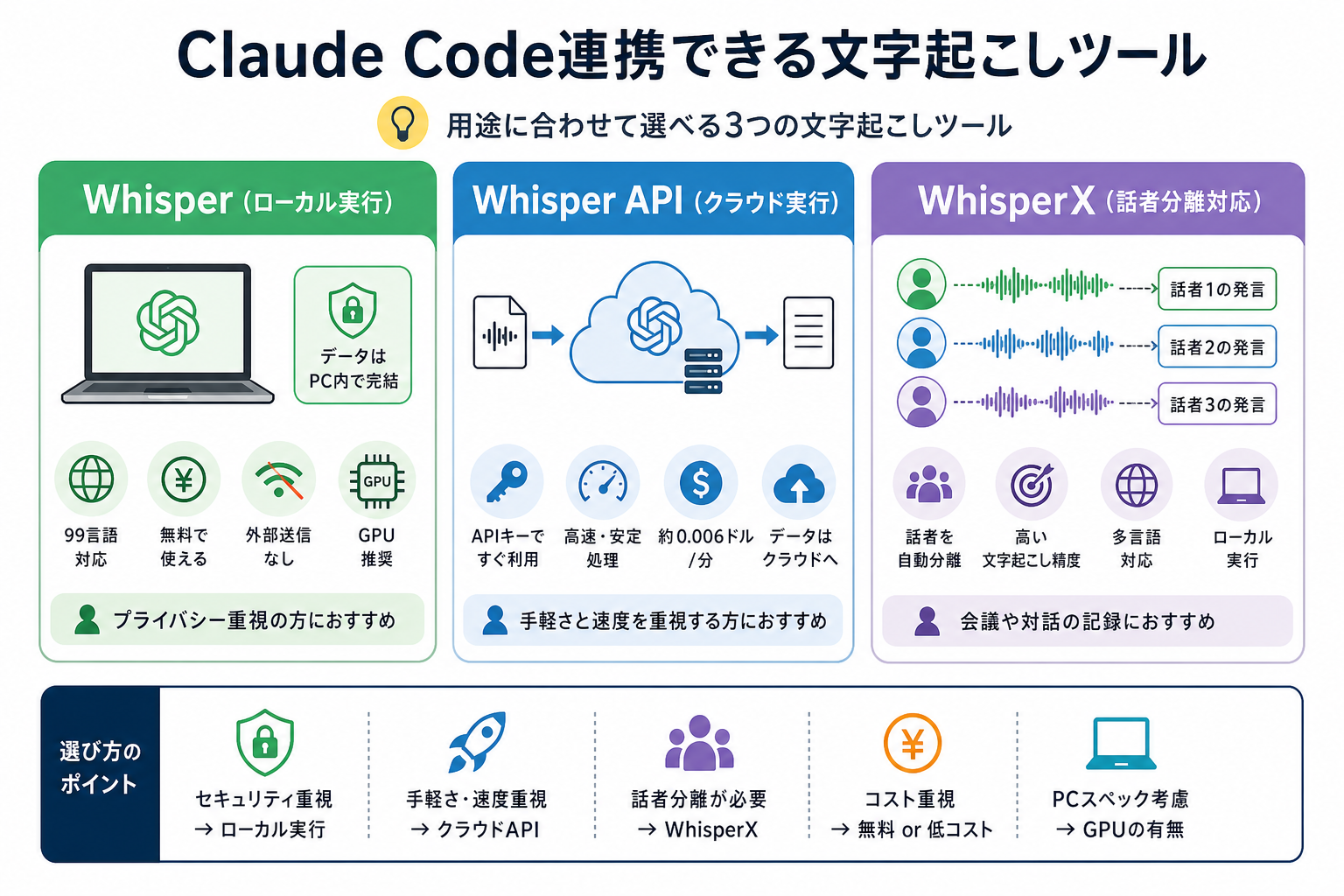
Claude Codeと連携できる音声認識ツールは複数あります。それぞれ実行環境や機能が異なるため、用途にあわせて選ぶことが大切です。
ここからはClaude Codeと連携できる文字起こしツールを、3つにまとめて解説します。
Whisper(ローカル実行)
Whisperは、OpenAIが開発したオープンソースの音声認識モデルです。自分のPC上で動作するため、音声データを外部サーバーに送信することなく文字起こしを実行できます。
日本語を含む多言語に対応しており、日常会話から専門用語まで高い精度で幅広く認識できる点が特徴です。また、モデルをダウンロードして利用するため、API利用料が発生せず無料で使い続けられます。
一方で、処理速度はPCのスペックに大きく左右されます。とくに長時間の音声を扱う場合は、GPU搭載PCのほうが快適に利用できます。
| 実行環境 | ローカル(自分のPC) |
|---|---|
| 対応言語 | 多言語(日本語対応) |
| 料金 | 無料 |
| データの外部送信 | なし |
| 必要スペック | GPU推奨 |
Whisper API(クラウド実行)
Whisper APIは、OpenAIが提供するクラウド型の音声認識サービスです。ローカルにモデルをインストールする必要がなく、APIキーを取得するだけですぐに文字起こしを始められます。
PCのスペックに依存せず安定した処理速度で利用できるため、導入の手軽さを重視する人に向いている点が特徴です。また、Claude CodeからAPIを呼び出すスクリプトを作成すれば、文字起こしから要約までの流れを自動化できます。
ただし、音声ファイルはOpenAIのサーバーへ送信されるため、機密性の高い会議音声や個人情報を含むデータを扱う場合は運用ルールを事前に確認しておきましょう。
| 実行環境 | クラウド(OpenAIサーバー) |
|---|---|
| 対応言語 | 多言語(日本語対応) |
| 料金 | 従量課金制 |
| データの外部送信 | あり |
| 必要スペック | 特になし |
WhisperX(話者分離対応)
WhisperXは、Whisperをベースに話者分離(スピーカーダイアリゼーション)機能を追加したオープンソースツールです。「誰がいつ何を話したか」を区別して出力できるため、会議やインタビューの文字起こしに適しています。
通常のWhisperでは発言内容のみが出力されますが、WhisperXを使うと「話者A:〇〇」「話者B:〇〇」のように、発言者ごとに整理されたテキストを取得できます。そのため、後から議事録を作成する際の負担を大きく減らせる点が特徴です。
ただし、導入にはpyannote.audioというライブラリの設定やHugging Faceのアカウント登録が必要です。Whisperより設定の難易度はやや高いため、まずは通常のWhisperから試すことをおすすめします。
| 実行環境 | ローカル(自分のPC) |
|---|---|
| 対応言語 | 多言語(日本語対応) |
| 料金 | 無料 |
| 話者分離 | 対応 |
| 必要スペック | GPU推奨 |
Claude Codeは文字起こしに活用すべき?
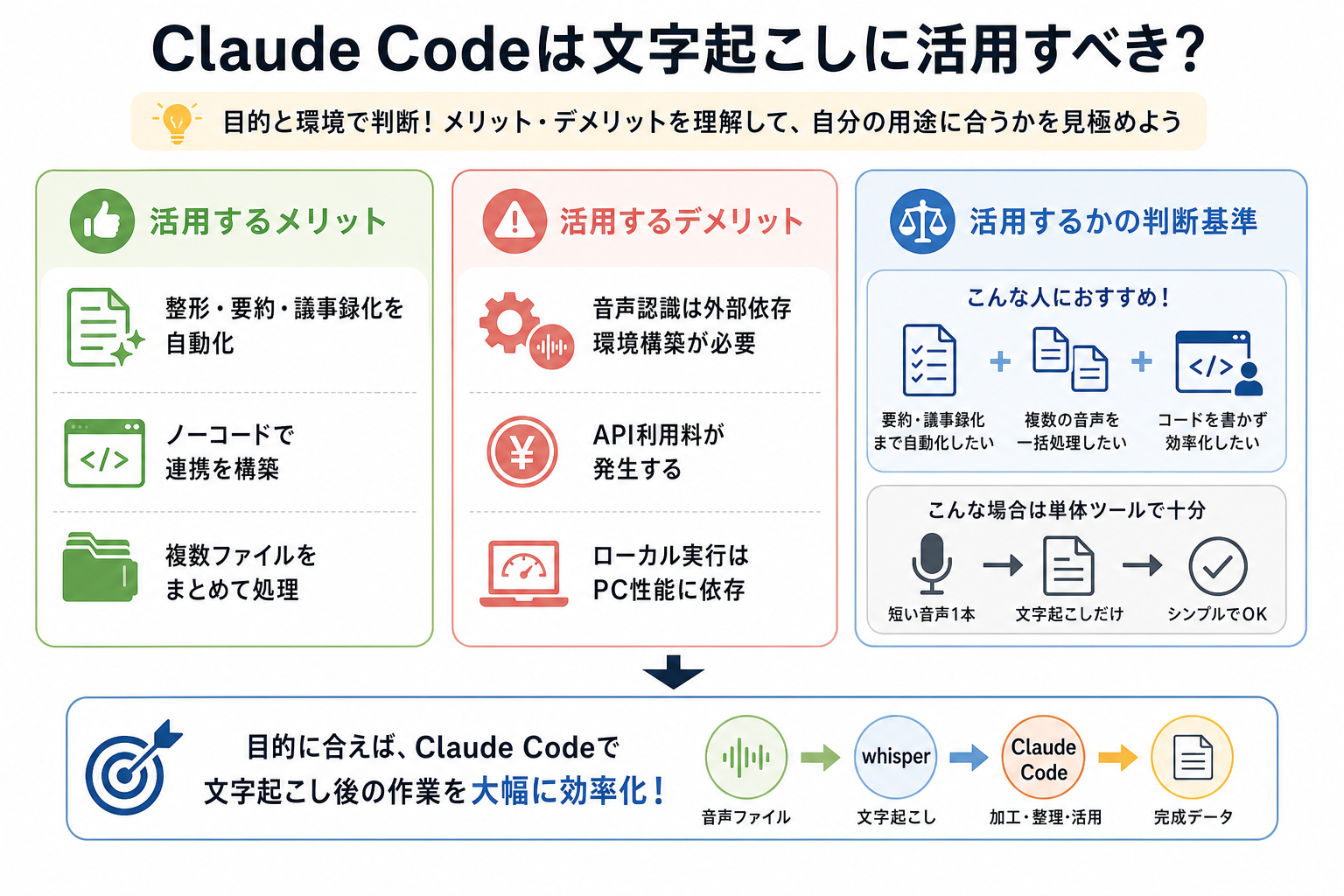
Claude Codeを文字起こしに活用するかどうかは、目的や環境によって異なります。単純な文字起こしだけが目的なのか、それとも要約や議事録作成まで自動化したいのかによって、導入する価値は大きく変わります。
ここからはメリット・デメリット・判断基準の3点にわけて解説します。
活用するメリット
Claude Codeを文字起こしに活用するメリットは、主に次の3つです。
- 文字起こし後の整形・要約・議事録化を自動化できる
- スクリプト作成を生成してもらえるため、プログラミング初心者でも導入しやすい
- 複数の音声ファイルをまとめて処理する仕組みを構築できる
最大のメリットは、文字起こし後のテキスト加工を効率化できる点です。Whisperなどが出力したテキストは、そのままでは読みにくい場合があります。しかし、Claude Codeに指示を出せば、句読点の補完や文章の整理、要約、議事録形式への変換まで自動で行えます。
また、「Whisperで文字起こしした結果をCSVに保存したい」あるいは「フォルダ内の音声ファイルを一括処理したい」と指示するだけで必要なPythonやBashスクリプトの生成を支援してもらえる点も魅力です。
活用するデメリット
Claude Codeを文字起こしに活用するデメリットは、主に次の3つです。
- 音声認識機能は搭載されておらず別途音声認識ツールが必要
- Claude Codeの利用には料金が発生する場合がある
- ローカル環境での文字起こしはPCスペックの影響を受ける
単純な文字起こしだけが目的なら、Claude Codeを介さず音声認識ツールを単体で使う方が手間が少ないです。たとえば、短い音声1本を文字起こしするだけなら、Whisperのコマンド1行で完結します。
特に注意したいのは、Claude Code自体が文字起こしを行うわけではない点です。実際の音声認識はWhisperやWhisperXなどの外部ツールが担当します。
そのため、短い音声を単発で文字起こしするだけであれば、Whisper単体や既存の文字起こしサービスを利用した方が手軽なケースもあります。
Claude Codeの強みは、文字起こし後の加工や自動化にあることを理解しておきましょう。
活用するかの判断基準
Claude Codeを文字起こしに活用するかどうかは「文字起こし後の作業をどこまで自動化したいか」を基準で判断するのがおすすめです。
Claude Codeの活用がおすすめな人は次のとおりです。
- 文字起こし後に要約・議事録化・整形まで自動化したい人
- 複数の音声ファイルをまとめて処理したい人
- プログラミング経験が少なくスクリプト作成を支援してほしい人
- 定型業務を自動化して作業時間を削減したい人
一方で、次のような人は必ずしもClaude Codeを導入する必要はありません。
「文字起こしすること」が目的なら専用ツールだけでも十分です。
しかし「文字起こし後の整理や活用まで効率化したい」のであれば、Claude Codeを組み合わせることをおすすめします。
Whisper×Claude Codeで文字起こしする手順
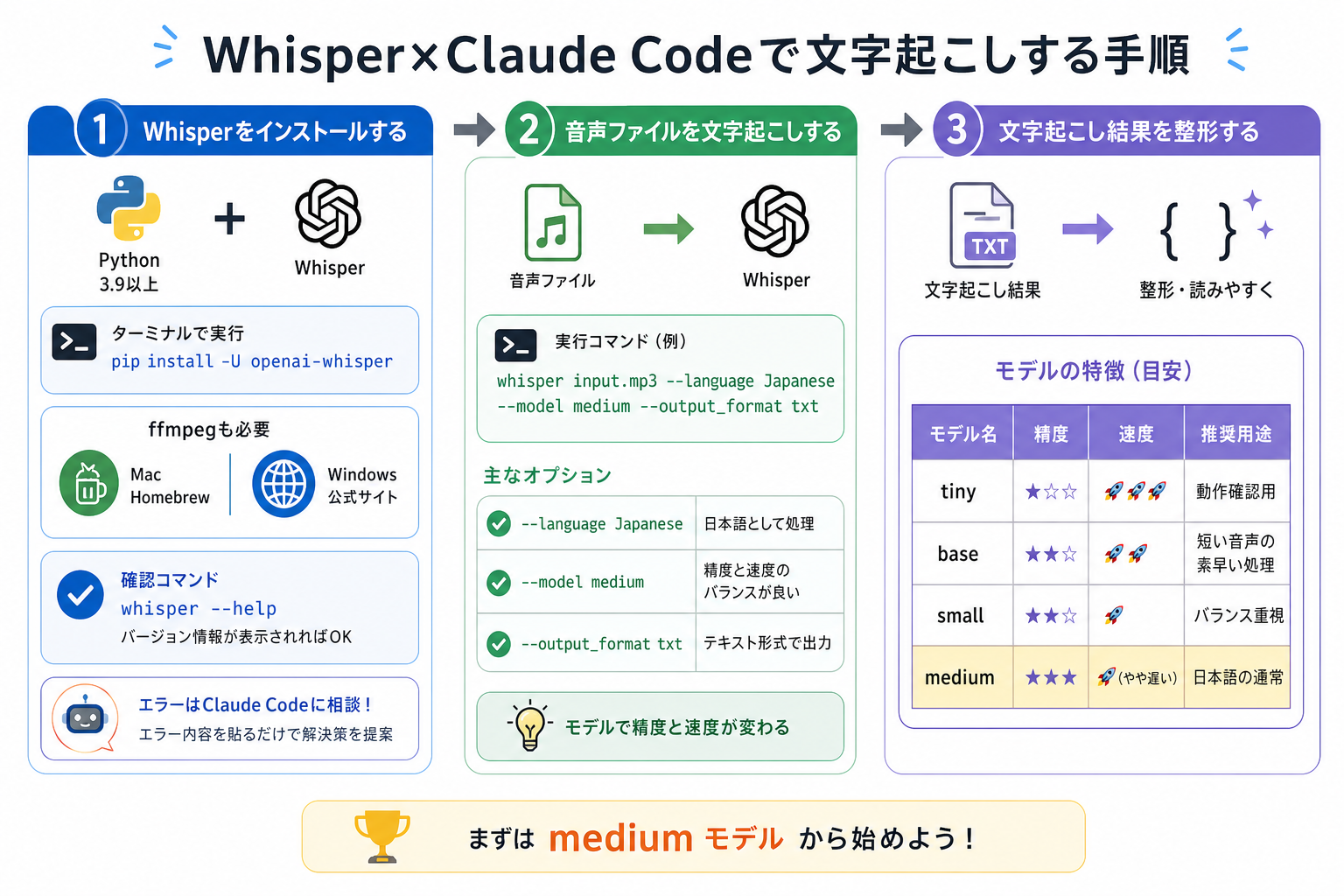
ここからはWhisperとClaude Codeを使った文字起こし手順を、3ステップにまとめて解説します。
1.Whisperをインストールする
まずWhisperを利用するために、Pythonと必要なツールをインストールします。
Whisperの利用にはPython 3.8以上が必要です。Pythonがインストールされていない場合は、先に導入しておきましょう。
続いて、ターミナル(Windowsの場合はPowerShellやコマンドプロンプト)で次のコマンドを実行してください。
```bash
pip install openai-whisper
```また、Whisperの動作にはffmpegが必要です。OSに応じてインストールしてください。
```bash
# Macの場合
brew install ffmpeg
# Ubuntuの場合
sudo apt install ffmpeg
```Windowsの場合は、ffmpeg公式サイトからダウンロードしてPATHを設定します。インストール後は、次のコマンドで正常に導入できているか確認しましょう。
```bash
whisper --help
```ヘルプ画面が表示されれば準備完了です。エラーが表示される場合は、PythonのバージョンやPATH設定を確認してください。
なお、インストール中にエラーが発生した場合は、Claude Codeへエラーメッセージを貼り付けることで原因の特定や解決策の提案を受けられます。
2.音声ファイルを文字起こしする
Whisperのインストールが完了したら、実際に音声ファイルを文字起こしします。
たとえば、audio.mp3を日本語で文字起こしする場合は次のコマンドを実行します。
```bash
whisper audio.mp3 --language Japanese --model medium
```各オプションの意味は次のとおりです。
| オプション | 内容 |
|---|---|
| `–language Japanese` | 日本語として音声を認識する |
| `–model medium` | 精度と速度のバランスがよいmediumモデルを利用する |
| `–output_format txt` | テキスト形式で出力する(省略時はtxtとvttとsrtが出力) |
Whisperには複数のモデルが用意されており、モデルサイズによって精度と処理速度が異なります。
| モデル名 | 精度 | 速度 | 推奨用途 |
|---|---|---|---|
| tiny | 低 | 最速 | 動作確認用 |
| base | やや低 | 速い | 短い音声の処理 |
| small | 中 | 普通 | バランス重視 |
| medium | 高 | やや遅い | 日本語の通常用途に最適 |
| large | 最高 | 遅い | 精度最優先 |
初めて利用する場合は、精度と処理速度のバランスがよいmediumモデルがおすすめです。
処理が完了すると、音声ファイルと同じフォルダに文字起こし結果のテキストファイルが生成されます。
3.文字起こし結果を整形する
Whisperが出力したテキストは、そのままでは読みにくい場合があります。句読点が不自然だったり、話者の区別がなかったりするためです。
そこで、生成されたテキストをClaude Codeに渡して整形・要約・議事録化します。
たとえば、次のようなプロンプトを入力します。
“`
以下の文字起こしテキストを議事録形式に整えてください。
句読点を補い、内容ごとに段落を整理してください。
最後に重要なポイントを箇条書きで3点にまとめてください。
[Whisperの出力テキストをここに貼り付け]
“`
Claude Codeはテキストの整形だけでなく、会議要約やタスク抽出、アクションアイテムの整理などにも対応できます。また、複数のファイルをまとめて処理したい場合は、Claude Codeに自動化スクリプトの作成を依頼すると効率的です。
たとえば、次のように依頼できます。
“`
指定フォルダ内のすべてのmp3ファイルをWhisperで文字起こしし、
結果をtxtファイルとして保存するPythonスクリプトを作成してください。
“`
このように、Whisperで音声認識を行い、Claude Codeでテキスト処理や自動化を行うことで、文字起こしから要約・議事録作成までの作業を効率化できます。
Claude Codeで文字起こしする際の注意点
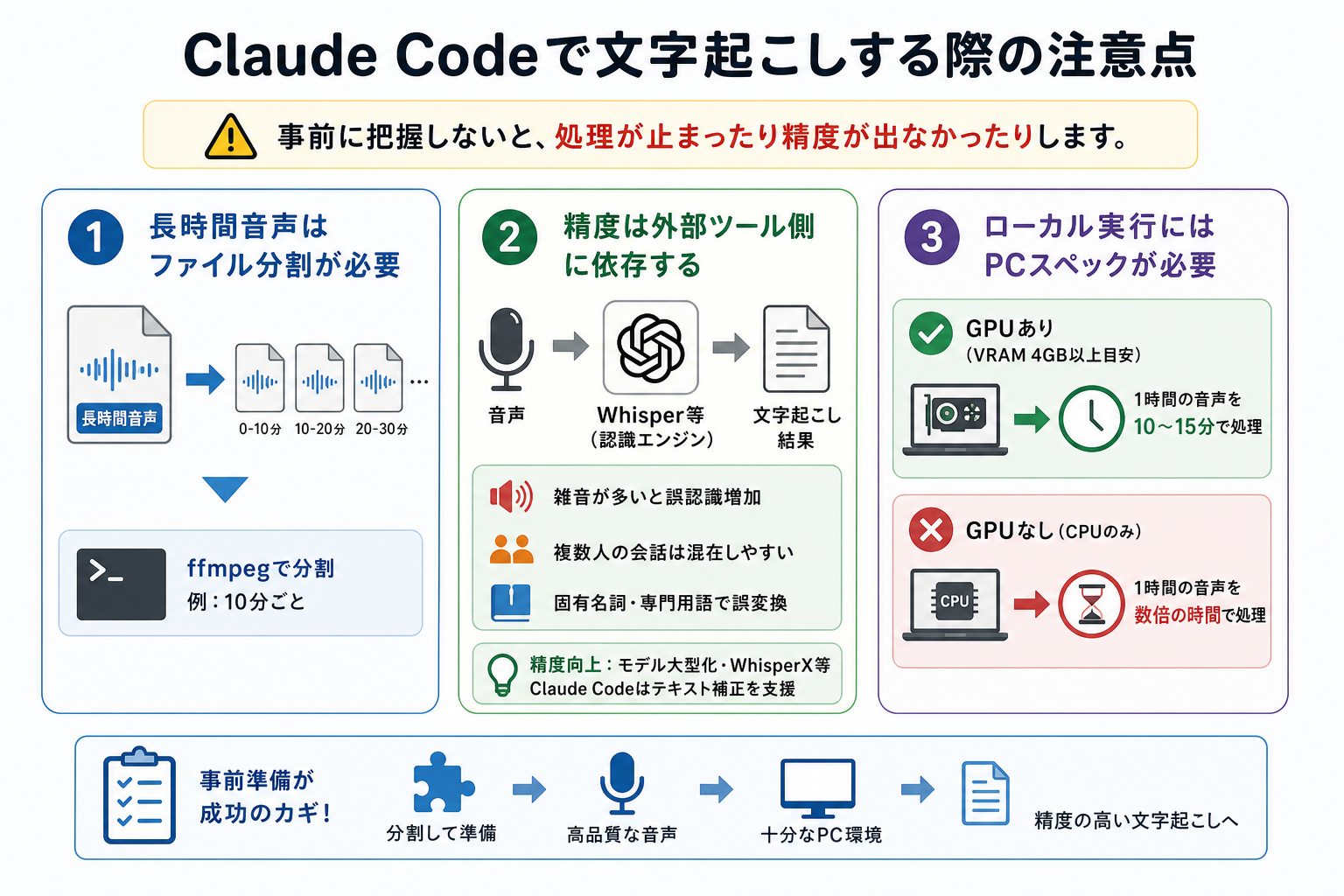
Claude CodeとWhisperを組み合わせることで、文字起こしから要約・議事録作成まで効率化できます。ただし、運用するうえではいくつか注意しておきたいポイントがあります。
ここからは下記の3つの注意点を解説します。
長時間音声はファイル分割が必要なケースも
長時間の音声ファイルを一度に処理すると、メモリ使用量が増加し、処理速度の低下やエラーの原因になる場合があります。
とくにローカル環境でWhisperを実行する場合は、30分〜1時間を超えるの音声ファイルはあらかじめファイルを分割してから処理することをおすすめします。
音声ファイル分割にはffmpegを利用可能です。たとえば、10分ごとに分割する場合は次のコマンドを実行します。
```bash
ffmpeg -i audio.mp3 -f segment -segment_time 600 -c copy output_%03d.mp3
```また、Claude Codeに「音声ファイルを10分ごとに分割するスクリプトを作成して」と依頼すると、自動化用のPythonやBashスクリプトを生成してもらうことも可能です。
分割したファイルをまとめて文字起こしする仕組みも構築できるため、大量の音声を扱う場合は積極的に活用しましょう。
精度は外部ツール側に依存する
Claude Codeは文字起こしの精度に直接影響しません。認識精度を左右するのは、WhisperやWhisperXなど連携している音声認識ツールの性能です。
音声品質・話者の声の明瞭さ・専門用語の多さによって、文字起こし精度は大きく変わります。具体的には次のような要因が精度に影響します。
- 録音環境に雑音が多い
- 複数人が同時に発言している
- 固有名詞や専門用語が頻繁に登場する
- 音量が小さいまたは音声が不明瞭である
精度を改善したい場合は、Whisperのモデルをmediumからlargeに変更したり、WhisperXで話者分離機能を利用したりする方法が有効です。
ローカル実行にはPCスペックが求められる
Whisperをローカル環境で利用する場合、PCのスペックが処理速度に大きく影響します。とくに高精度なmediumやlargeモデルを利用する場合は、GPUを搭載したPCのほうが快適に処理できます。
一般的な目安は次のとおりです。
| 環境 | 処理速度の目安 | 推奨モデル |
|---|---|---|
| GPU (VRAM 8GB以上) | 高速 | large |
| GPU (VRAM 4GB) | 比較的高速 | medium |
| CPU (8コア以上) | やや遅い | small~medium |
| CPU (4コア以下) | 遅い | base~small |
なお、実際の処理速度はCPU・GPUの性能や音声品質、利用するWhisperのバージョンによって大きく変動します。
もし、PCスペックに不安がある場合は、ローカル版WhisperではなくWhisper APIの利用も検討しましょう。クラウド上で処理されるため、PC性能に左右されず安定した速度で文字起こしを実行できます。
ローカル環境でClaude Codeを使う方法を詳しく知りたい人は、次の記事を参考にしてください。

まとめ
本記事では、Claude Codeで文字起こしを行う方法や、連携におすすめのツール、具体的な手順を解説しました。
Claude Code単体では音声の文字起こしはできませんが、WhisperやWhisperXと組み合わせることで、文字起こしから要約・議事録作成までを効率化できます。
まずは1本の音声ファイルでWhisper連携を試し、文字起こしから議事録化までの基本的な流れを体験してみましょう。慣れてきたら複数ファイルの一括処理やWhisperXによる話者分離などに挑戦することで、さらなる業務効率化を実現できます。


