
Claude Codeで情報収集を自動化!設定方法をわかりやすく解説

Claude Codeって情報収集に使えるの?
自動でニュースとか集めてくれるのかな…
さまざまな作業を効率化・自動化できると話題のClaude Code。「情報収集も自動化できるのでは?」と気になっている人も多いですよね。
ただ、Claude Codeで情報収集を自動化しようにも、何から始めればいいのかわからない人もいるはず。
そこでこの記事ではジャンル別の活用例も交え、Claude Codeで情報収集を自動化する手順を解説します。実際のスクリプト例も紹介するので、ぜひ参考にしてください。
Claude Codeの特徴をおさらいしておきたい人は、次の記事を参考にしてください。

- RSSとAPIを使い分けることで、ニュースから競合調査まで対応できる
- 毎日30分の手動収集は年間182時間以上の損失になる
- 収集データはSlackやNotionへの自動出力で即チーム共有できる
『ClaudeCodeに興味はあるけど、どうやって使えばいいんだろう…』
そんな方へ、
- ClaudeCodeに作業や仕事を任せる方法
- ClaudeCodeを使いこなすたった1つのコツ
- 業務効率化や収入獲得に活かすClaudeCodeの実演
を、無料のオンラインセミナーで凝縮してお伝えします!
パソコンはもちろん、スマホから気軽に参加OK。この時間が、あなたを変える大きなきっかけになりますよ。
Claude Codeで情報収集は自動化できる
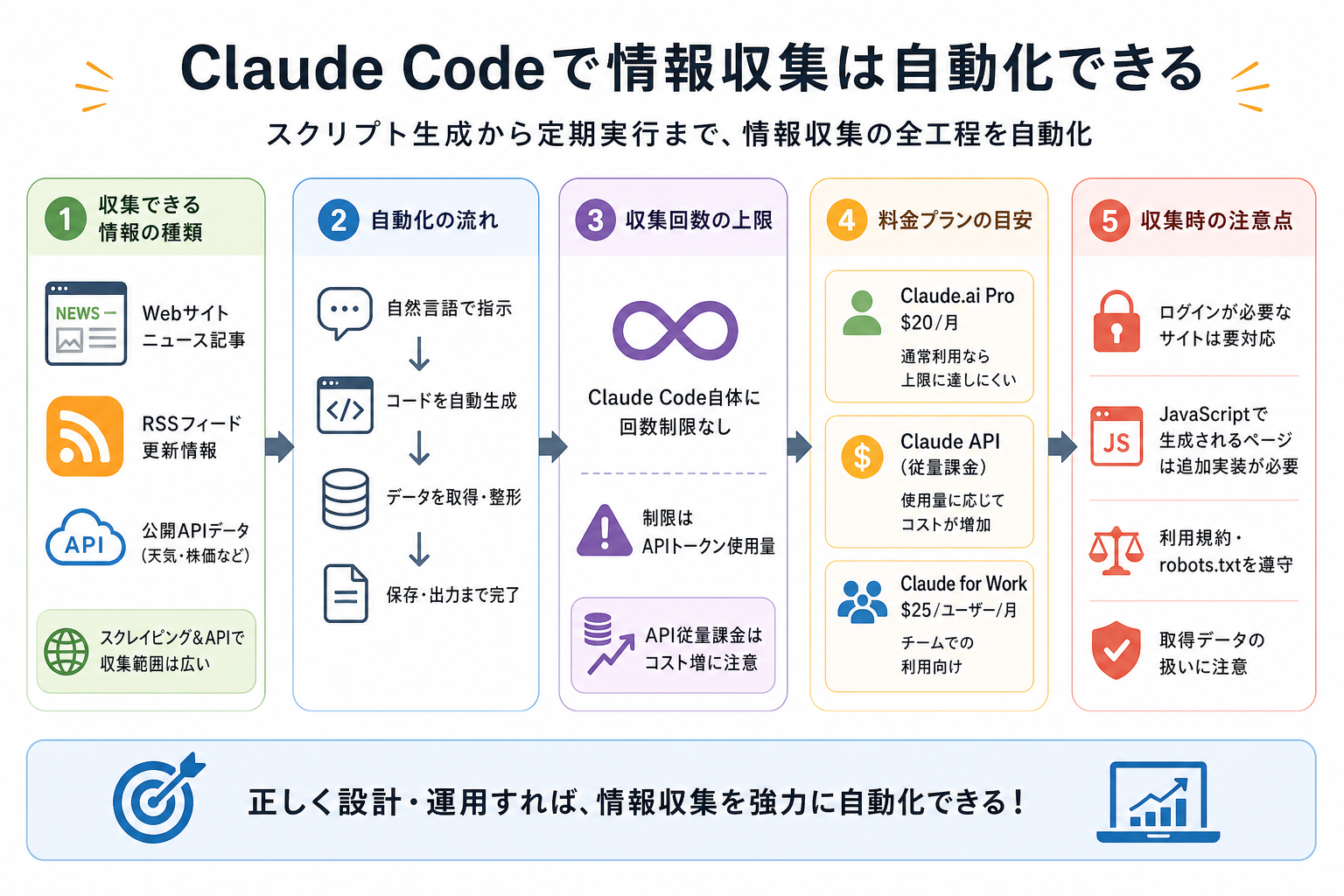
Claude Codeは、スクリプトの生成から定期実行の仕組み作りまで、情報収集の全工程を自動化できます。
単にAIに質問するだけでなく、Webスクレイピングの実装やAPI連携のコード生成を自然言語で指示できるのが強みです。
ここからは、Claude Codeで収集できる情報の種類や上限、注意点などを解説します。
収集できる情報の種類・範囲
Claude Codeで情報収集できる対象は、主に次の3種類です。
- Webサイト・ニュースサイトの記事(スクレイピング)
- RSSフィードから取得できるブログ・メディアの更新情報
- 公開APIで提供されるデータ(天気・株価・GitHubのトレンド等)
スクレイピングとAPIの両方を扱えるため、収集範囲は非常に広いです。
Claude Codeへの指示例は「PythonでRSSフィードを取得するスクリプトを書いて」です。指示するだけで、動作するコードを即座に生成してくれます。
取得した記事のタイトル・URL・公開日を整形して保存するところまで、1回の会話で完成させることも可能です。ただし、対象サイトがログインを要求する場合や、JavaScriptで動的に生成されるページは、追加の実装が必要になります。
たとえば、自社のサービスに関連するニュースや情報を毎朝集めたり、株式投資に必要な株価情報をまとめたりする使い方が可能です。
収集回数の上限
Claude Code自体には、情報収集回数の制限はありません。
ただし、Claude Codeではプランごとにトークン上限が設定されています。具体的な上限値は明記されていませんが、一定利用量を超えると利用できなくなる可能性があります。
APIプランは、使用したトークン数に応じて費用が増加する仕組みです。
| プラン | 月額料金 | 特徴 |
|---|---|---|
| Claude.ai Pro | 18ドル | 通常利用なら上限に達しにくい |
| Claude API(従量課金) | 使用量に応じて変動 | 利用量に比例してコストが増加 |
| Claude for Work | 27.5ドル/ユーザー | チームでの利用向け |
情報収集を自動化する場合、コストが積み上がりやすいのはAPIの従量課金プランです。
スクリプトのループ処理でAPIを大量呼び出しすると、想定外の費用が発生します。Anthropicのダッシュボードで使用量を定期的に確認するようにしてください。
Claude CodeでのAPI利用について詳しく知りたい人は、次の記事を参考にしてください。

収集する際の注意点
Claude Codeで情報収集を行うときに、事前に把握しておくべき注意点が3つあります。
著作権・利用規約への配慮がとくに重要です。
- 著作権・利用規約の確認
- アクセス頻度の制御
- 個人情報の取り扱い
情報収集を行うときは、著作権や利用規約に注意しましょう。収集先のサイトが「クローリング禁止」を定めている場合、スクレイピングは規約違反になります。robots.txtを必ず確認してください。
また、短時間に大量のリクエストを送ると、サーバーに負荷をかけアクセス禁止(IPブロック)を受けるリスクがあります。リクエスト間に、1〜3秒の待機処理を入れることを基本とし、アクセスするサイトから迷惑行為と受け取られないようにしましょう。
なお、氏名・メールアドレスなど個人情報が含まれるデータを収集・保存する場合は、個人情報保護法への対応が必要です。
Claude Codeでは簡単に情報収集が行えますが、権利や利用規約を守ったうえで利用する必要があります。
【ジャンル別】Claude Codeでの情報収集例

Claude Codeは、目的に応じてさまざまなジャンルの情報を収集できます。ジャンルごとに適した収集元と指示の出し方が異なるため、それぞれの特徴を理解しておくことが大切です。
ここからは下記のジャンル別に、Claude Codeでの情報収集例を解説します。
ニュースの収集例
ニュースの収集を行う場合、RSSフィードの活用が効果的です。
NHKや日本経済新聞など主要メディアの多くはRSSを公開しており、Claude Codeで活用すれば効率的にニュース情報を入手・分析できます。
Claude Codeへの指示例は、次のとおりです。
“`
Pythonで以下のRSSフィードを取得し、今日の記事タイトルとURLをMarkdownで出力するスクリプトを書いてください。
対象RSS: https://www.nhk.or.jp/rss/news/cat0.xml
“`
上記スクリプトを毎朝自動実行することで、手作業でのニュース探しが不要になります。
取得した記事をキーワードでフィルタリングする処理を追加すれば、「AIに関するニュースだけ」を抽出する絞り込みも可能です。
Claude Codeに「記事タイトルに『AI』が含まれるものだけを抽出する処理を追加して」と続けて指示するだけで実装できます。
ビジネス業界動向の収集例
業界動向の収集には、IR情報・プレスリリース・業界団体のレポートが主な収集源になります。
Claude Codeへの指示例は、次のとおりです。
“`
Pythonで「https://prtimes.jp/」のIT業界カテゴリのRSSを取得し、
今週のプレスリリースを企業名・タイトル・URLの形式でCSVに保存するスクリプトを書いてください。
“`
収集結果をCSVで保存しておくと、月次・週次でのトレンド比較が容易になります。
さらに、収集した各記事の本文をClaude Codeに渡して「この記事の要点を3行でまとめて」と指示すれば、要約レポートの自動生成も可能です。担当者が毎朝メディアを読み込み、動向を把握する手間を大幅に短縮できます。
技術トレンドの収集例
技術トレンドの把握には、GitHubのトレンドリポジトリやQiita・Zennの人気記事から情報収集するのがおすすめです。
GitHubはトレンドAPIが非公式のため、HTMLをスクレイピングするか、PyGitHubライブラリを使えば取得できます。Claude Codeへの指示例は、次のとおりです。
“`
Pythonで「https://github.com/trending」を取得し、
今日のトレンドリポジトリの名前・スター数・説明をMarkdownの表で出力するスクリプトを書いてください。
“`
週次でGitHubトレンドを記録しておくと、注目技術の移り変わりを時系列で把握できます。
Qiitaは公式APIが公開されており、APIキーを取得するだけで安定して記事データを収集できます。Claude Codeに「QiitaのAPIを使って今週のいいね数上位10件を取得するスクリプトを書いて」と指示すれば、APIドキュメントを参照した実装コードを生成可能です。
競合リサーチの収集例
競合調査では、対象企業の公式ブログ・採用ページ・SNS投稿を定期収集するのが効果的です。
競合企業の公式サイトには、商品情報や今後の計画など自社のビジネスに活かせる情報がたくさん含まれます。そのまま真似するのはダメですが、参考となる情報です。
Claude Codeへの指示例は、次のとおりです。
“`
Pythonで競合他社3社(A社・B社・C社)の公式ブログRSSを取得し、
過去30日以内の新規記事を企業名別にまとめてMarkdownで出力するスクリプトを書いてください。
“`
競合の発信頻度・トピックを定点観測することで、自社の戦略立案に活用できます。
X(旧Twitter)の公式アカウントをモニタリングしたい場合は、X APIの利用申請が必要です。Basic Tierは月200ドルかかるため、SNSモニタリングツールとコストを比較したうえで選択しましょう。
Claude Codeで情報収集は自動化すべき?
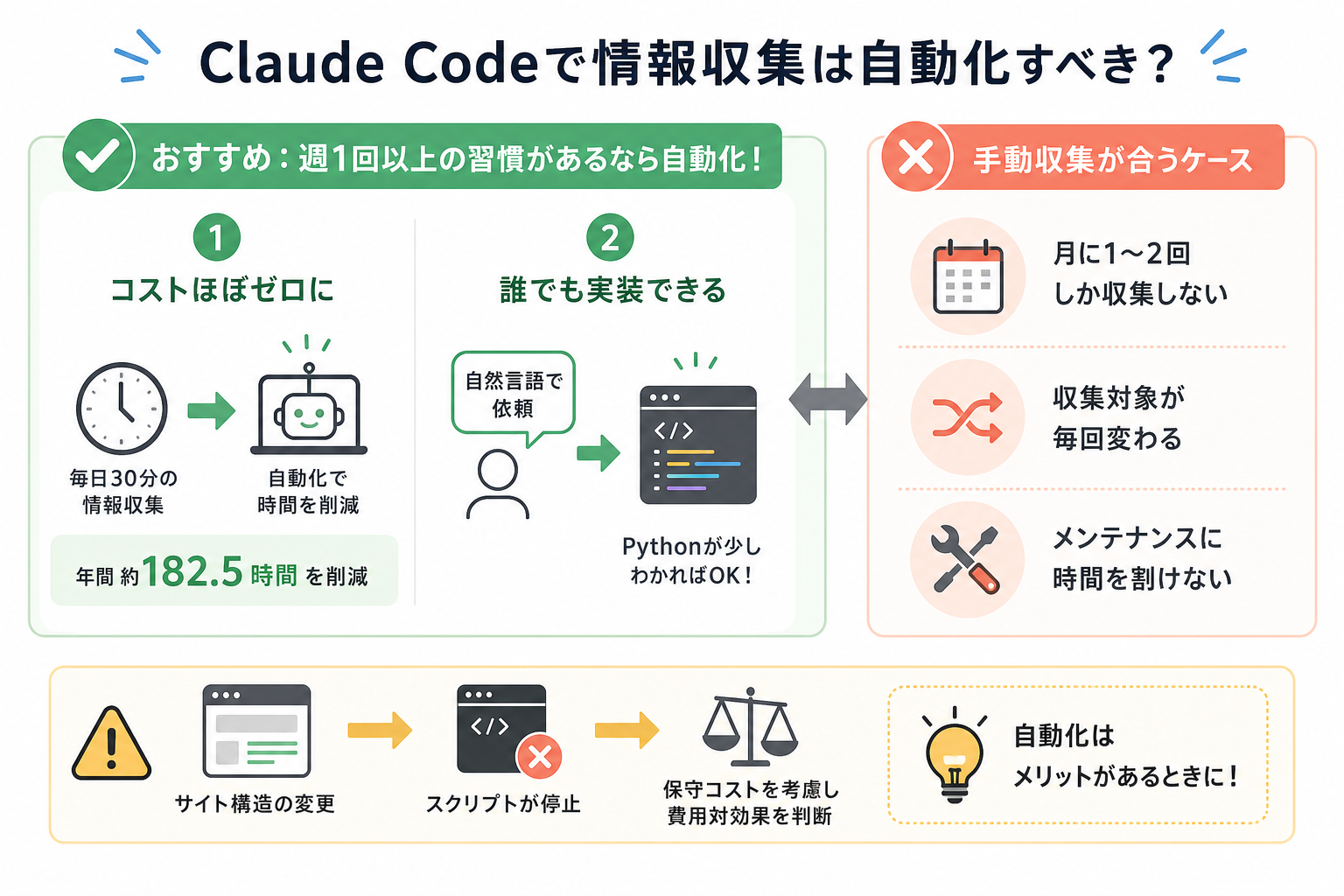
結論として、週1回以上同じ情報を確認する習慣があるなら、Claude Codeによる自動化をおすすめします。
繰り返し行う情報収集は、一度スクリプトを組めば以降のコストがほぼゼロです。毎日30分かけてニュースを確認している場合、30分×365日÷60で計算すると年間182.5時間の作業になります。自動化すれば、作業時間と人員をまるごと削減できます。
加えて、Claude Codeは自然言語でスクリプトを生成できるため、プログラミング経験が少ない人でも利用可能です。「Pythonが少しわかる」程度のスキルがあれば、生成されたコードを読み解きながら自分の環境に合わせた調整が可能であり、自動化の仕組みを作りやすいのが魅力です。
ただし、次の場合は自動化よりも手動収集の方が合っています。
- 月に1〜2回しか情報収集しないケース
- 収集対象が毎回変わるケース
- スクリプトのメンテナンスに時間を割けないケース
月1~2回など低頻度で情報収集を行う場合や、収集対象が変わりやすいケースでは手動収集がおすすめです。
自動化したスクリプトは、収集先のサイト構造が変更されると動きません。保守の手間を考慮したうえで、自動化の費用対効果を判断してください。
Claude Codeで情報収集を自動化する手順
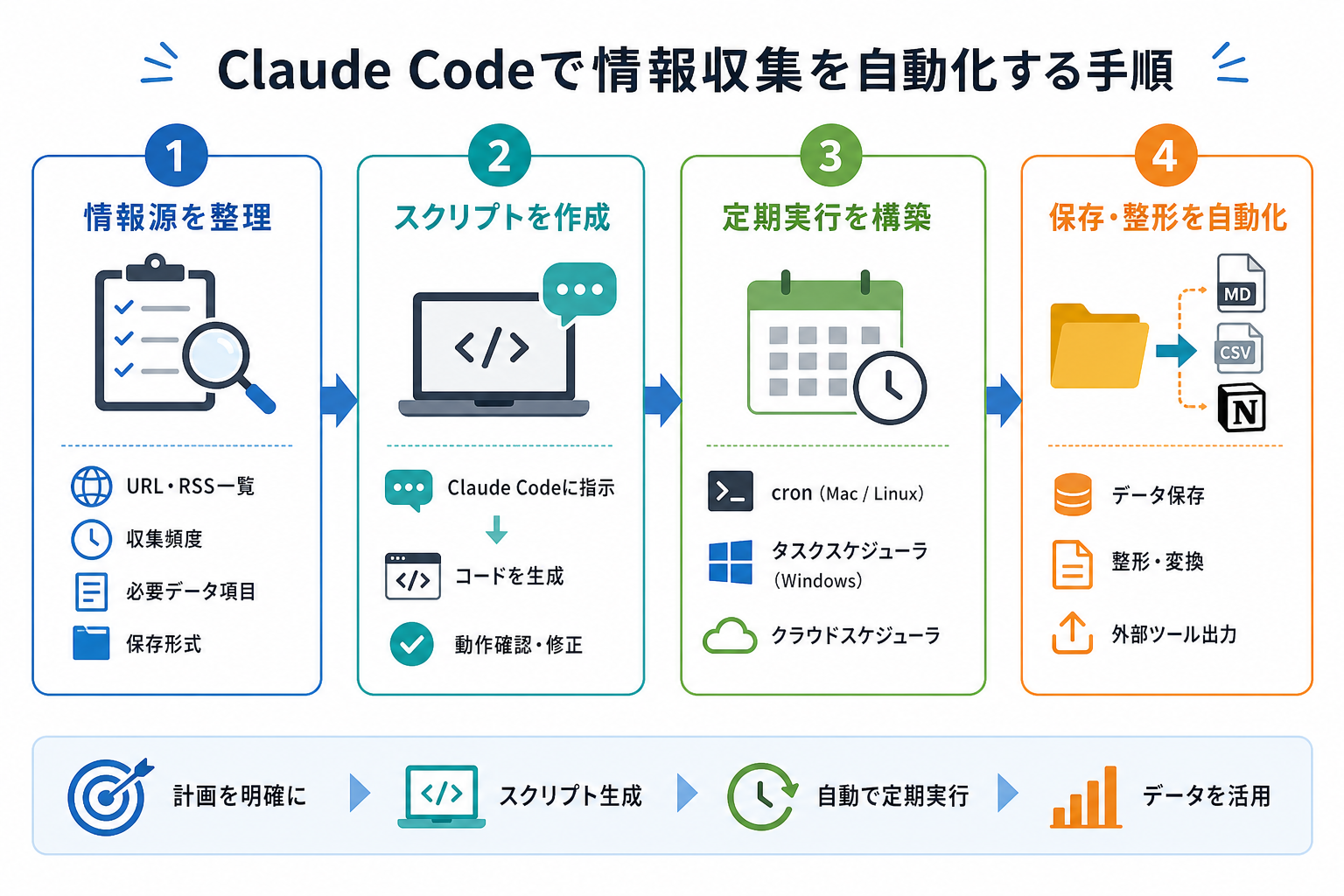
ここからはClaude Codeで情報収集を自動化する手順を、4ステップで解説します。
1.収集したい情報源を整理する
最初に、「何を・どこから・どのくらいの頻度で」収集するかを整理します。
整理しておくべき項目は、次のとおりです。
- 収集対象のURL・RSS一覧
- 収集頻度:毎日・毎週・毎時間のいずれかを決める
- 必要なデータ項目:タイトル・URL・公開日・本文のうち何が必要かを決める
- 保存形式:MarkdownファイルかCSVか、Notionなど外部ツールへの出力かを選ぶ
まずは、収集対象のURL・RSS一覧を作成し、収集したいデータを明確にしましょう。そのうえで、収集頻度や集めたいデータ項目、保存形式などを決めてください。
情報源の整理を怠ると、自動化に必要なスクリプト作成後に大幅な修正が必要になります。希望のデータを収集するためにも、収集する情報源は整理しましょう。
2.情報取得するスクリプトを作成する
情報源を整理したら、Claude Codeにスクリプトの生成を依頼します。
RSSフィードの取得を例に、Claude Codeへの指示と生成されるコードの流れを示します。
指示文の例:
“`
Pythonでfeedparserを使い、以下のRSSフィードを取得するスクリプトを書いてください。
https://www.nhk.or.jp/rss/news/cat0.xml
https://feed.rss.yahoo.co.jp/rss/news/topics/economic/index.xml
取得した記事のタイトル・URL・公開日を辞書のリストとして返す関数を作成し、
最後にprint()で確認できるようにしてください。
“`
Claude Codeが生成するコードの例:
```python
import feedparser
from datetime import datetime
def fetch_rss_feeds(urls: list[str]) -> list[dict]:
articles = []
for url in urls:
feed = feedparser.parse(url)
for entry in feed.entries:
articles.append({
"title": entry.title,
"url": entry.link,
"published": entry.get("published", "不明")
})
return articles
urls = [
"https://www.nhk.or.jp/rss/news/cat0.xml",
"https://feed.rss.yahoo.co.jp/rss/news/topics/economic/index.xml"
]
articles = fetch_rss_feeds(urls)
for article in articles:
print(article)
```生成されたコードはそのまま動くケースが多いですが、環境によってライブラリのインストールが必要です。
`pip install feedparser` のような追加インストールが必要な場合も、Claude Codeが指示文の中で明示してくれます。エラーが出た際はエラーメッセージをそのままClaude Codeに貼り付ければ、修正コードを出力可能です。
3.定期実行の仕組みを構築する
スクリプトが完成したら、定期的に自動実行する仕組みを構築します。
主な定期実行の手段は、次の3つです。
| 方法 | 対象OS | 難易度 | 特徴 |
|---|---|---|---|
| cron | Mac/Linux | 低 | コマンドラインで設定、無料 |
| タスクスケジューラ | Windows | 低 | GUIで設定可能 |
| GitHub Actions | すべて | 中 | クラウド実行、無料枠あり |
ローカル環境ならcron、PCを常時起動できない場合はGitHub Actionsをおすすめします。
cronの設定例をClaude Codeに生成させる場合は次のように指示します。
“`
毎朝8時にPythonスクリプト「/home/user/collect_news.py」を実行するcronの設定を教えてください。
“`
Claude Codeは `crontab -e` で開くファイルに追記する行を、そのままの形式で出力してくれます。コピーして貼り付けるだけで設定が完了します。
4.取得データの保存/整形を自動化する
次は、取得データの保存や整形を自動化する処理を作成しましょう。
収集したデータをそのまま保存すると、後から検索・活用が難しくなります。取得と同時にデータを整形・保存する処理を組み込むことで、情報活用の効率を高められます。
Claude Codeへの指示例は、次のとおりです。
“`
先ほどのスクリプトに以下の処理を追加してください。
1.取得した記事リストを、収集日付をファイル名にしたJSONファイルで保存する
(例:2025-07-10_articles.json)
2.重複URLが含まれる場合は除外する
3.公開日が今日のものだけを保存する
“`
追加したい処理を箇条書きで具体的に伝えると、Claude Codeは既存のコードに差分を加えた形で修正版を出力します。保存ファイルをMarkdownに変更したい場合も、「JSON形式をMarkdown形式に変えて」と続けて指示するだけで対応できます。
Claude Codeで収集した情報の活用テクニック
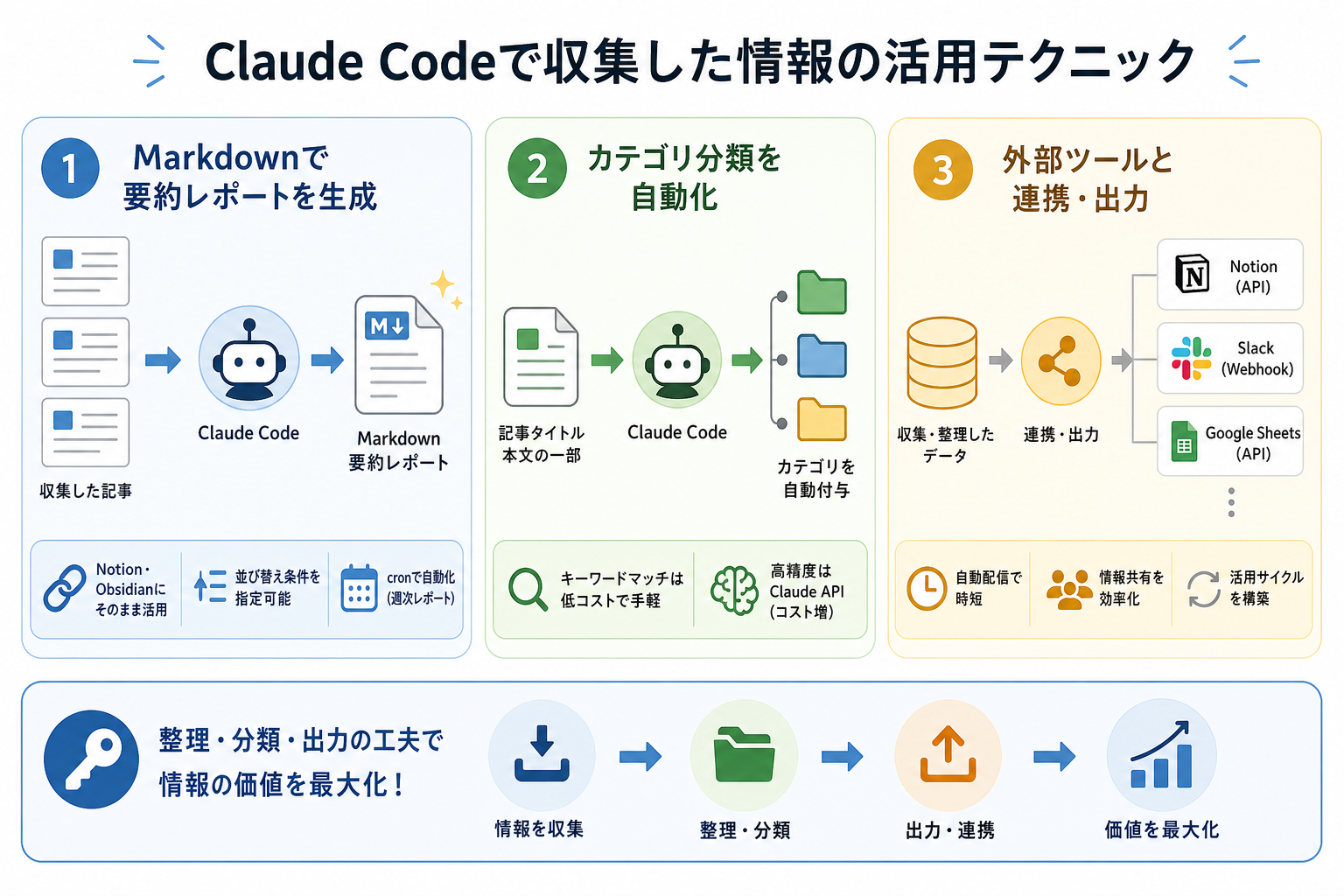
収集したデータをそのまま保存しておくだけでは、情報の価値を十分に引き出せません。収集後の整理・分類・出力の工夫が、情報収集を本当の意味で役立てるカギです。
ここからはClaude Codeで収集した情報の活用テクニックを、3つにまとめて解説します。
Markdown形式で要約レポートを生成する
Markdown形式で要約レポートを生成することで、収集した情報を活用しやすくなります。
Markdownで出力しておくと、NotionやObsidianへの貼り付けがそのまま使えます。
さらに「タイトルに『生成AI』が含まれる記事を先頭にまとめ、それ以外を後ろにする」のような並び替え条件を追加することも可能です。
Claude Codeへの指示例は、次のとおりです。
“`
以下のJSON形式の記事リストを読み込み、
各記事のタイトル・URL・3行要約をMarkdownの箇条書きで出力するスクリプトを書いてください。
要約は日本語で、中学生でもわかる言葉に言い換えてください。
“`
週次レポートとして毎週月曜日に自動生成されるよう、cronと組み合わせて設定しておくと、情報共有の手間が大幅に減ります。
カテゴリ分類を自動化する
収集した情報のカテゴリ分類を自動化すると、スムーズに情報を活用できます。
収集量が多くなると、記事を手動でカテゴリ分けする作業がボトルネックになります。Claude Codeを使えば、記事タイトルと本文の一部を元に、カテゴリを自動で付与するスクリプトを生成できます。
“`
Pythonで以下の処理を行うスクリプトを書いてください。
1.JSONファイルから記事リストを読み込む
2.各記事のタイトルに対し、次のカテゴリから最も近いものを1つ割り当てる
カテゴリ:「AI」「マーケティング」「ファイナンス」「テクノロジー」「その他」
カテゴリを付加した記事リストをJSONで上書き保存する
“`
キーワードマッチによる分類は実装が軽く、API費用がかからないのがメリットです。
より精度の高い分類が必要な場合は、Anthropic APIを使って記事本文をClaude APIに渡し、カテゴリ分類を依頼する方法も有効です。ただし、記事数が多いと都度APIを呼び出すためトークン消費量が増加します。100件程度であればコストは数十円程度に収まります。
外部のツールと連携・出力する
収集・整理したデータを、すでに使っているツールへ自動出力する仕組みを作ると、情報の活用サイクルが完成します。
手動で収集したデータや資料を送信するのは手間がかかります。Claude Codeでメールやチャットツールへの送信まで自動化できる仕組みを作ることで、スムーズに情報を活用できます。
主な連携先と手段は、次のとおりです。
| 連携先 | 連携方法 | 用途 |
|---|---|---|
| Notion | Notion API | データベースへの記事自動追記 |
| Slack | Webhook URL | 毎朝のニュース要約を自動投稿 |
| Google Sheets | gspreadライブラリ | CSV代わりのデータ蓄積 |
| メール | smtplibライブラリ | 日次レポートの自動送信 |
Slackへの自動投稿は、チームへの情報共有をゼロコストで仕組み化できる点でとくにおすすめです。
Claude Codeへの指示例は、次のとおりです。
“`
PythonでSlackのIncoming Webhookを使い、
Markdown形式の記事リストをSlackチャンネルへ投稿するスクリプトを書いてください。
Webhook URLは環境変数「SLACK_WEBHOOK_URL」から読み込んでください。
“`
Webhook URLをコードに直接書くと、セキュリティリスクがあります。環境変数を使う形で指示するのがポイント。Claude Codeはセキュリティ面も考慮した実装を提案してくれるため、情報共有のリスクを減らせます。
まとめ
今回は、Claude Codeを使った情報収集の自動化について解説しました。
頻繁に情報収集を行う人や、毎回集める情報の種類が同じ場合はClaude Codeで作業を自動化するメリットが多いです。作業時間だけでなく、人員も削減できるため、積極的に活用するのがおすすめです。
まずは収集情報の種類や頻度を決めてから、活用をスタートしてください。


